
从自然语言处理到位置分析--给位置贴上商业标签

如何找出任何一个区域合适的商业属性是一个看起来挺简单,实际上挺有挑战的一个事。
所谓的“合适的商业属性”,是想用一个或者几个简单的词,来最贴切的描述一块区域的特点,比如北京王府井大致等于购物+外地旅游+步行街,又有常常被认为是中国硅谷的中关村,也可以用科技企业+高等教育来简单概括。这些地块区域,既可能是一个城市商圈,也可能是一个购物商场,一条普通街道,很可能没有一个边界来划定它们,那就更没有既定的指标来评价,或者描述它们。
想要找到一块地的贴切描述,靠人的经验来推断肯定是不客观也难以完成的。好在尚有一些规律可循,无论是王府井的购物,旅游,还是中关村的科技企业,高教,这些地域标签都可以从归纳这片区域的poi的类型和数量得到。那么需要我们做的就是找办法从全部的poi信息中提取出最合适标签。但是单纯的统计各类poi的数量过于简单粗暴,能包含的内容很少。
自然语言处理技术能不能帮我们回答这个问题呢?作为人工智能两大研究热点之一,自然语言处理技术和图像处理一样,得益于机器学习的迅猛发展,已经可以解决相当多的和语言相关的问题。从自然语言处理技术中寻找方法解决我们的问题,看起来是个不错的思路。
经常阅读资讯类app或者网站的人可能会注意到,文章常常伴随着几个精简的词作为标签贴在文章后面,方便大家阅读相似类型的文章。可想而知的是,文章肯定不是被简单归类到某一类的类型之中,而是存在着一对多(一篇文章多的标签)的关系。这样的情形就和我们遇到的问题十分相似了。如果文章可以从词语中提取出标签,那么区域也就能从poi里找到答案,这项用于文章标签/文章主题的文本分析技术就是主题模型(topic model)。
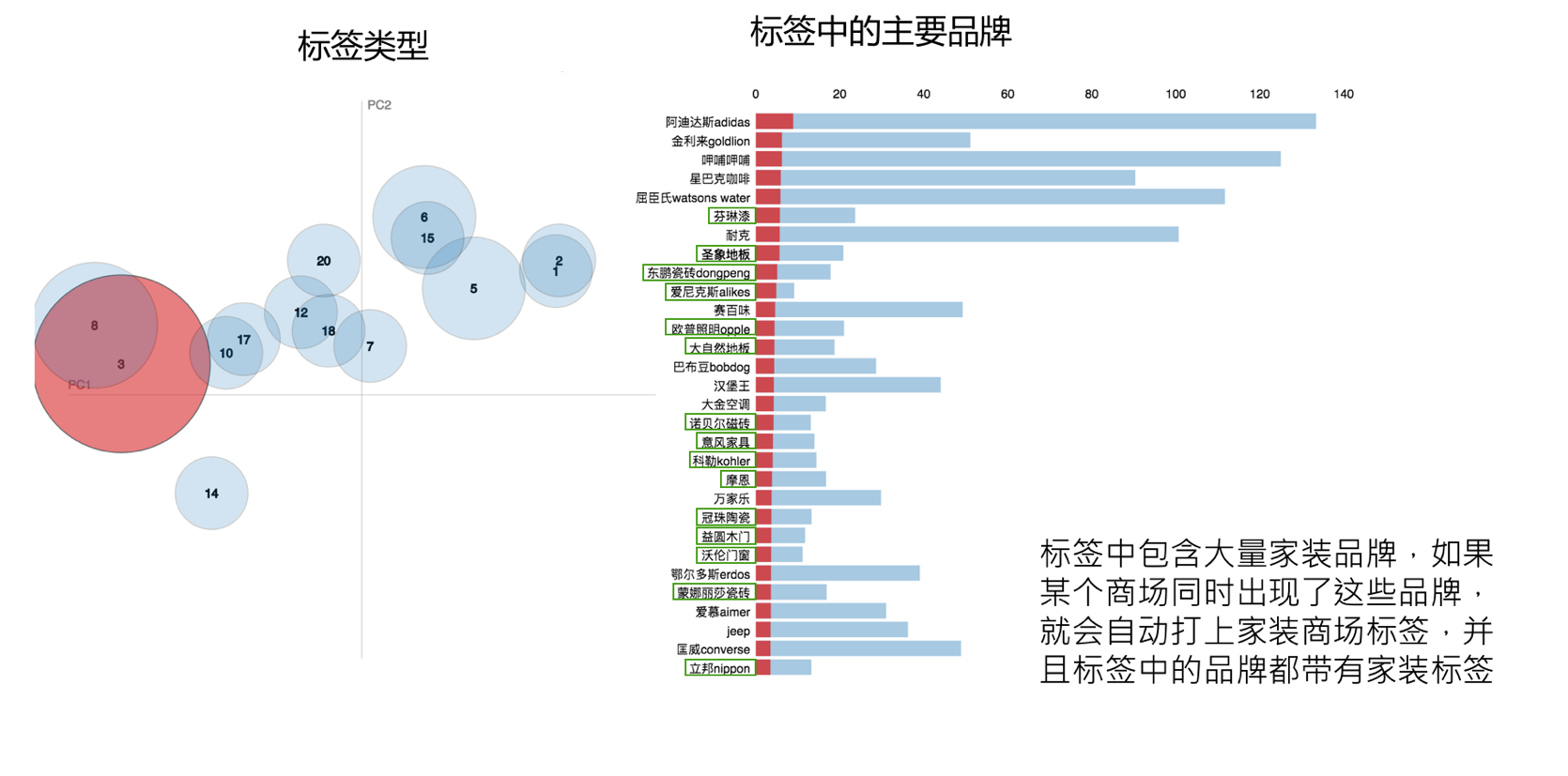
主题模型关注的问题是,从相当多的文章中学习训练,提炼出合适的主题表示/标签(词汇分布),用提炼到的标签标记新见到的文章。我们将一块区域当做是人们一起写成的一篇关于地理特征的“文章”,这片文章的词汇就是各种有品牌名称的poi,把各个区域组合一遍,就得到很多篇可以用来当做主题模型训练数据的素材,应用主题模型自然而然也就提炼出我们需要的地理属性标签了。
分析过程一点也不复杂,这样的好处是让我们获取的标签更具有可解释性,不像其他一些机器学习模型难以应对客户追根究底的诘问。但是,面对这样的问题并不是人人都有能力去解决,因为问题的难点落在了数据的准确性,只有让众多的品牌对应到正确的品牌名称下,分析的种种条件才能得到满足,要得到这些规整好品牌的数据,谈何容易,极海在数据准确性上下了很大功夫才满足这样的分析要求(生产了包含数万个品牌的poi数据库)。关于给区域贴上合适的属性标签,自然语言处理技术中还有其他方法可以利用,比如词向量,好好地利用机器学习的研究工作能带给我们更多好成果。