
PostgreSQL中相似区域筛选
比较两个区域是否相似或找出某个区域有哪些近似区域,可以通过计算和比较区域中的多种属性来完成,这些属性来自对区域的某些特征的提取,这些属性有:小学数量、中学数量、商场数量、公交站数量、超市数量、便利店数量、二手房均价等等,通过这些属性就可以利用PostgreSQL数据库中的cube扩展来完成相似区域的筛选。
PostgreSQL数据库中的cube扩展,实现了一种数据类型,这个类型名称叫cube,用来表示多维立方体,其维度限制是100,此维度限制代入上述情景,就是可以使用最多100个从区域中提取的属性来进行相似区域的筛选。因为,PostgreSQL数据库中cube类型有三种计算距离的操作符,若将区域中提取的多个属性创建为cube类型,则通过计算cube之间的距离,就可以找到一个区域有哪些近似区域。
本文中的区域采用的是极海自主研发的自然街区,它将城市依据道路、铁路、河流等对人步行造成阻碍的边界进行划分,从而以粒度更细的街道为单元,对人、地、物多维度基础数据进行统计。与以方格为统计单元的传统数据相比,自然街区更加符合人类认知与实际情况,具有更强的使用价值。详情请浏览http://geohey.com/site/block
以下为PostgreSQL中相似区域筛选的大致过程
1、创建扩展
create extension cube;
2、为区域创建cube
本文选择自然街区中二手房均价、居住人口密度、15分钟生活圈-交通得分、15分钟生活圈-教育得分这四个维度来为区域创建cube,结果如图一。
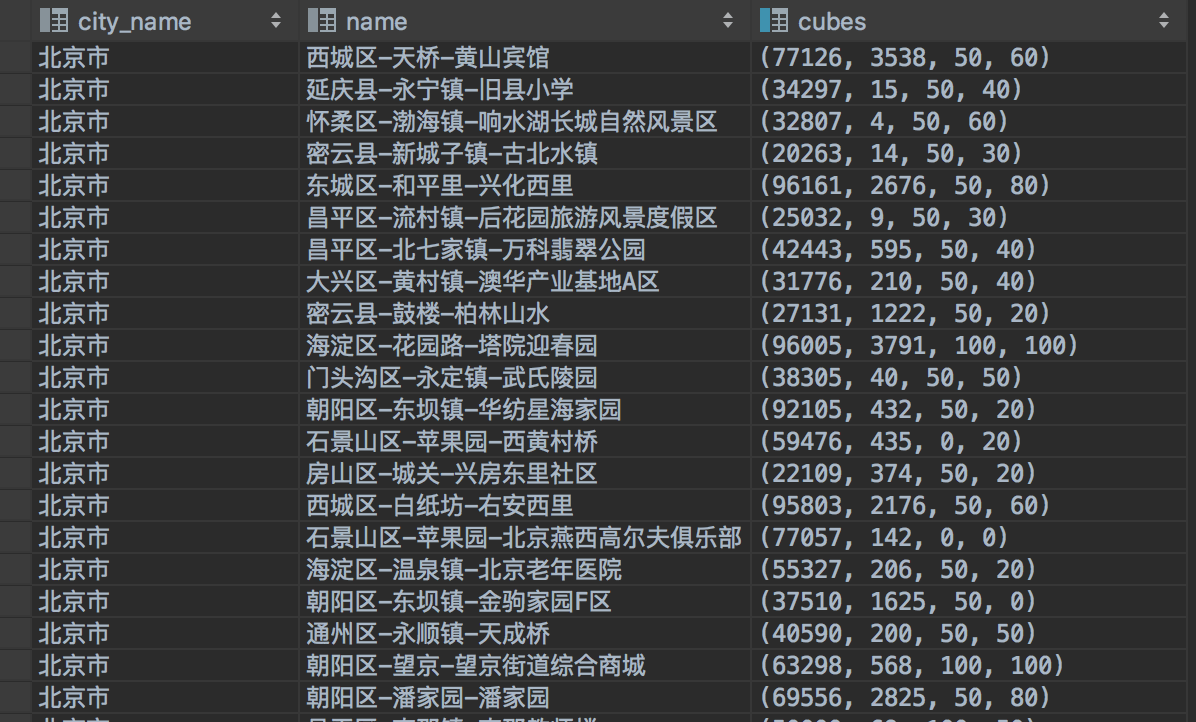
图一、为自然街区创建cube(cubes列的值从左至右依次是四个维度的统计值)
3、计算一个自然街区相似的5个自然街区
PostgreSQL数据库中的cube类型列创建GiST索引后可以在ORDER BY子句中通过度量操作符<->、<#>和<=>来查找最近邻。那么,选取一个自然街区,其二手房均价、居住人口密度、15分钟生活圈-交通得分、15分钟生活圈-教育得分构成的cube值为[104596, 1616, 100, 50],使用度量操作符<->,可以得到这个目标自然街区最相似的5个自然街区,其SQL查询结果如图二所示,地图展示结果如图三所示。
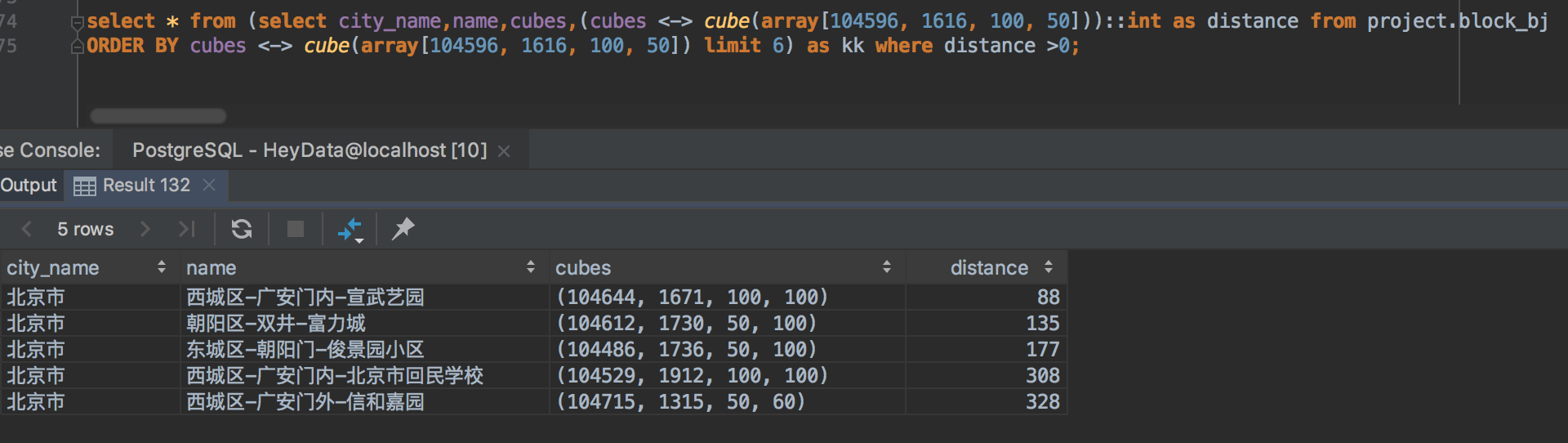
图二、SQL查询,一个自然街区最相似的5个自然街区。
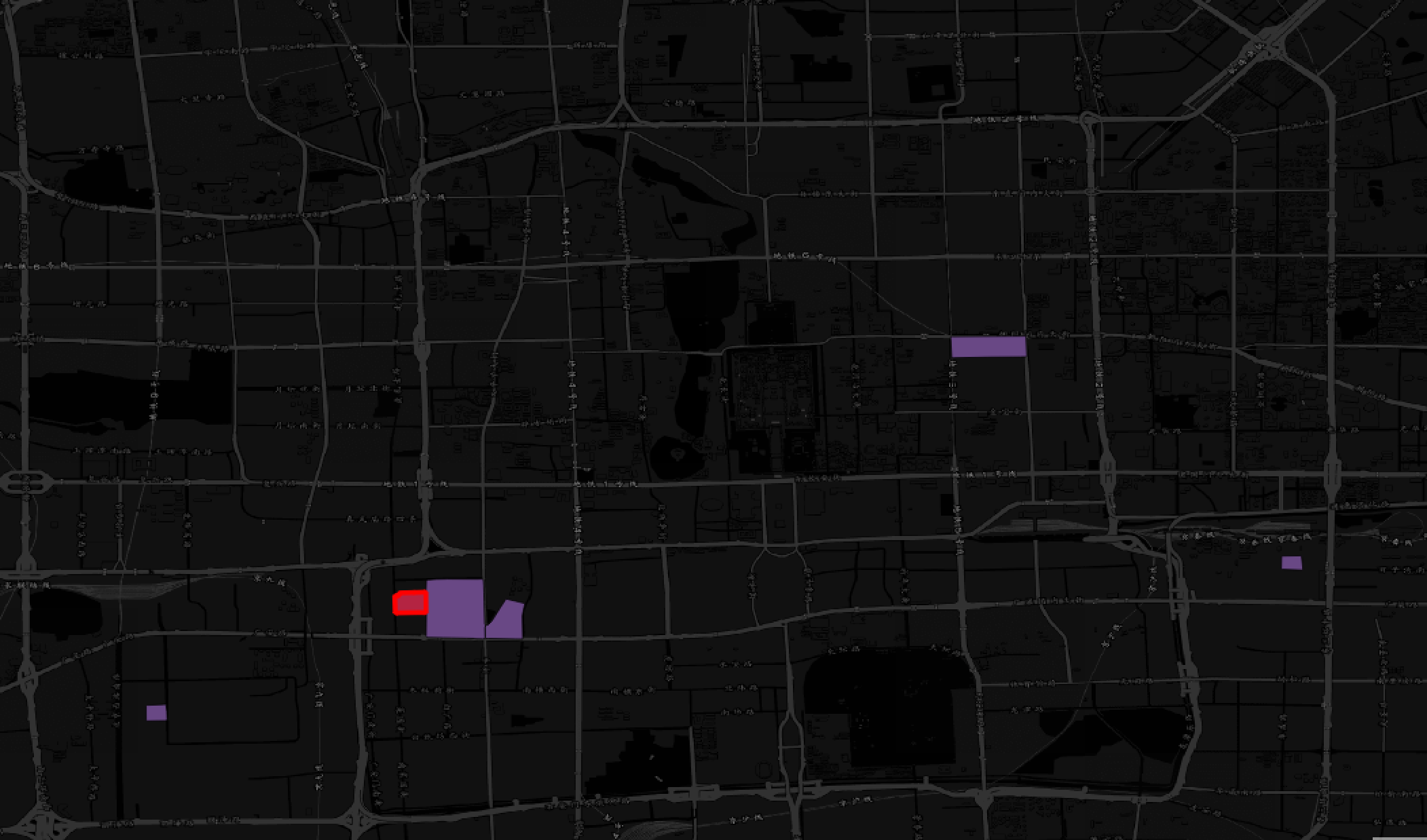
图三、地图展示,一个自然街区最相似的5个自然街区(红框为选取的目标自然街区,剩余紫色区域是与其最相似的5个自然街区)。
总结
PostgreSQL数据库中的cube扩展能综合多个维度的特征值,通过其度量操作符<->、<#>和<=>可以用来查找最近邻区域,而极海自然街区数据中每个街区都统计了多个维度的特征值,综合考虑这些特征值,利用PostgreSQL数据库中的cube扩展,可以在PostgreSQL数据库中实现相似区域筛选。