
AI时代证券分析师更需要数据思维
要说中国餐饮连锁门店数量最多的品牌(有严格连锁授权管理规范的)是哪家?即便是一个经常出差、每日在城市中穿梭的忙碌工作者还真不一定能答的出来。是肯德基、瑞幸、还是沙县小吃?但作为一名关注零售行业的证券分析师,我认为90%的概率能回答正确。
创立于1997年的蜜雪冰城,自2020年初,开始全国遍地开花,从5000家门店的规模,快速增长四倍,现在已经接近25000家。在奶茶这个竞争白热化的赛道中,就算有是一轮一轮的网红品牌反复冲击,一家又一家新入围者跑马圈地,但蜜雪冰城的这个扩张速度及规模也是中国餐饮之最。

而且更让人惊异的是,蜜雪冰城的战场,在四个一线城市里,只有广州算得上与之经济、人口可比配的门店数量。甚至在北京,还有很多人都没有看到过蜜雪冰城的店,更别说喝过了。这不仅让人好奇,是不是蜜雪冰城还有巨大的增长潜力。一线城市如果能和郑州一样的密度,那未来的空间是不是可以大大的遐想一番?
对于蜜雪冰城的规模上限如何测算,为什么主打下沉市场,极海的产品总监王龙已经有两(①和②)篇文章详细论述过。在王龙的分析逻辑中,最重要的环节就是:
1、用回归找到与门店数量决定系数最大的相关因子;

2、用3个月低于5%的开店速度挑选饱和城市;

3、对于已经开出“过饱和”密度的城市给予乐观估计。
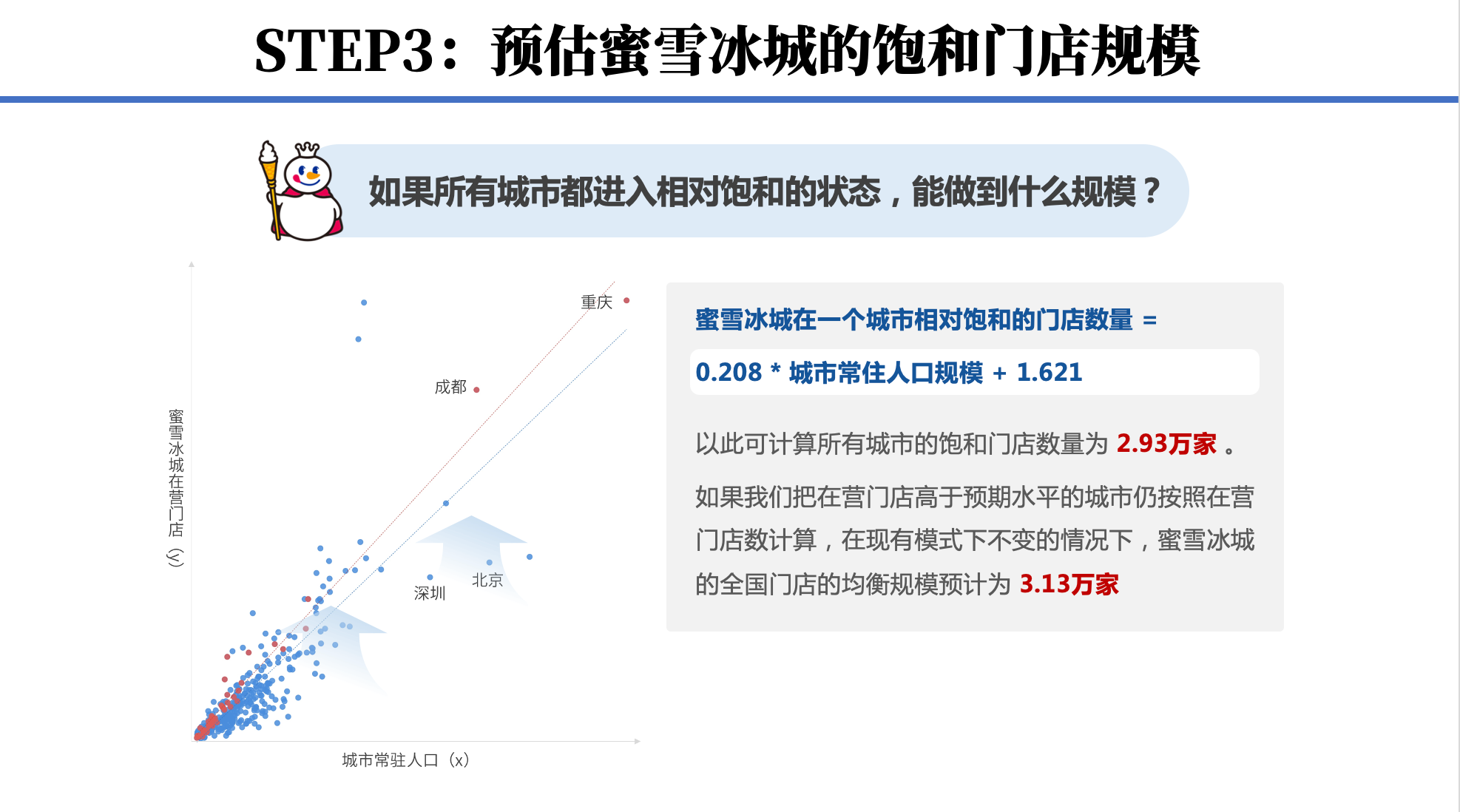
这套逻辑简单而易懂,而且回归分析也是Excel的标准功能,数据准备好拖拉两下,结果秒出,R²这样的统计学参数根本不需要自己计算。因此对于证券分析师来说,所需要的就是一套数据分析的基本框架和思维。至于数据,有像极海这样的专业数据提供商做好采集和清洗。在所有的券商零售赛道投资报告中都会测算市场容量、品牌规模和增长态势。通常来说,单店的收入利润指标能够在年报季报中查出,而连锁品牌的整体财务预测几乎就要看其门店数量了,而能否先于其他分析师做出更高质量更及时的预测,就看对门店数量的追踪效率了。
当然,现在有了ChatGPT的加持,普通大众也可以问问ChatGPT的“判断”。ChatGPT现在是羞于回答这类商业上的预测问题的,也许觉得这种一本正经的胡说八道越来越多的被诟病吧。但playground和用API调用的达芬奇3引擎仍然乐此不疲的乱讲。
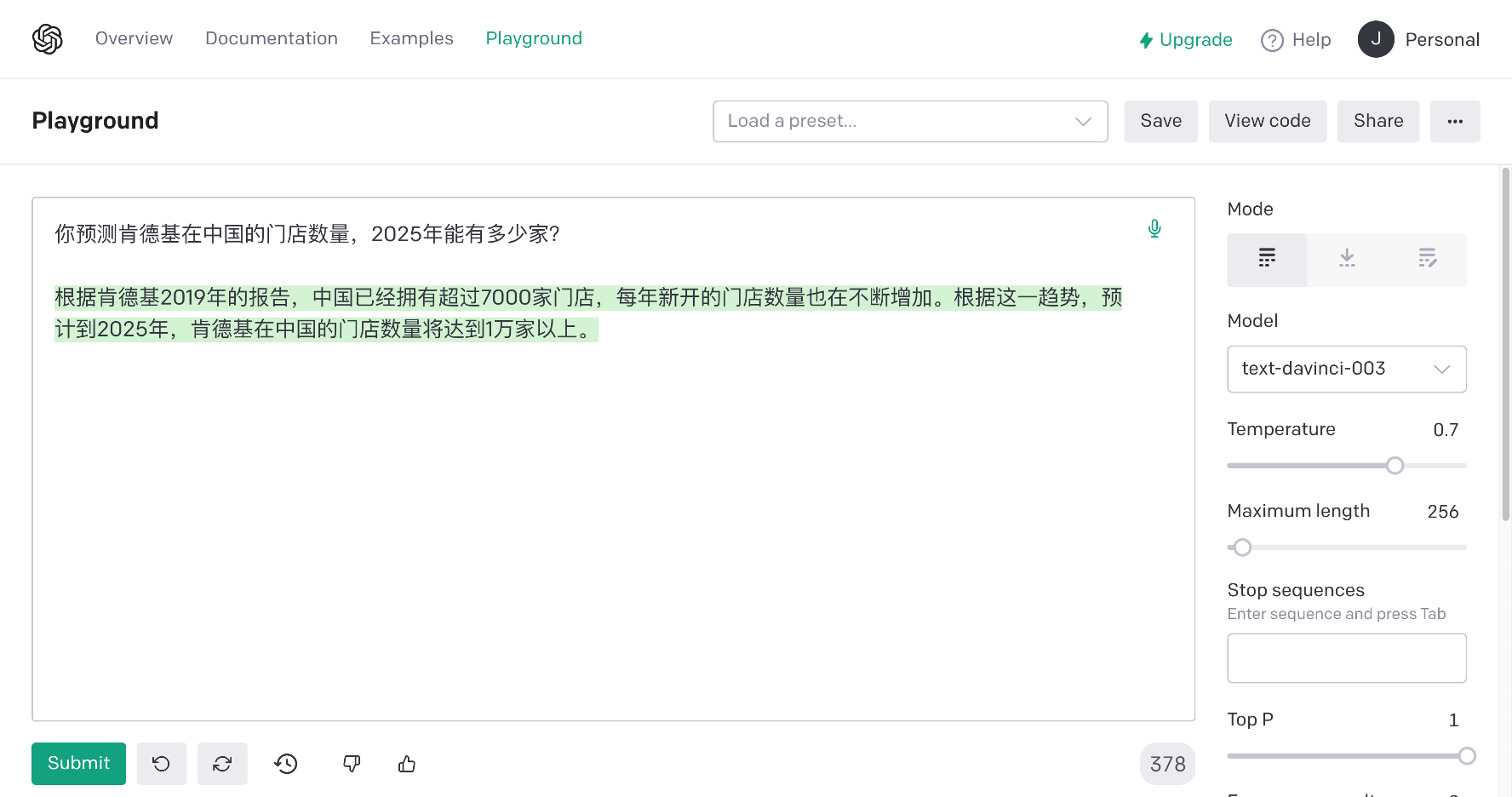
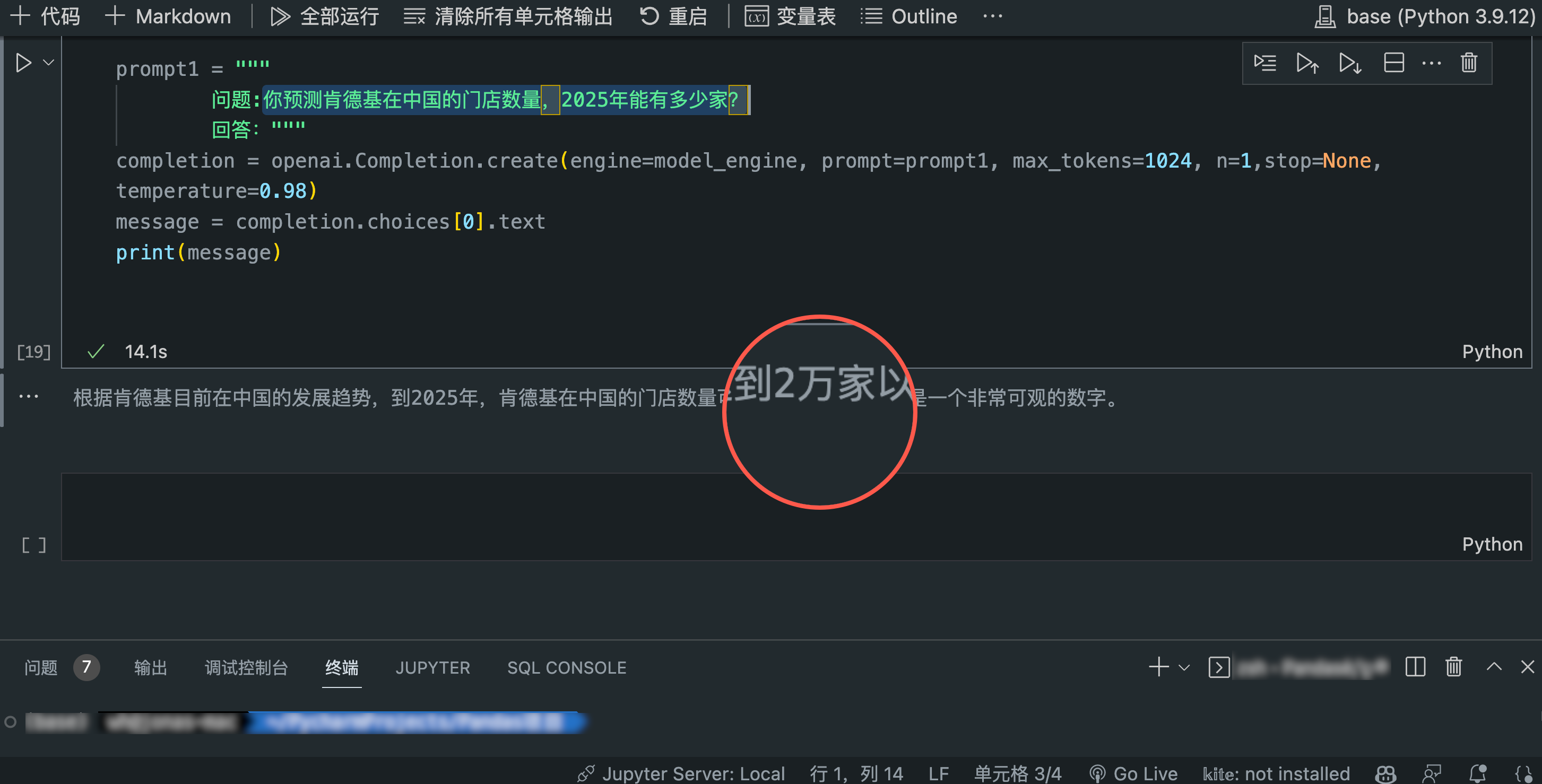
我尝试了多次,最严谨的回答,也是最正确的废话:
很难准确地预测肯德基在中国2025年门店的数量,因为未来商业市场环境以及肯德基经营策略都是变化的。可以看看肯德基过去几年在中国的发展情况,并根据当前的市场趋势预测未来可能的门店增长趋势。
如果不是有认真的测算逻辑,还不如看一看曾经踏遍全世界的那些连锁品牌走过的路线图。即便就是一个普通的类比,地图可视化也有更实际的启发。有人的地方、有钱的地方,线下的消费永远都有想象空间。
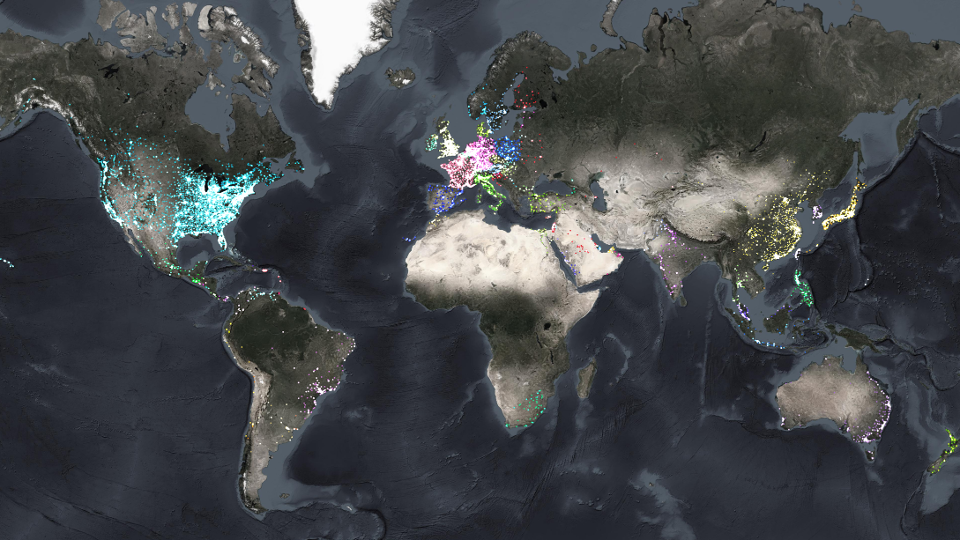


随着数据的丰富,ChatGPT带来又一波的AI创新潮流,以人工智能为基础的数据分析,尤其是数据预测,很大可能比现有的简单预测模式强大的多。我们作为数据的创业者,自然是积极尝试AI的模型与自身数据的紧密结合,能为专业分析师们带来哪些更大的效率提升。作为与很多行业报告编纂者有类似危机感的证券分析师们,武装自己跟上潮流,更加需要数据思维。今晚,就是颠覆式经济新模式开启的前夜。
