
极海数据分析(上):机器在做什么
——如果机器说,能帮人类准确地预测市场,预测价格,却无法告诉我们为什么。我们敢相信吗?
深度学习 是当下数据科学界最火的话题。从这个发展了短短几年的领域,已经诞生出能击败李世石的 AlphaGo,和能在路况最复杂的匹兹堡安全行驶的 无人车。要训练机器完成这样需要人类智能水平的任务,即使在二十一世纪初,都还属于科幻片的范畴。

(图:Nature杂志)
然而,在大众眼中的光环之外,许多的数据科学家、研究人员直至今日都对深度学习持保留态度。
要说为什么?其实原因很简单。你告诉我计算器进行加减乘除的 原理,我就能相信你的计算是正确的。你告诉我国际象棋的程序之所以可行,是因为它的可能性在可算的数量级,料敌先机战胜人类对手,我也能相信。但围棋这个尽展人类智慧的游戏,你没法手把手“教”给机器怎样去赢得最好的人类棋手,但你声称机器能通过海量学习来做到,即使连设计学习程序和样本的你都无法理解它是如何做到的。这该让我如何信服?
我们在最近的项目中,就遇到了这样一个问题。
我们对一家商店的 会员数分布 建立预测模型的时候,传统上的做法是,将很多的影响因子加入这个模型,经过调试最终得到哪些是重要的因子、每个因子对会员分布有怎样的影响,就像一个由很多x组合决定y的方程。
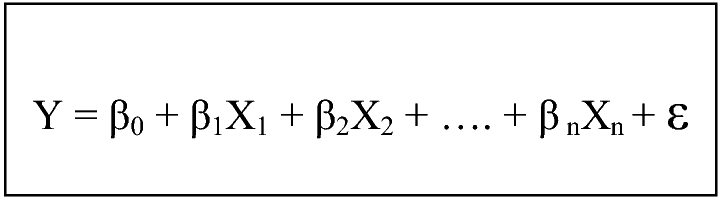
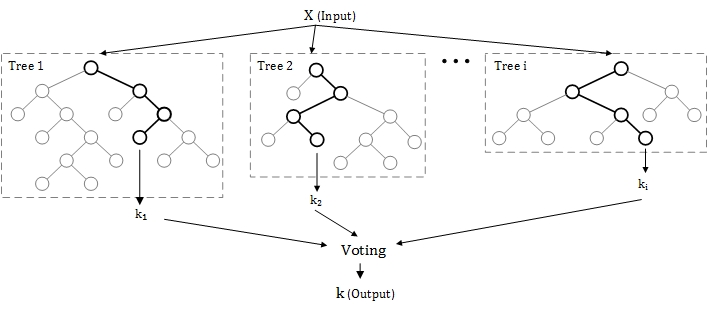
对于大多传统的数据科学家来说,这样的做法能让他完全把握模型,通过经验判断来手动控制模型,每一步都可循,是非常重要的。甚至在机器学习(Machine Learning)的时代到来后,他们也逐渐接受了让机器来优化算法,毕竟机器学习的核心也是用线性回归和逻辑回归来拟合数据,他们能够形象地理解为什么决策树是有用的,Random Forest和Radiant Boost也能告诉他们到底哪些x因子对他们要预测的y是重要的,即使不再能用单一的方程来表达。
然而到了深度学习,就忽然变成了另一个故事。直到现在,理论学家们也无法解释,为什么增加了神经网络的深度(层数)之后,能达到这么惊人的效果,能让AlphaGo在围棋上战胜人类。这决不像表面一样,是简单地把机器学习进行了升级,而是完全变成了另一个东西,一个我们还无法解释的东西。
同理,当我们做图像识别的时候,无论用多少的传统方法——因子分析、主成分分析、聚类分析,甚至引入传统的(即:我们能理解的)机器学习方法,都远远不能达到深度学习的效果。就像机器不能理解人脑的运转一样,忽然间,我们也不能理解机器的运转了。
然而,这并没能阻止研究者的脚步。即使在传统的数据科学家的一片观望中,互联网科技巨头们依然在坚定地将深度学习作为科技的明天,不惜成本地推进这个领域的研究。而我们的团队,也一直在跟进,将深度学习的方法引入我们的产品和项目中——无论对我们还是对客户,最重要的是结果。也许人工智能会越来越超出我们认知的范畴,最终代替人类统治世界,这我们暂时关心不到;至少在今天,我们想让它告诉我们最准确的价格是什么,最合理的选址是什么。
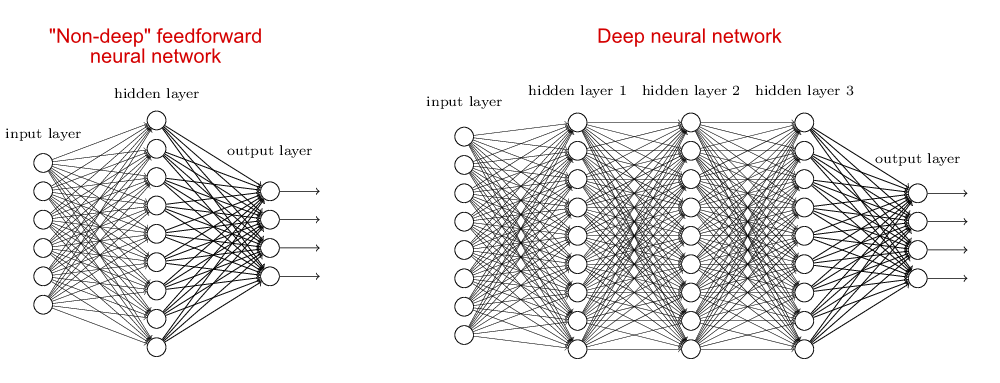
(图:Michael A. Nielsen)
回到商店的会员数预测。我们有几百类的POI因子x,都可能和会员分布y有关;如果按照传统方法,我们要做的就是把它们降到尽量少的数量,最终,认为说10个因子x’(每个x’有可能是将一些x变形组合的结果)解释了y的大部分变化。此处我们要尽量消除因子之间的关联性,我们要考查因子的分布是否正态,我们要避免过度拟合……通过一系列的条件来保证模型的可靠性。
而到了深度学习?因子数量太多,没有关系,甚至越多越好;这会不可避免地导致过度拟合,然而也不用担心,多了这几层神经网络之后,深度学习(无法解释地)不再像传统机器学习一样受限于这些了。
最终,我们决定帮客户同时做两个模型,来描述会员的分布:(1)深度学习模型,我们会证实预测结果的准确性,即使我们无法解释机器的智能是如何做到这一步的;(2)传统模型,我们可以得出一个影响因子Top 10列表,让客户从直观上对什么因素影响了会员分布有一个认知。

我们认为这两个模型都很重要。
就好像当我们想通过基因预测一个小孩长大后的身高时,我们可以建一个复杂的深度学习的模型,其中包含海量基因信息;只要最终预测结果是准确的,我们可以接受模型有一定的模糊性。而与此同时,我们也会想知道,小孩长大后的身高到底跟哪些因素有最大的关联?于是我们单独建模来解释这件事情。
在数据分析的未来,这两条线也许会越走越远——机器会继续变聪明,模型预测会更加准确,过程也会让我们人类更难理解;另一方面,同样在机器的帮助下,我们提取直观信息的技术也会发展,解读会更加清晰。
那么,在机器似乎包揽了大部分工作的今天,作为数据分析师的我们在做些什么?
请继续阅读—— 极海数据分析(下):我们在做什么