
关于数据平台,了解这三步,你也很专业
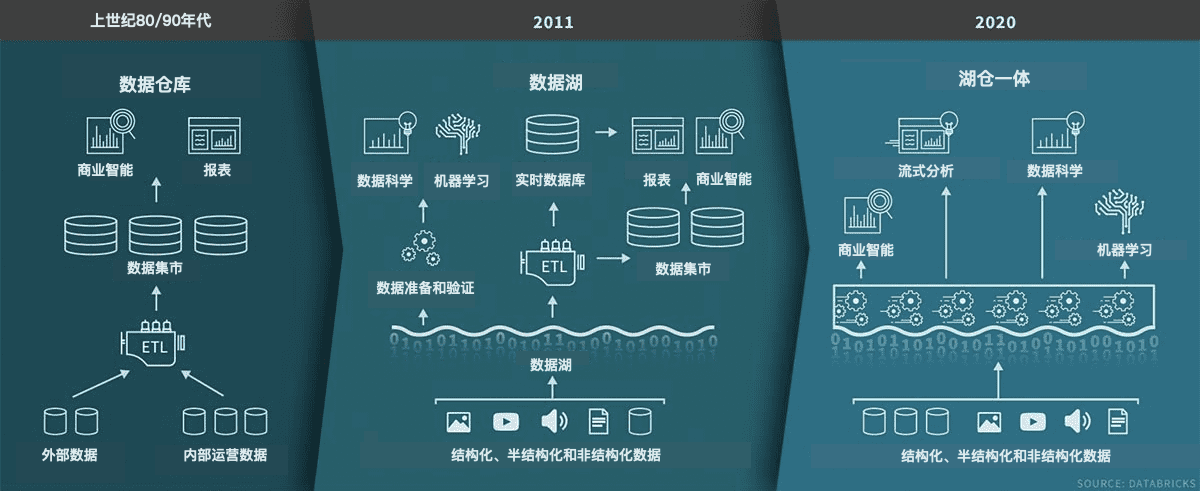
最近在一次数据系统架构的交流中,体会了现代数据系统的复杂性。虽然说数仓是上世纪的技术,但到了2021年、言必说“云”的今天,我们在数据系统中也没有说就淘汰了数据仓库。再加上已经快有10年寿命的数据湖,到如今的湖仓一体,真可谓“三浪叠加”。
在交流的会议中,除了我在座的都是数据专家。云专家偏向于将所有的数据及数据处理、挖掘、分析系统置于云基础设施内,业务专家侧重于具体业务中数据分析的可定制性。排除几位专家心中隐藏的经济学动机,大家的说法其实都非常有道理。好在参与辩论的专家们都是儒雅的,儒雅是有学问的坚定而温柔。辩论的空气中弥漫的是上好西楚啤酒花的柑橘香气,但架构定下来后,入口的感觉对客户来说可能是苦涩的。
我也想装个专家的样子。只好在会议结束,连夜开始学习。我发现,如果纠结于云基础设施够不够用、好不好用,那无论如何也没法达成共识。就和这世间常态一样,讲道理还真就没法辨别个对错。讲经济账,可能还更容易达成共识。大家争论的核心,归根结底是数据到底集中到一个什么程度,才是对用户整体效益最大。
一、三浪叠加的数据平台“浪”不起来
我们从处在三浪叠加的数据平台的概念走起。数据平台是将数据聚集在一起并为整个组织提供服务的环境。数据仓库是第一代企业级中央数据技术。然而,随着各种数据格式和数据源(尤其是非结构化和流式数据)的喷涌而出,数仓的灵活性大受诟病。数据湖的引入可以方便的存储任何格式、任何来源的原始数据。有了数据湖,最有效率的一点是,数据在实际使用时才需要建立数据概要(schema)和数据解释,而在这之前,数据库中的schema都需要预先建立好,在我们地理信息领域,更是如此(曾经,每个ArcGIS工程师都需要熟练掌握GDB的schema创建)。
但在实际工作中,数据湖经常变成所谓的“数据沼泽”,在其中没法真正有效的使用数据。看似在湖中添加了所有数据,但数据却没有被很好的准备——数据工程师们都特别能体会数据准备(preparing和blending)的巨大工作量——使得数据得以顺畅的使用。数据湖的继任者是湖仓一体(Lakehouse),数据湖与数据库工具相结合,方便的创建可用的数据视图。
二、老董的数据乌托邦
从数仓到湖仓一体,先不提到底哪种先进,哪种实用,我们要明白数据平台的目的是什么。最理想的状态是数据平台使得所有的部门没有摩擦的获取数据,并且能在数据平台上做一切数据操作。数据科学家都可以随时获得他们需要的数据。可以专注于用平台上提供的jupyter Notebook环境进行高级机器学习,而数据工程师的职责是确保数据随时可用。这是一个数据乌托邦的社会。
我们来认识一下老董——我们的数据专家。从他的工作来体验这个社会。他正在开发一个新的数据科学产品:基于地理位置的门店收入预测。所有关于客户、产品、销售、对等店、门店周边商圈POI、人流的数据都可以在中央数据平台中获得。老董在平台中构建了完整的样本数据集,并将其加载到他的jupiter Lab环境中。在对模型的目标与业务进行了一些调整之后,他快速开发了模型的第一个版本。
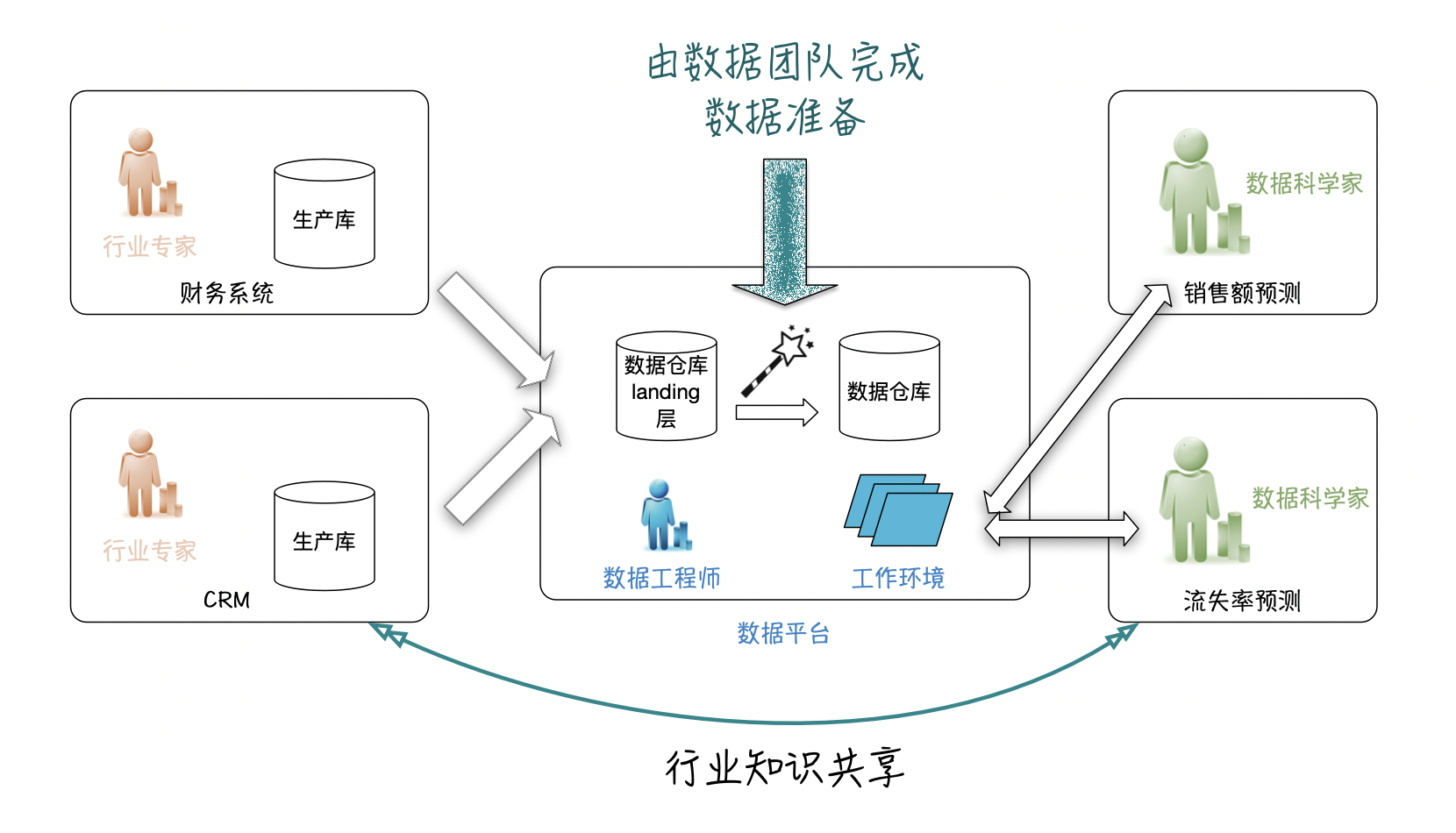
该平台提供了科学家开发模型所需的一切,包括数据、计算和工作环境。平台开发人员(云和数据工程师)的工作是确保它是可伸缩的、实时的和高性能的。平台还能提供其它服务,如数据沿袭(data-lineage)、数据治理和元数据。科学家们得到了充分的授权,Ta们得以摆脱工程上的困难,不必操心数据的流入流出,存储和各种数据上的物理维护。
在上图的左侧,各个部门使用自己的数据运行其应用程序。在一家零售企业中,除了CRM、财务,还包括许多运行在特定领域团队中的业务系统,这些系统有各自的架构,有自己的数据,这些系统是数据的生产者。数据可以存在于任何可能的存储形式中:Excel文件、各种数据库、CSV文件、Kafka主题、云存储桶,有的我们听都没有听过。
在上图的中间,数据平台团队负责提取数据、转换、并将其加载(ETL)到Ta们运维的数据湖的着陆区(Landing zone)。第一步是做一些标准化的工作,比如日期和数字格式以及列名等方面的处理。还可能包括为历史视图拍摄数据快照。所得到的数据集集合被存储在所谓的“落地(staging)”层。然后将数据合并放置在策享(curated)数据层。策享的目的是主动性的为某些特定重复的流程做好准备,想象这个过程是卢浮宫的向导,Ta知道怎么带着你走一条最佳的参观路线。策享层是包含连贯数据集、唯一标识符和清晰关系的数据存储。我们简单的认为其形态就是DWH(数据仓库)吧。但别忘了,它可以是任何形式的存储,包括大型云数据库(BigQuery)、Hive表、Blob存储(在云上)或Delta Lake开源格式文件。这些策享层的目标是提供一个总体视图,使得所有数据的易于使用。
在上图的右边,数据科学团队使用平台的工作环境和数据集来解决Ta们的数据用例需求。
三、老董的不幸和数据工程师的救赎
这个理想数据社会听起来不错。不幸的是,老董的真实经历略有不同:
老董需要数据平台上提供一些额外的数据集。为了与别的部门接口简单,财务部门会导出一些CSV文件供基本分析。老董发现,预测需要针对产品组合进行,而平台上的数据则是针对单个产品的。经过几次会议后,他终于明白了哪些产品属于哪个组合。产品的收入也是分开记录的,一部分是基础产品,一部分是附加产品。折扣则包含在另一套数据中,因为它们是从总账目中减去的,所以将其归属在哪儿就有点棘手了。还有一个麻烦:三个月前,公司重新命名并合并了一些旧的小众产品。这就有一些困难,丢失了少量数据,他需要设法将旧数据与大多数类似的新产品进行匹配。
那么管理数据平台的数据工程师呢?Ta们的痛苦才刚刚开始:
数据工程师要对各种数据集进行提取、加载和转换。第一步很简单,但是现在需要在数据上创建可用的视图。Ta们需要与各种(可能的)潜在用户(各个部门的数据科学家)交流,以了解哪些转换是重要的。Ta们和老董们一起组织了改进会议。然后Ta们需要再到数据生成部门,以弄清楚数据的实际含义,以及它如何映射到Ta们自己的数据定义中。当数据工程师与老董的数据科学团队紧密配合的时候,发现老董团队显然已经等不及了,自己做了不少数据的准备工作。
简而言之,造成实际工作中不顺当的几个关键问题:
- 数据科学家需要能够自己创建特定数据用例的转换;
- 平台团队需要为Ta们并不直接负责的数据做好准备,以方便Ta们处理潜在的用例;
- 数据平台团队成为数据科学家团队的瓶颈。
为了能够解释和转换与特定用例相关的高度详细的数据,谁都得需要大量的领域知识。每个用例还需要做特定的数据准备。因此,数据工程师只能完成数据科学家需要的部分工作。当数据科学家深入研究商业实例的过程中,老董们获得并实践了大量的领域知识,这使Ta们能够自己准备数据。如下解决方案呼之欲出:
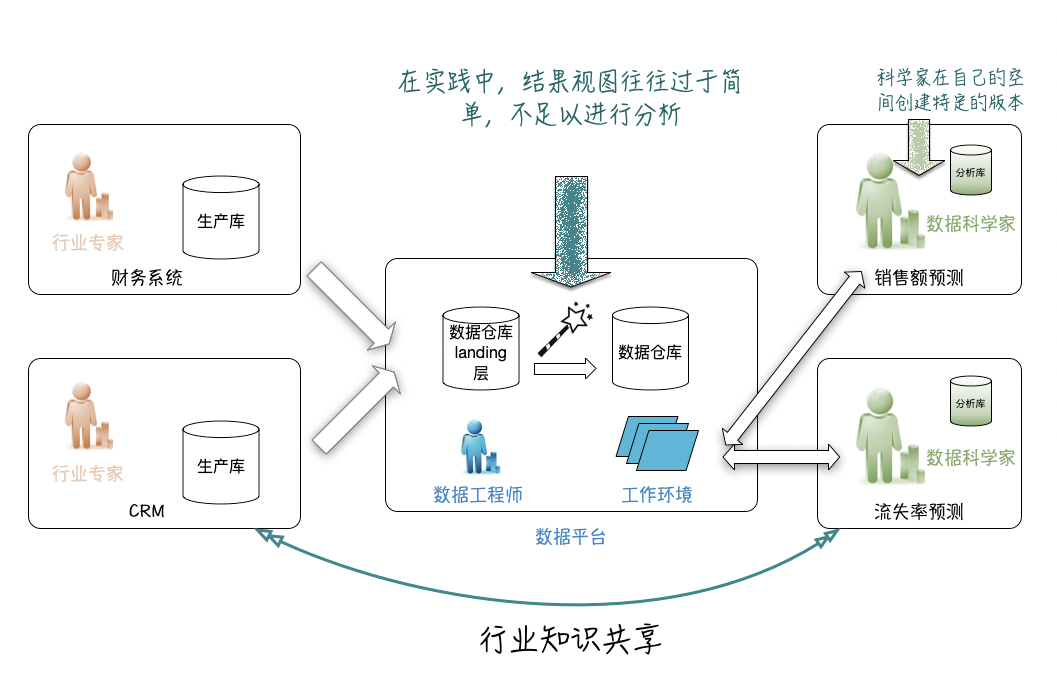
数据科学团队现在转换来自中央数据平台的数据,为Ta们的模型训练做好准备。尽管数据平台在理想情况下提供了完全可用的数据集,但实际上它太简单了,不足以满足所有客户的需求。这个新方案有一些好处:
- 数据科学家可以自给自足;
- 数据工程师不必为组织中的每个人创建视图,Ta们可以专注于数据的标准化接口;
- 数据工程师可专注于使数据保持最新,并提供良好的访问方法。
四、平台团队的新乌托邦
然而,一些事情仍然出了问题:数据科学家的数据集和数据生产部门及数据平台没有相同的标准。数据没有得到很好的监控,对故障没有恢复能力,任务调度也是随心所欲的。随着更加分散的各自为战,多个数据科学团队正在重新发明众所周知的轮子。数据平台团队(比如信息中心)的工程师们看着实在是闹心。
新的理想社会:数据网格。
不久前,数据网格(Data Mesh)的概念出现了:数据来源于组织中的多个位置。数据网格接受数据的去中心化本质,而不是将所有的数据组合在一起形成单一化的表达。既要使数据在组织中的广泛可用,每个团队的数据也要也被视为该团队的产品,更为重要的是每个团队还要负责创建数据的可用视图。按照这样的设计,机器学习产品团队(数据科学家们)也会把转换后的数据作为产品交付给其他数据科学家。大家负责为各自的“暗数据”显性化,这是数据民主化的标志。
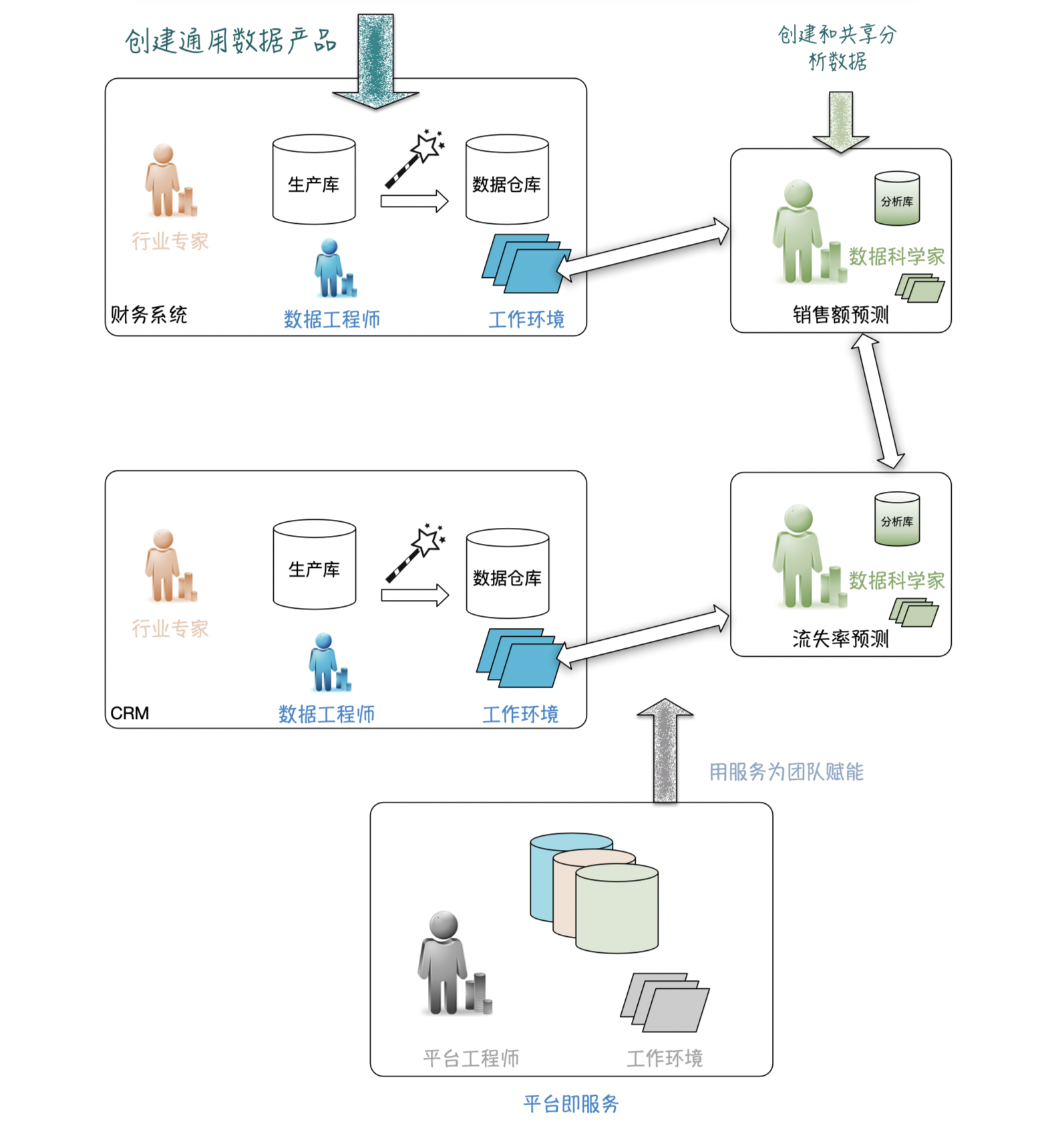
在上图左侧,生产部门或业务团队要将通用数据以服务的形式提供。虽然一组规范化表(DWH)是一种可能,但它也可以包括事件流(Kafka)或Blob存储。这要求产品团队具有更多的数据工程能力。数据工程师现在分散在所有产品团队中,包括分析师甚至机器学习工程师,而不是由所有数据工程师组成的数据中心。
在上图中间,中央数据平台从数据工程师团队(需要行业知识)转变为数据平台服务团队(只需要技术知识)。Ta们开发内部平台,对所有团队为数据存储、特定要素存储、数据处理、数据沿袭、调度、流程监视、模型部件、模型服务实例管理等等进行赋能。因此,所有来自以前的数据平台团队——工程师个人的技术技能都需要转换成工具。这样每个团队都可以拥有自己的(小规模)数据平台。这确保了整个组织的统一工作方式和高标准。
在上图右边,数据科学团队不仅是数据的消费者,也成了数据的生产者。Ta们的特殊工程和数据分析的结果都可以与其他数据科学团队共享。这个模式很多好处:
- 在领域知识所在的地方创建数据转换;
- 消除了数据平台团队的瓶颈;
- 产品团队也自给自足了。
挑战也很明显:
- 怎么建立一个中心平台部门将其严格限定就是做好IT服务;
- 怎么防止新的中心平台(平台即服务)成为IT服务部门新的瓶颈。
在这个模式中,作为服务团队的中央平台起着关键作用。Ta们以一种简单的自助方式设置,提供基础设施和软件服务。因为Ta们将平台作为一种服务来创建,所以这个团队不需要领域特定的知识,只需要关注技术方面,保证其可复制,并将解决方案共享给所有团队。
五、各种形式的乌托邦都是缺陷花园
数据网格方法看似完美解决了数据要重用但领域知识缺乏造成的数据使用困难,这是通过将数据的一系列责任转移到产生和使用该数据的团队来实现的。我们现在需要一个中央团队来帮助所有团队管理Ta们自己的数据,而不是拥有所有数据。但这的理想形态有陷阱:
一个陷阱是采用瀑布方法让这个中心团队成立并运行。不要一开始就设计并创建所有必需的基础设施和服务。只要没有单个团队使用这些服务,就不存在价值。因此,需要迭代地发展和改进服务,直到团队已经可以使用它了。但这一点特别不容易做到,每个部门都想一下子就让人(尤其是)看到自己的强大和价值——走走看吧,这样的说法让人觉得好像胸无大志,也要不来多少经费。
第二个风险是没法让“平台即服务”来决定团队成员的工作方式。也就是说团队的工作是通过工具来赋能而不是工程师个人的现场动手做事的能力。在一些组织的信息中心里,有专门的“GIS专员”负责为业务部门提供(伺候)GIS的操作,而不是用工具去赋能;在另外一些组织中,有的业务部门会强烈希望有新的工具来解决Ta们的数据难题,但因为并非是全体部门的需求,而遭到信息中心的推诿和拒绝。这都将使这个团队成为整个组织的瓶颈。
六、3个步骤,立足当下,朝理想迈进
有没有可能在中央数据平台和数据网格之间找一条中间路线?我们如何务实地迈出第一步?在这里我们能获得尽可能多的好处。下面的部分也许可作为一张参考:如何能够过渡到一个数据平台,实现用平台赋能机器学习,赋能数据科学家,并实现内部内部分享。
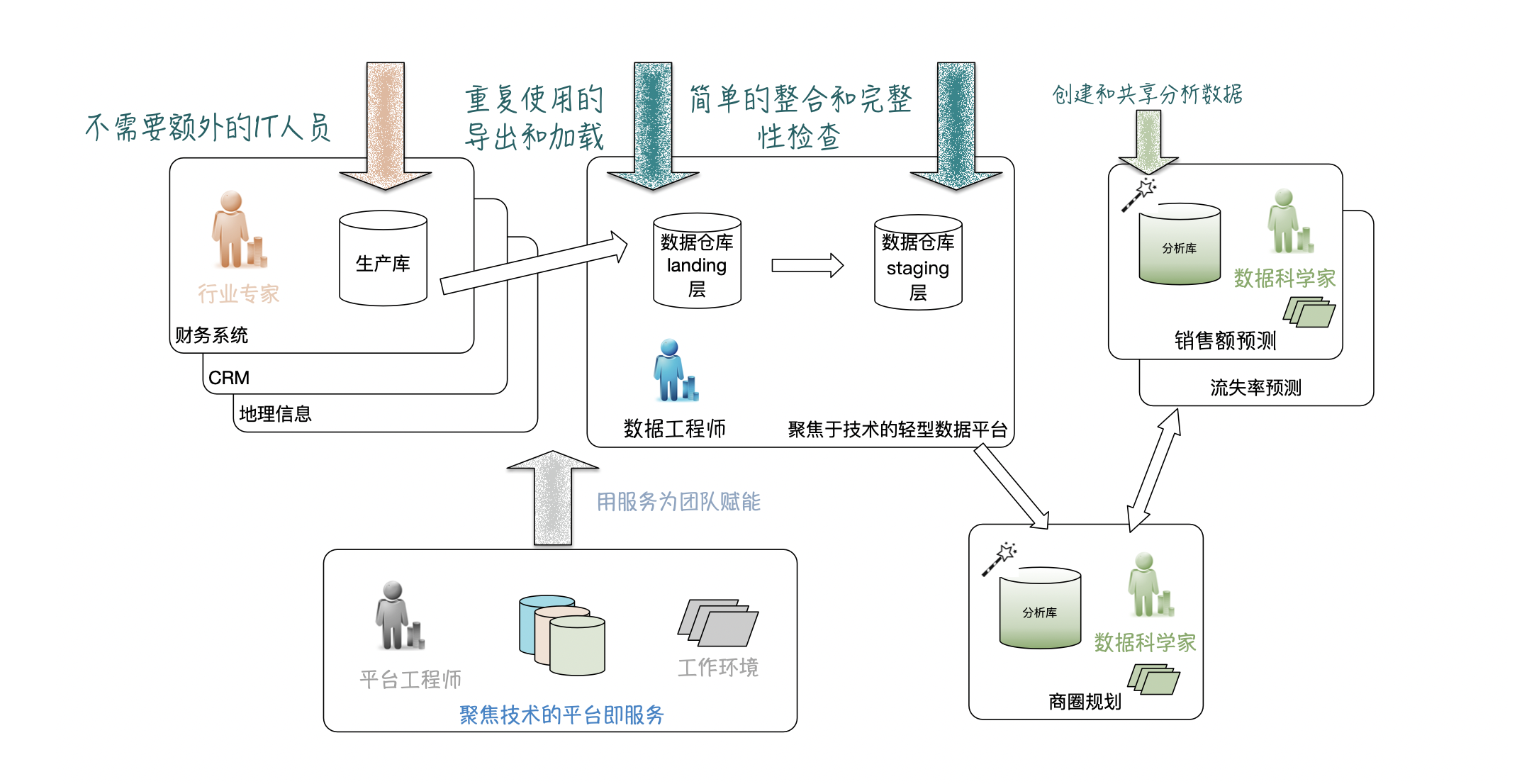
第一步:一个轻量级的中央数据平台创建数据平台的第一步是什么?不幸的是,并没有一个千篇一律的模板,往往都是取决于具体的情况,包括现有的技术栈,可用的技术能力,流程和组织内的DevOps和MLOps成熟度。不过比较容易想到的改进是将组织现有的优势保留,并朝着数据格网的架构使劲:
- 数据工程师专注于提取和加载,只做最小的转换(能不转就不转);
- 而领域特定的(数据科学)团队专注于高级转换;
- 为团队提供可用的工具,工具,还是工具。
该方法是创建一个轻量级的中央数据平台,包括以下步骤:
- 选一个具有特定用例的数据科学团队作为试点;
- 建立一个由平台工程师和数据工程师组成的团队(两个人也行);
- 平台工程师为数据科学团队提供一个分析环境,至少包含存储和计算;
- 数据工程师从源数据表中(业务部门)加载原始数据,做最基础的标准化转换,并将其提供给用例团队。Ta们与平台工程师一起配合创建所需的服务;
- 数据科学家与数据平台工程师合作,在调度、运行和操作Ta们的高级数据转换、模型训练循环和模型服务等方面实现自给自足。Ta们与数据工程师协作,使数据转换专业化。
在这种情况下,数据科学家仍然需要进行大量的数据操作。然而,我们并没有假设这种情况不会发生,而是欣然接受了这种情况,长期迭代努力为Ta们提供完成工作的好工具。这种方法的一个关键方面是从一个试点开始。数据工程师、平台工程师和数据科学家都首先解决这个试点工作中明确定义的问题。由此这个组合将会获得开发必要工具的经验。

在上图左边,保持原来的情况,生产部门或产品团队只是开发或操作Ta们的生产实例。这避免了公司的大变化。
在上图中间,数据工程师专注于如何使用高质量管道实现轻量级数据获取。Ta们主要的工作是加载数据,并提供标准化的访问方法。Ta们非常注重技术,包括基础设施和服务。
在上图右边,数据科学团队专注于基于所有必需的领域知识创建数据产品。Ta们通过向Ta们的客户(使用Ta们数据产品的客户)和上游数据源团队学习来获得领域的知识。团队成员运行所有必需的分析和转换,同时由“平台即服务”团队提供支持。Ta们有很强的领域和用例聚焦特性。
在上图底部,“平台即服务”团队致力于创建可重用组件。因此,Ta们专注于IT技术,为数据科学团队服务,如前文所述这些团队专注于某个领域。作为IT服务的团队,平台的能力应该由用户的需求驱动。
下一步:跨团队扩展和共享。
第一步运行扎实了,下一步才是扩大规模。扩展可以在不同的维度上完成,包括获得更多的源数据集,加入更多的数据科学团队,或添加更多强大的平台功能成为服务(比如功能商店,模型服务……)。同样,这些选择取决于具体情况。
现在,让我们举一个典型例子的步骤:加入更多的数据科学团队。第一个团队的加入确保了开发的服务是有用的。“平台即服务”团队确保了需求的实现,像创业公司一样,用精益开发找到了良好的市场匹配(market fit)。下一个团队应该可以追随前人的脚步,跑得更快更顺利。
随着多个团队使用这些服务,下一个挑战将是允许数据科学团队之间共享数据。这可能需要对服务和工作方式进行一些更改。但如果达到了这一里程碑,平台将真正改善所有后续团队的工作:
不要忘记数据平台计划的目标:实现又快又多又好的数据产品(模型)。因此,除了加入多个数据科学团队外,在生产中利用数据科学团队的模型也很重要。使得最初的(少数)团队将Ta们的模型(销售预测等)嵌入到实际业务(如网络开发)中。有了这些平台、流程和工作方式,下一步就不那么明确了。有很多方法可以提高服务质量和团队协作。可以根据业务需求改进所提供的服务的质量。也许需要一个实时的流数据存储,一个新的模型服务平台,一系列机器学习工具,或者更好的模型监控?
七、我们都能舒缓一下的总结:
本文从数据平台技术的进化看到,目前大数据平台类型的项目架构设计中常见的一些纠结,这也是大家都将普遍遇到的正常纷争:云基础设施的越发强大,就越会强调大集中的效率和标准化优势,而业务部门似乎有无穷无尽、当下却又不可名状特性的需求。在数据分析,尤其是机器学习成为通用技术后的数据建模领域中,这个矛盾尤其突出。文章中最后给出的方法,无非是一些心法的表象:
- 敏捷的以客户(内部的)为中心的方法;
- 平台化思维;
- 消除瓶颈,同时提供一个灵活的平台,增强数据科学团队的能力;
- 团队自给自足,自由自主:各自团队可以使用适合自己的服务,并可以自主准备数据。
在思路的梳理过程中,我欣喜的感受极海自己的产品路线,正是按照这个逻辑,走在趋势之上:
- Heycloud绝对云原生,按照云的特性开发,致力于提供更多可拆分的工具为各个团队灵活赋能;
- 极海自身的数据生产到数据分析的流程平台化,标准化,工具化就是一个最佳实践;
- 机器学习和数据分析的数据用例都是在数据科学团队中单独定制,而模型从Heycloud中获取。
我们也很荣幸正在将这些能力与用户实现共同发展的生态协作。