
浅谈聊天机器人开发思路
聊天机器人的开发大致基于以下3种模型:
1、基于规则的模型(Rule-based model)
2、基于检索的模型(Retrieval-based model)
3、生成式模型(Generative model)
基于规则的模型
如下所示,若问句中包含某个特定词,则机器人给予特定回答

这种方式需要尽心编写规则,还要考虑到规则间的优先顺序,AIML平台使用xml语言编写规则,可以快速搭建一个聊天机器人。以下就是使用xml语言编写的问答规则

当询问"你是干啥的",机器人就说 "我,我是人工智能的最新成果,可以复制人脑的功能,拥有更快的速度和准确度。"
基于检索的模型
原理跟搜寻引擎很像,检索式模型其实就是类似问答系统,我们会维护问题与答案的配对:
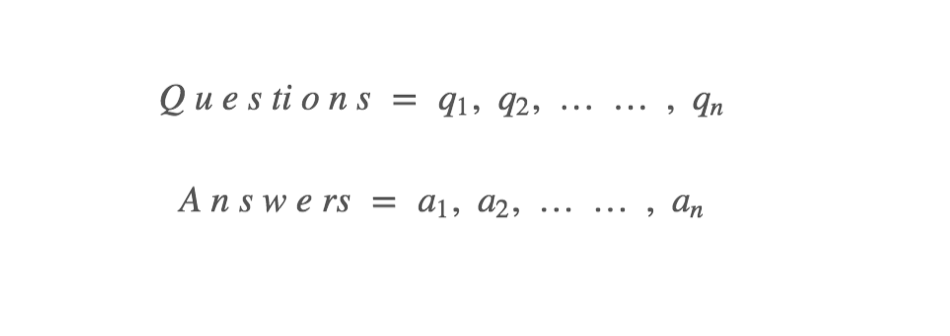
再根据使用者的输入的问题和Questions中的哪一个q最接近,就把Answers中配对的回覆丢给使用者。问答系统的背后藏着一个知识库,透过归类使用者的句型与知识库推理来计算出最适合的答案
基于检索的模型的关键技术包括提取关键词和相似度计算,计算使用者的问句与问答库中那个问句最相似。
提取关键词常用技术:TF-IDF,BM25
TF-IDF
文本中某个词出现的次数称为"词频"(Term Frequency,缩写为TF);在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("人工智能"、"云计算")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
TF-IDF计算方法

TF-IDF=词频(TF)*逆文档频率(IDF)
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言环境中的出现次数成反比。
以《中国人工智能行业调查研究报告》为例,假定该文长度为2000个词,"中国"出现36次、"人工智能"出现236次、"行业"出现110次,则这三个词的"词频"(TF)分别为0.02,0.12,0.055。然后,搜索Google发现,包含"的"字的网页共有102亿张,假定这就是中文网页总数。包含"中国"的网页共有27.9亿张,包含"人工智能"的网页为0.89亿张,包含"行业"的网页为7.4亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
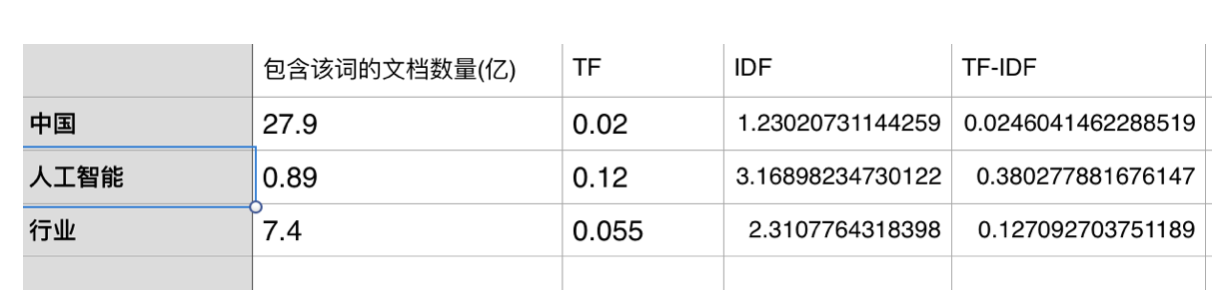
上图中"人工智能"的TF-IDF值最大,所以"人工智能"这个词是这篇文章中优先级最高的关键词
BM25
将一个句子分成了很多个「词」qi,每个词都会一个「IDF」分数,「f(qi,D)」指的是在D这篇文档中,qi这个词出现的次数,去除停用词,一个词在文章里出现次数越多,他就显得越重要。
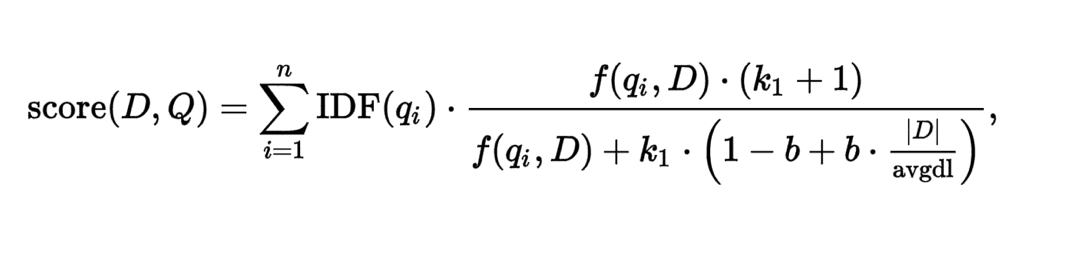
在TF-IDF的概念的基础上,BM25引入了b与k1这两个基于经验调整的参数,两者中b又会显得重要些,b表示文章长度,词频相同,文章长度短的要比文章长度长的有更高的优先级。
BM25的计算

‘文章’这个词与[u’这篇’, u’文章']的BM25分值最高
相似度计算方法有余弦相似度,简单共有词,编辑距离等
1.余弦相似度
余弦相似性表示两个向量的相似程度,当向量是二维时,可表示为两条线夹角的余弦值,两条线之间的夹角越小,其余弦值越接近1,两个向量越相似,原理如图1所示。
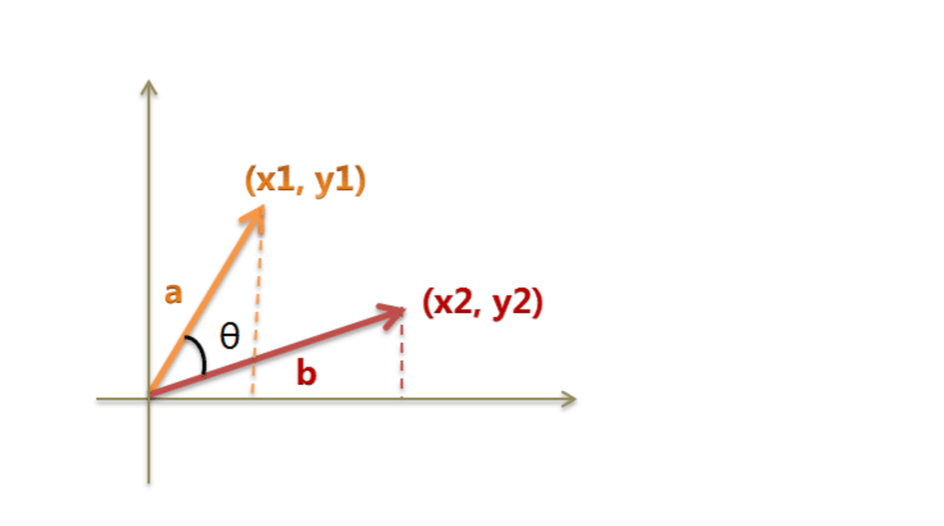
图1
当向量是二维时,根据余弦定理,余弦相似性的计算公式为图2所示
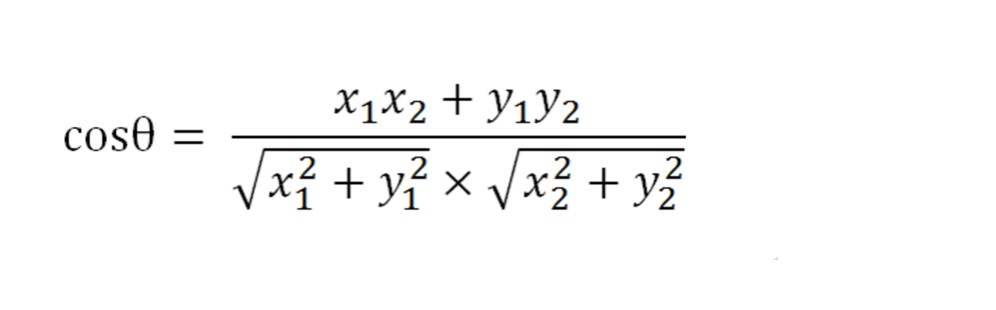
图2
余弦相似性计算公式在n维也成立,假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦计算公式如图3所示
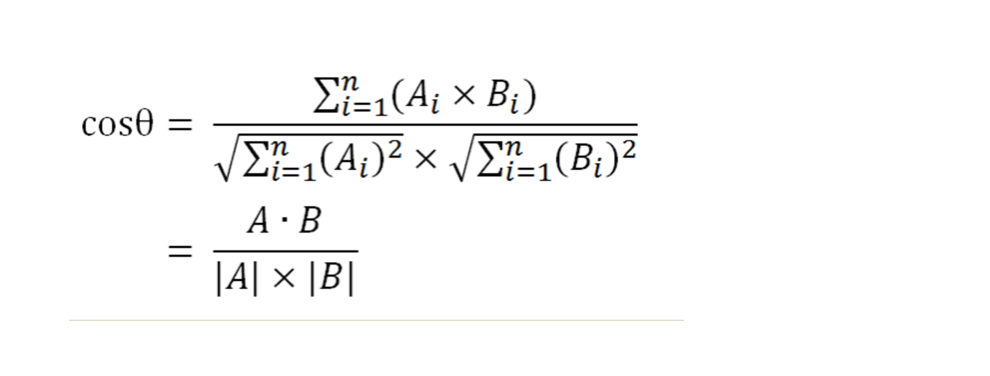
图3
余弦相似度的计算可参考余弦相似性原理实践
2.简单共有词
对两个文本分词
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
统计两个文本所有词
我,喜欢,看,电视,电影,不,也。
计算各个句子中包含在所有词中词的个数
句子A是5个;句子B是6个,所有词的个数是6
句子A与句子B的相似度
(5/6)*(6/6)=0.833
3.编辑距离
一段文本变为另一段文本要修改多少个字
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
句子A变为句子B要修改两个字,句子A与句子B的编辑距离是2。编辑距离越小,两个文本越相似
生成式模型
自从google的论文发表后,用Sequence to Sequence来实现聊天机器人就成为一股热潮。
Sequence to Sequence的基本概念是串接两个RNN/LSTM,一个当作编码器,把句子转换成隐含表示式,另一个当作解码器,将记忆与目前的输入做某种处理后再输出
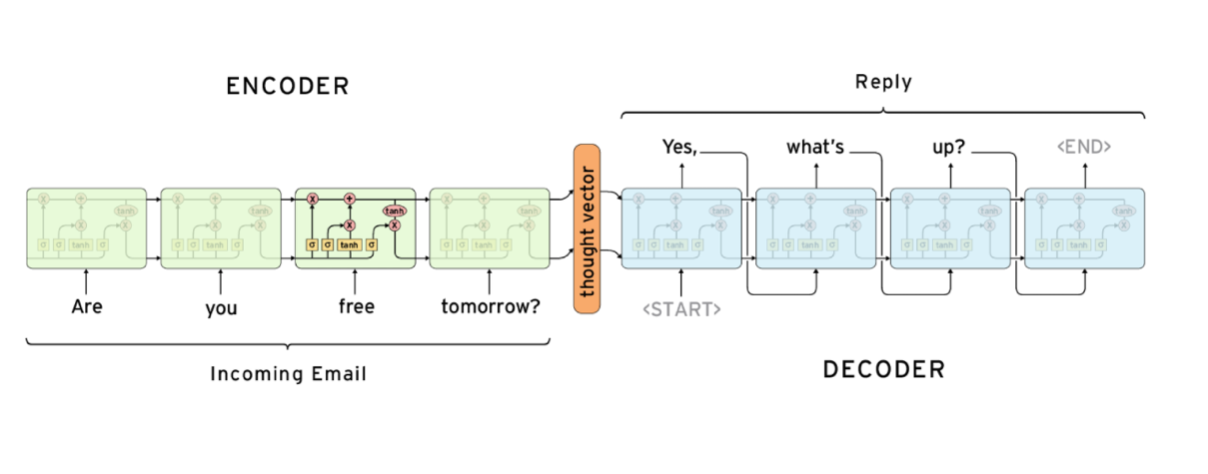
序列生成,就是把前一刻的输出当成下一刻的输入
利用开源机器学习框架TensorFlow可实现sequence to sequence生成模型,以下是使用中文语料库训练得到的聊天机器人(参考)的效果示意图
