
就业培训反而有害吗?
考虑这样一个问题:
政府推出了一项就业培训项目,项目的参与者记为“实验组”,未参与者记为“控制组”,如何来估计该就业培训项目对参与者收入的影响?
一个天真的做法是直接对比实验组与控制组的未来收入或就业状况,或者简单以是否参与为虚拟变量,对总体进行回归。
可是这种方法真的对么?
试想:什么样人会参加就业培训?肯定是失业或者低收入者居多。什么样的人不会参加就业培训?岗位好收入高的人不会参加就业培训。如果直接按照上述方法进行估计,很有可能你会发现参加就业培训的收入比未参加更低,所以得出结论就业培训反而是有害的。
再考虑一个问题:
我们的小明,在周围的同学都选择的就业之后,选择了攻读博士学位。经历了五年的博士生涯之后,小明找到了一份不错的工作。我们如何来帮小明估计,读了博士项目的小明和没有读博士学位的小明(假想),收入会有怎样的差别?可是小明已经读了博士,我们怎么才能估计出他要是不读博士,收入会是多少呢?
在第一个问题中,实验组和控制组的初始条件不同,于是存在“选择偏差”问题。对于第二个问题,如果依然采用同样的方法来估计,势必也会对结果的估计产生偏误。
一种叫做倾向得分匹配(Propensity Score Matching)的方法可以解决这样的问题。
倾向得分匹配,简称PSM,是目前国际上最为流行的统计学方法之一。广泛应用于某项治疗,政策,或者其他事件的效果评估。他的基本思路是这样的,以第二个问题为例,我们从小明的一大堆没有读博士项目的同学中,对每个人读博士项目的概率进行估计,从中选出和小明读博士概率近似的同学小刚。我们对实验组的每一个“小明”都匹配到控制组的“小刚”,就能对这两组样本进行比较研究了。
具体来说:以虚拟变量Di={0,1}表示个体是否读博士,1为参与,0为未参与。
记因变量为yi,该问题中为未来收入,yi有两种状态。即:

其中,y1i表示个体读博士的未来收入
y0i表示个体未读博士的未来收入
而我们感兴趣的统计量为“参与者平均处理效应”(Average Treatment Effect on the Treated,简记为ATT/ATET),即在小明读了博士之后,这个经历对他收入的影响:

在估计ATT的过程中,我们采用倾向得分匹配的方法。将K维自变量X的信息压缩为在[0,1]之间的一维信息,来进行匹配。
定义个体i的倾向匹配得分为,在给定自变量X的情况下,个体i进入实验组的条件概率,即:
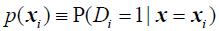
在利用倾向得分匹配计算ATT/ATET时,一般有以下几个步骤:
(1)选择自变量X,尽量将可能影响y0i, y1i, Di的变量都包括进来
(2)计算倾向得分,一般用probit模型或者logit模型估计
(3)进行倾向得分匹配
以下以一个药物治疗效果分析的实例,来演示如何用统计分析软件Stata实现PSM分析。
该数据来源于
http://ssc.wisc.edu/sscc/pubs/files/psm ,包含4个变量:治疗指标 t(表示是否参与治疗),自变量 x1, x2, 以及结果 y。其中接受治疗的概率和 x1, x2 正相关,x1, x2 与治疗结果 y 正相关。
[1] 导入数据
[2] 利用Probit模型估计ATET
teffects psmatch (y) (t x1 x2, probit), atet
结果如下:
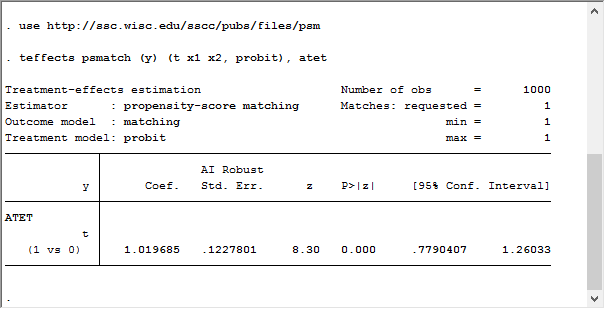
结果表明,该治疗会使得结果变量 y 上升 1.019685
如果采用logit模型估计,代码如下:
teffects psmatch (y) (t x1 x2), atet
结果为:
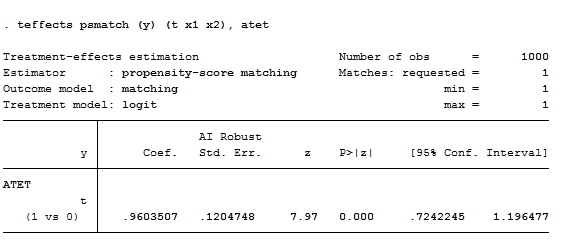
表明利用Logit模型估计出来治疗会使得 y 上升 0.9603507
以上我们发现,PSM是一种解决选择偏差的好方法。然而,该方法仍有一些局限性,比如:
(1)PSM 通常对样本容量要求比较高已得到更高质量的匹配
(2)PSM要求处理组与控制组的倾向得分有较大的共同取值范围(common support);否则,将丢失较多观测值,导致剩下的样本不具有代表性。
除了以上所说的PSM可以应用于医学,政策评估等学科外,该方法在地理方面的应用还依然有很大的扩展空间。只要是评估一项干预的影响,都可以尝试用这种方法解决。比如,评估鸟巢的建设对周边各种要素(比如房价)的影响,一项规划项目的实施效果评估,类似的应用场景还有许多,等待我们去发现。
参考资料:
[1] 陈强,《高级计量经济学及stata应用》