
数据决策的10条简单法则(上)
混沌大学的创始人李善友老师最看重的是认知中的那个“一”,把这个一解释为事物的本质也好,一个人思想底层的原则也罢,李善友老师追求的是启发他的学生们从这个宇宙最深层次的规律中总结自己的第一性原理。

作为一家数据创业公司,极海的第一性原理是:人类世界的运转最终靠信息流驱动——在决策中不拍脑袋,不靠直觉,不依赖经验,而更多的考虑数据,借助算法,就是信息流驱动的一个场景。所以极海的愿景是用数据让广大的决策者们轻松一点。极海想给大家做一个信息流的助手,是智能的助手也是make sense的助手。
美国人喜欢make sense这短语,曾经很多外企的中国白领们日常工作也常常让这个短语夹杂在中文中溜达出来。make sense——翻译成“说得通”、“合逻辑”。这真是个好词:两个人在争论的时候,如果用“这不make sense”替代“你放屁”,得避免了多少争吵啊?
数据的智能化业务,往往暗含着用机器学习产生的机器智能与人类专家知识经验的PK。即便极海的定位,是数据智能化的决策助手,并非要和用户专家们一比高下,但我也常常需要给用户们解释这个助手的决策建议是不是make sense。最近极海又要主导一个项目,虽然我对机器的“才智”充满信心,但我也有苦恼,用什么样的标准去评价结果到底是不是make sense呢?
我受到今年2份出版的一本新书的启发,书名中就有make sense,而且全书讲的正是对统计数据解释世界合理与否的判断原则:《数据侦探:让统计数据说的通的十条简单法则》。作者在我心中,鼎鼎的大名——蒂姆·哈福德——他的《卧底经济学家》和《混乱》曾经都是非常有影响力的畅销书。

这本书虽然没有解答我苦恼的难题,但我读下来,发现十条原则,对所有数据决策者都有用。我在公号文章中分两期做个极简的总结:
一、法则一:探索你的感觉
承认自己在任何时候都是一个感性的生物,即便是在看数据的时候,应该时刻都具有思考的理性。在评估对我们重要的信息时,控制我们的情绪并不容易,我们的情绪会把我们引向不同的方向。我们不需要成为数字信息的无情绪处理器——只需注意我们的情绪并将其考虑进去,就足以提高我们的判断能力。
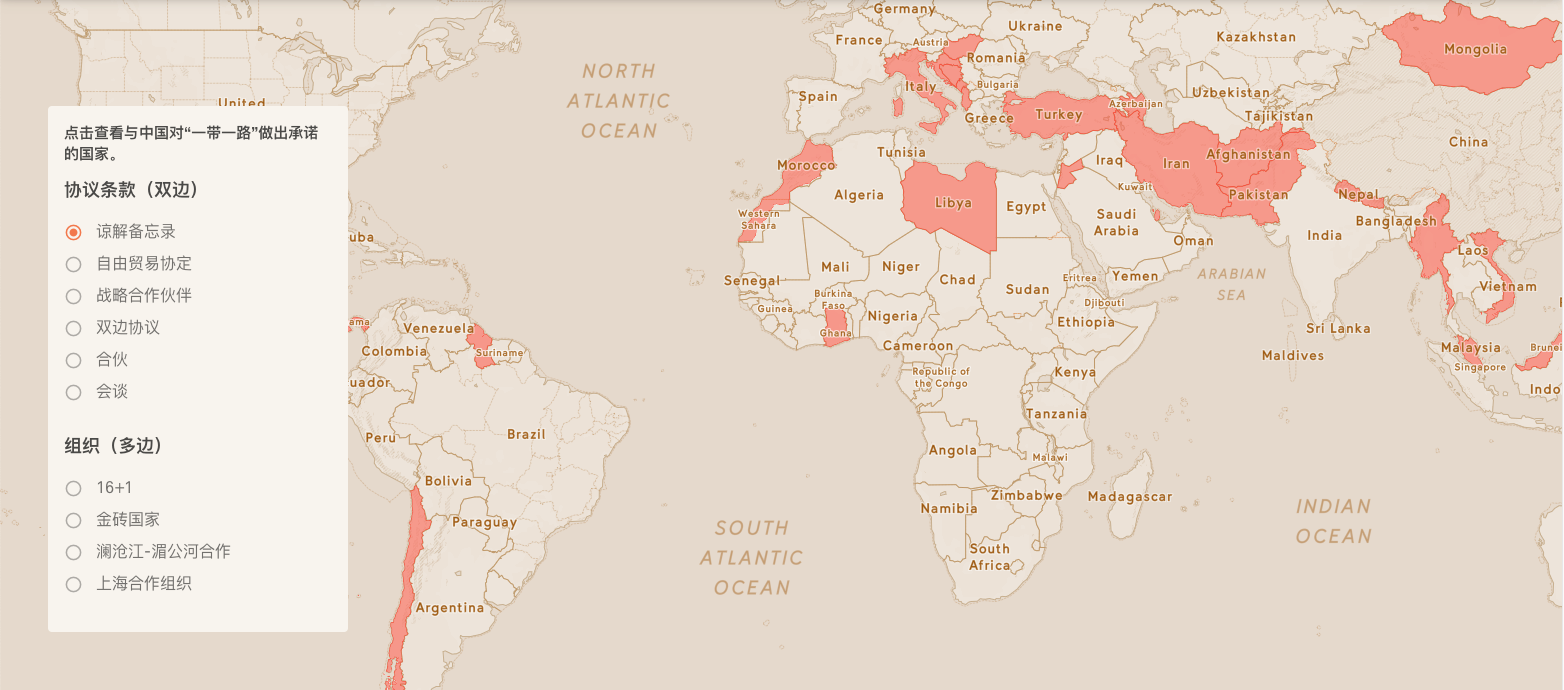
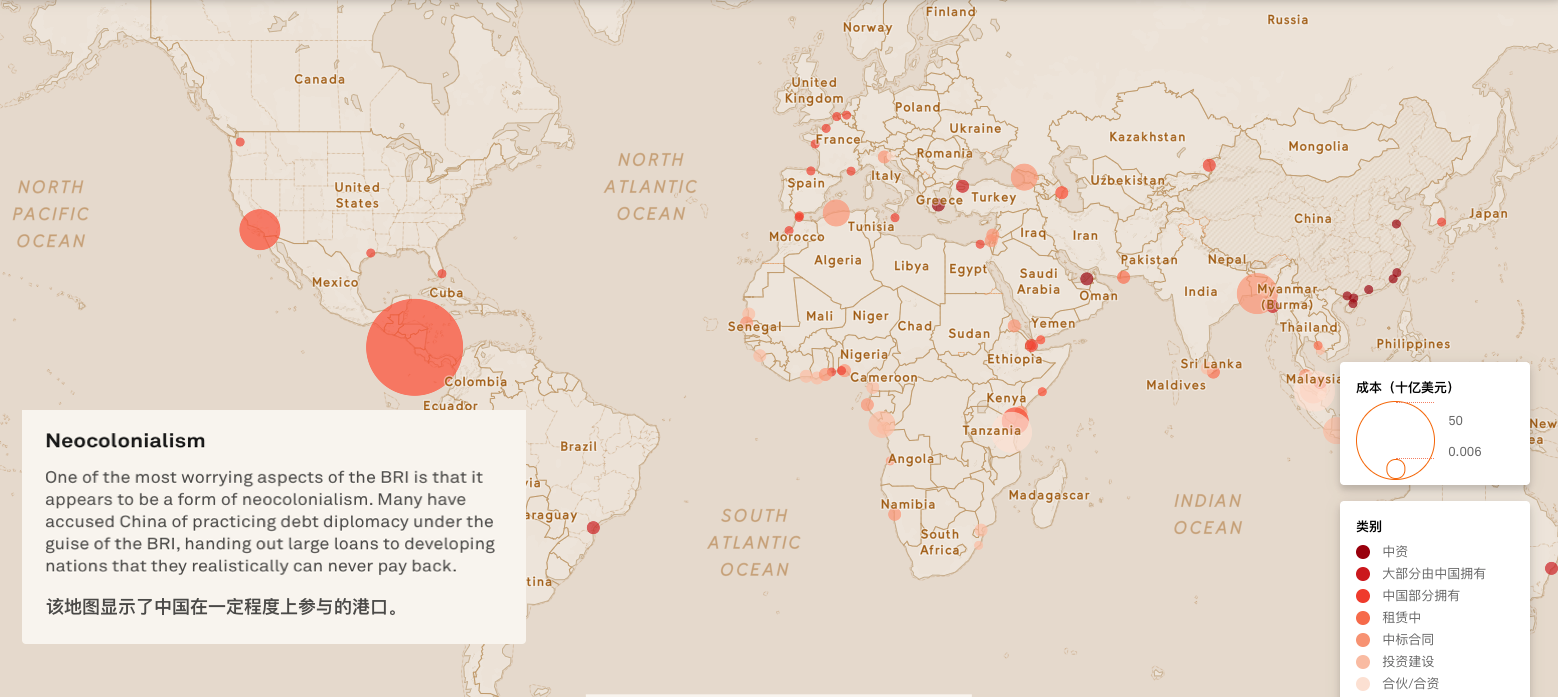
书中的例子很多,我举一个不在书中的例子:看如下的地图,作为中国人的你我会很自豪,觉得我们在世界上的地位蒸蒸日上;但作为已经当老大、做世界第一100年的美国人,心中隐隐会不舒服,感到在被挑战。这就是情绪。数据是一样的数据,地图就是那幅地图,你的情绪会让你有不同的判断。
二、法则二:思考你的个人经历
在某种程度上,我们看到的新闻报道也是数据(文字、图片、视频是非结构化的数据)。它们只是不具有明确数量代表性的数据,但新闻报道肯定会影响我们的世界观(刷头条的朋友们出来响应一下)。套用经典心理学著作《思考快与慢》作者丹尼尔·卡纳曼的术语:它们是“快速统计”——即时、直观、有力。“慢速统计”是基于对没有歧义的信息的深思熟虑,并不是那些倾向让我们觉得一惊一乍的刺激数据。
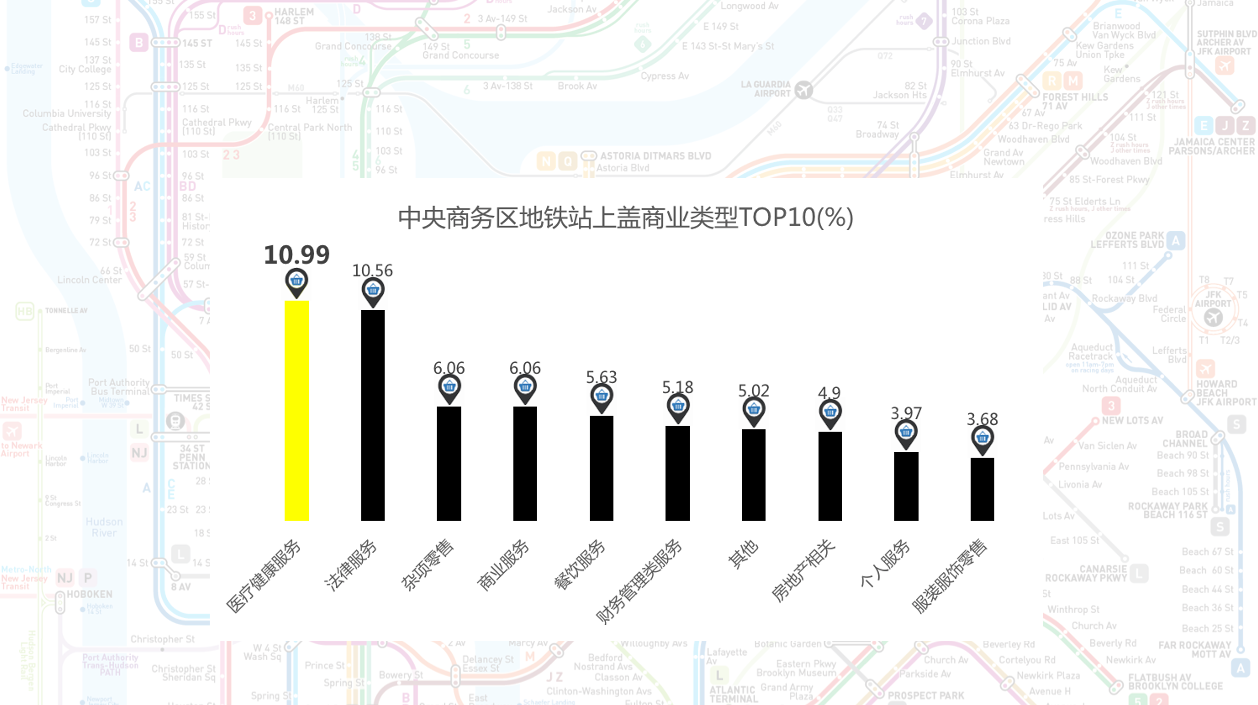
之所以让你一惊一乍的数据惊喜(惊吓),多是因为你个人的经历。不同的生活、工作精力对数据的感觉完全不同。我们统计了一下纽约地铁站上盖商业类型,以中央商务区作为类型统计,我们中国人是万万不能猜到比零售排名更靠前的是什么类型。
三、法则三:避免过早的枚举
Premature enumeration是作者自造的概念,意思是:还没有弄清楚数据中各个变量或者涉及到的统计维度到底指什么,就已经按照自己的理解下了定义。当深入到统计的世界,我们才深刻的感觉到,看似那么简单的一个说法,其实定义都是模糊的。作者举得例子让我大跌眼镜:婴儿死亡率——这个死亡数包不包括因为早产死亡的“准”婴儿,在各地的定义都不一样。在英国某些地区的医院为了不让妈妈自责难过,居然不说“早产”,而是“生下来死了”,你能体会这不同定义之间的语言差异吗?这个地区的婴儿死亡率高的就离谱。
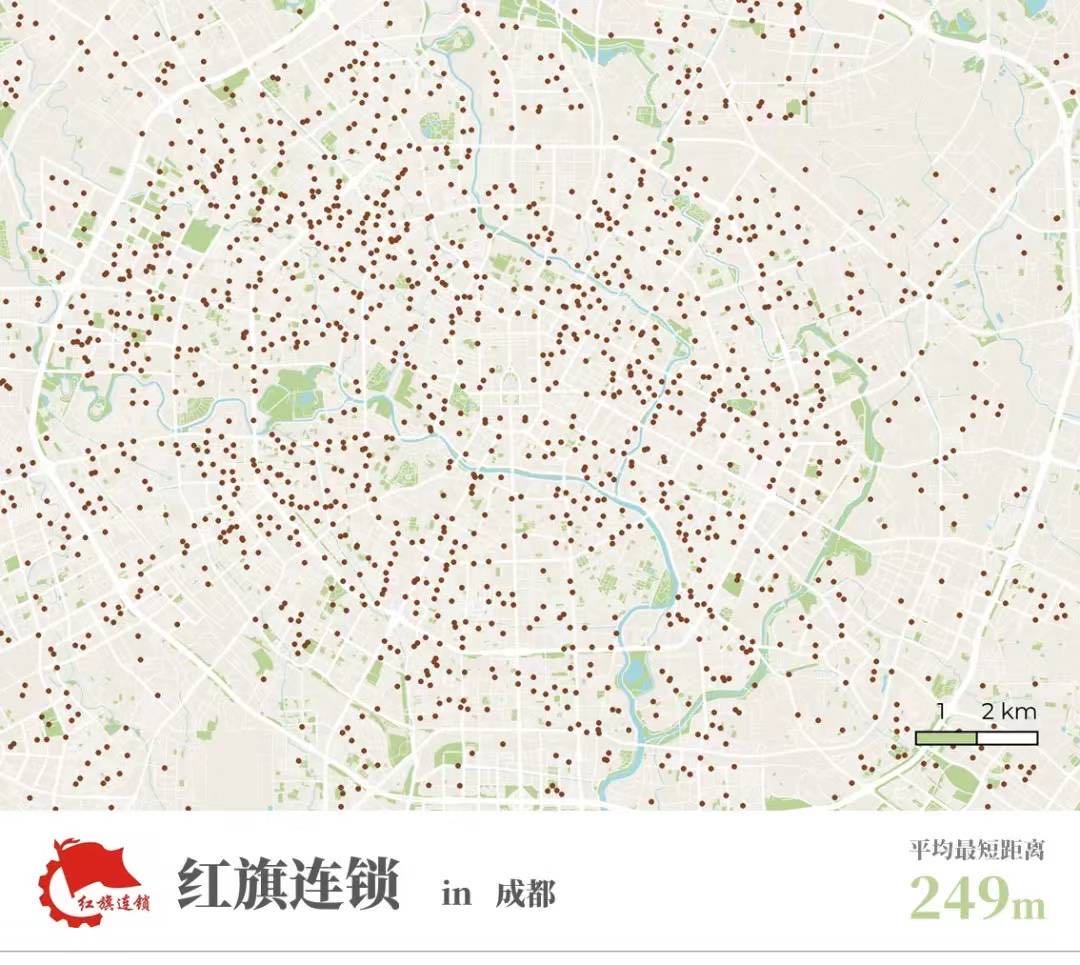
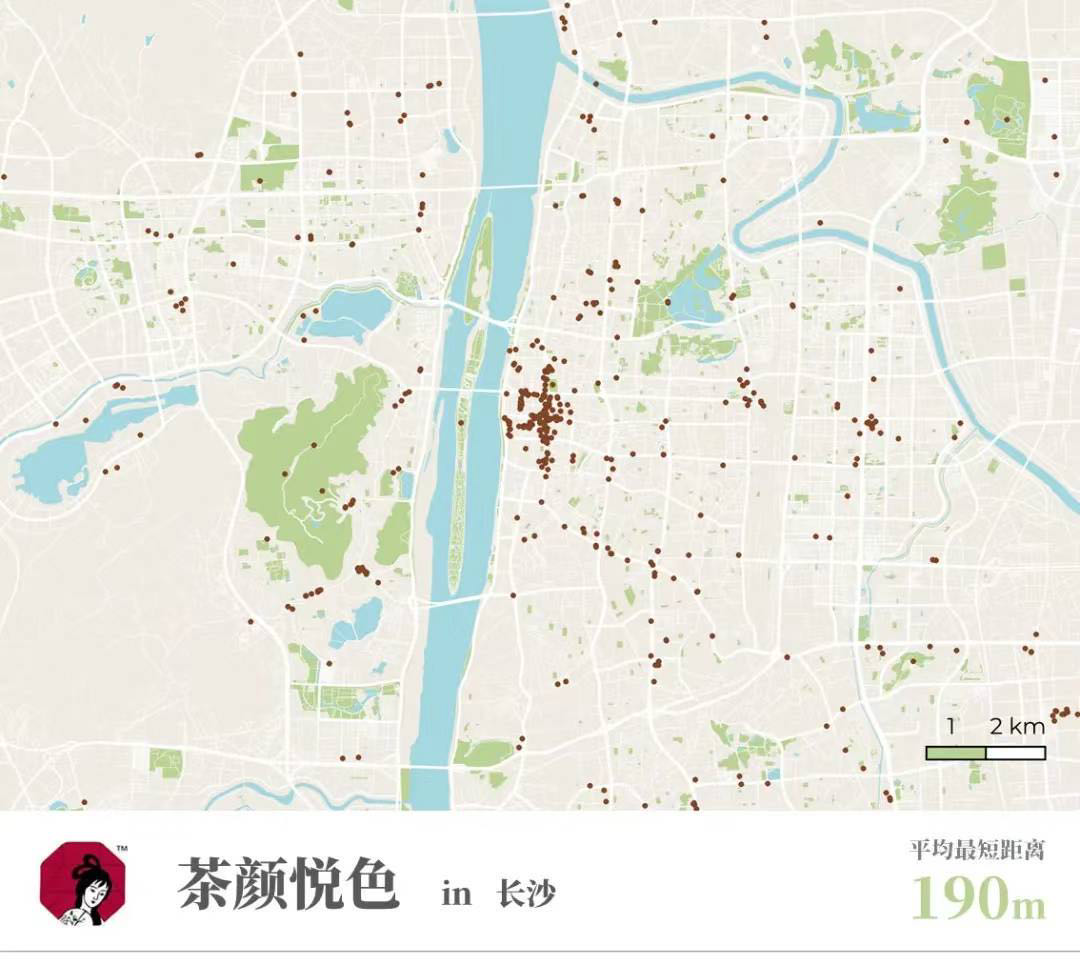
我举一个我们自己做品牌监测的例子。如果我说茶颜悦色在长沙比红旗连锁在成都的密度更高,你一定得探究,密度是什么意思?单位面积是指全城市平均吗?成都和长沙分别都包含郊县吗?
四、法则四:退后一步,享受美景
想象你突然从天而降贴在一幅画面前20厘米,你看到的是没有线条的笔触,一些黄绿粉红的颜色肆意堆叠,有一些不明觉厉。退后一步,你看到了画的全景,才明白那些亮黄居然是浮在池塘上的莲叶。你还理解到了那些淡淡的紫好像还映射了池塘上的蓝天。你从画前抽身,退着离开出了房门,抬头一看,竟是纽约大都会博物馆!你意识到刚才看到的不会是旷世杰作吧?等你再退后一步,去历史的档案堆里查阅,了解到莫奈画的睡莲有181幅,你又会怎样想?大都会收藏也不过尔尔吧。


从数据中,退后一步的方法,一是要增加历史背景,就是将这个数据放到历史的长廊里去看,当下和过去怎么对比——中国的GDP比美国有差距,但如果用1949年中国GDP占全球的比例和2019年做对比,从4.5%到16.3%,这个成就太伟大了;要是回到1600年的万历28年呢?大明朝占比全球是29.2%,哦,不上朝的万历皇帝别自嗨;二是要对数据的尺度建立感觉,简单的操作就是问你自己一句“这个数很大吗?”
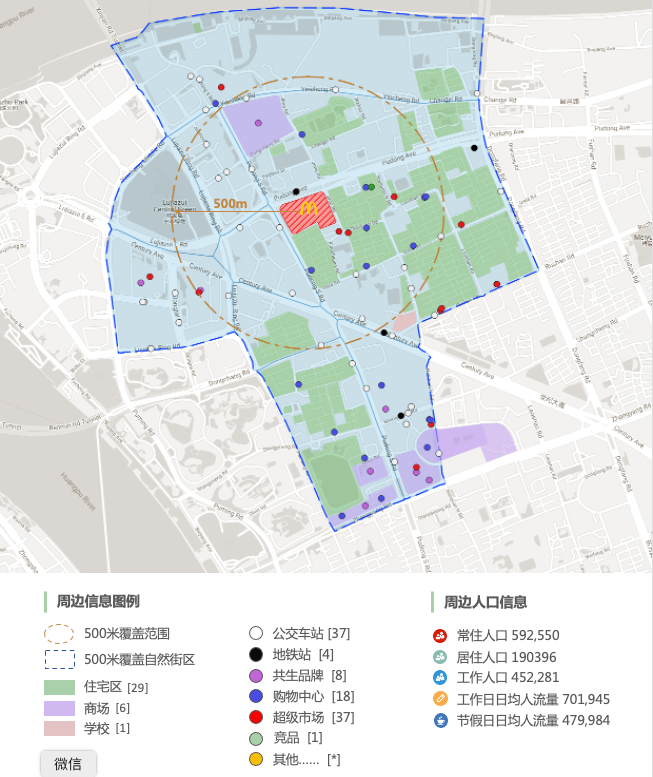
我们在极海做的数据工作也是希望为用户带来这样的“退后一步”的便利。比如品牌监测的产品,会对历史的数据认真的记录,方便用户进行对比。对任何一个关注点周边也都有具体的数值,对这样的网络规划图长期研判,看多了,自然也就有了数据尺度的感觉。
五、法则五:了解背后的故事
了解背后的故事,就是要了解你看不到的数据。
在统计学领域有一个无人不知的著名故事:数学家亚伯拉罕·沃尔德(Abraham Wald)在1943年被美国军方请求就如何加强美国空军的飞机提供建议。飞机出动执行任务后回来,机身和机翼上布满了弹孔;这些地方肯定需要加厚装甲?沃尔德的书面回应是高度技术性的——里面有一堆统计学的公式。但关键的想法是:我们只在返回的飞机上观察到损坏。那被击落的飞机呢?在幸存的飞机上,我们很少看到发动机或燃料箱损坏。这可能是因为这些地区很少被击中——也可能是每当这些地区被击中时,飞机就注定要坠毁,他们飞不回来了,所以应该给燃料箱加厚装甲。
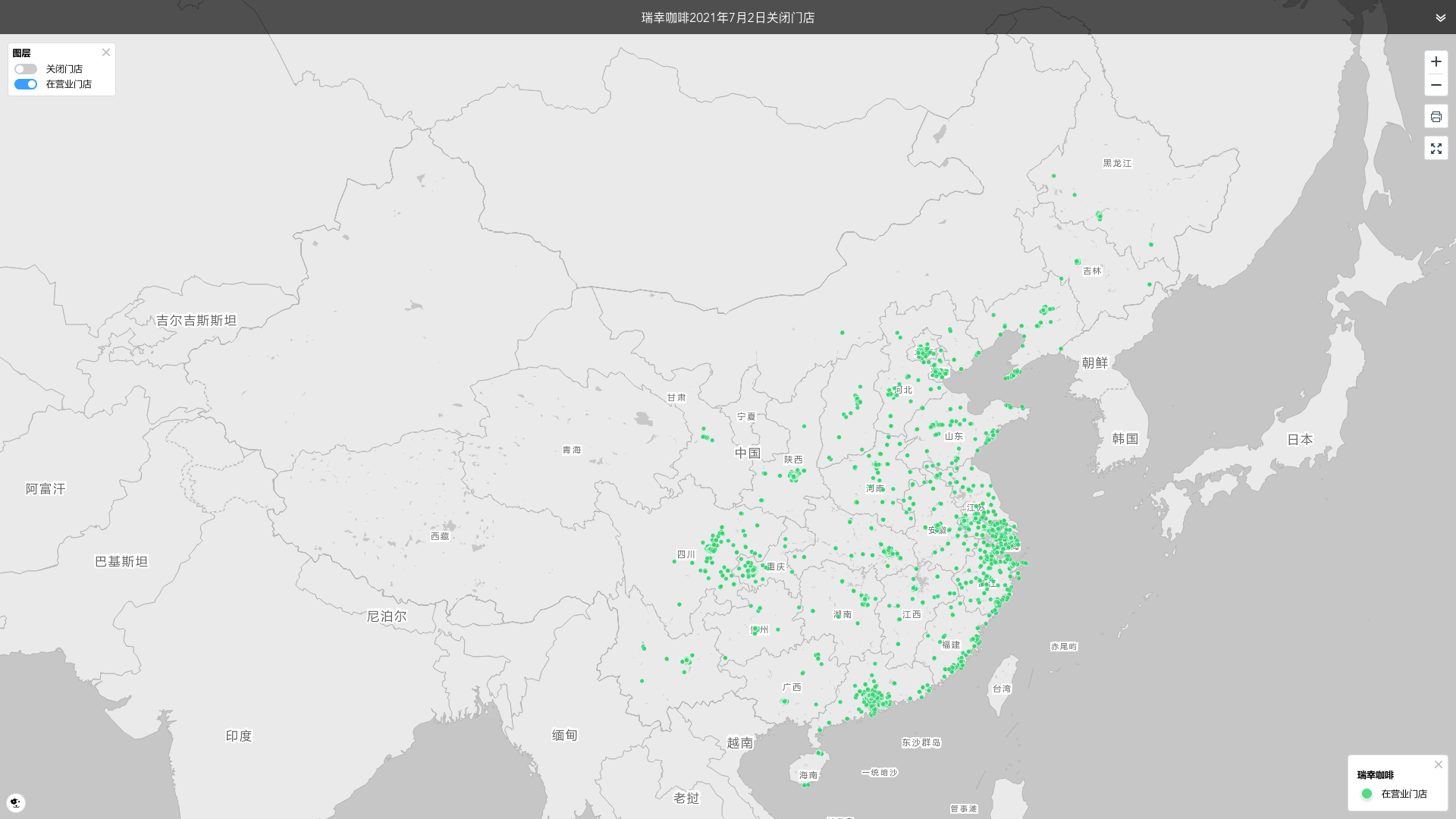
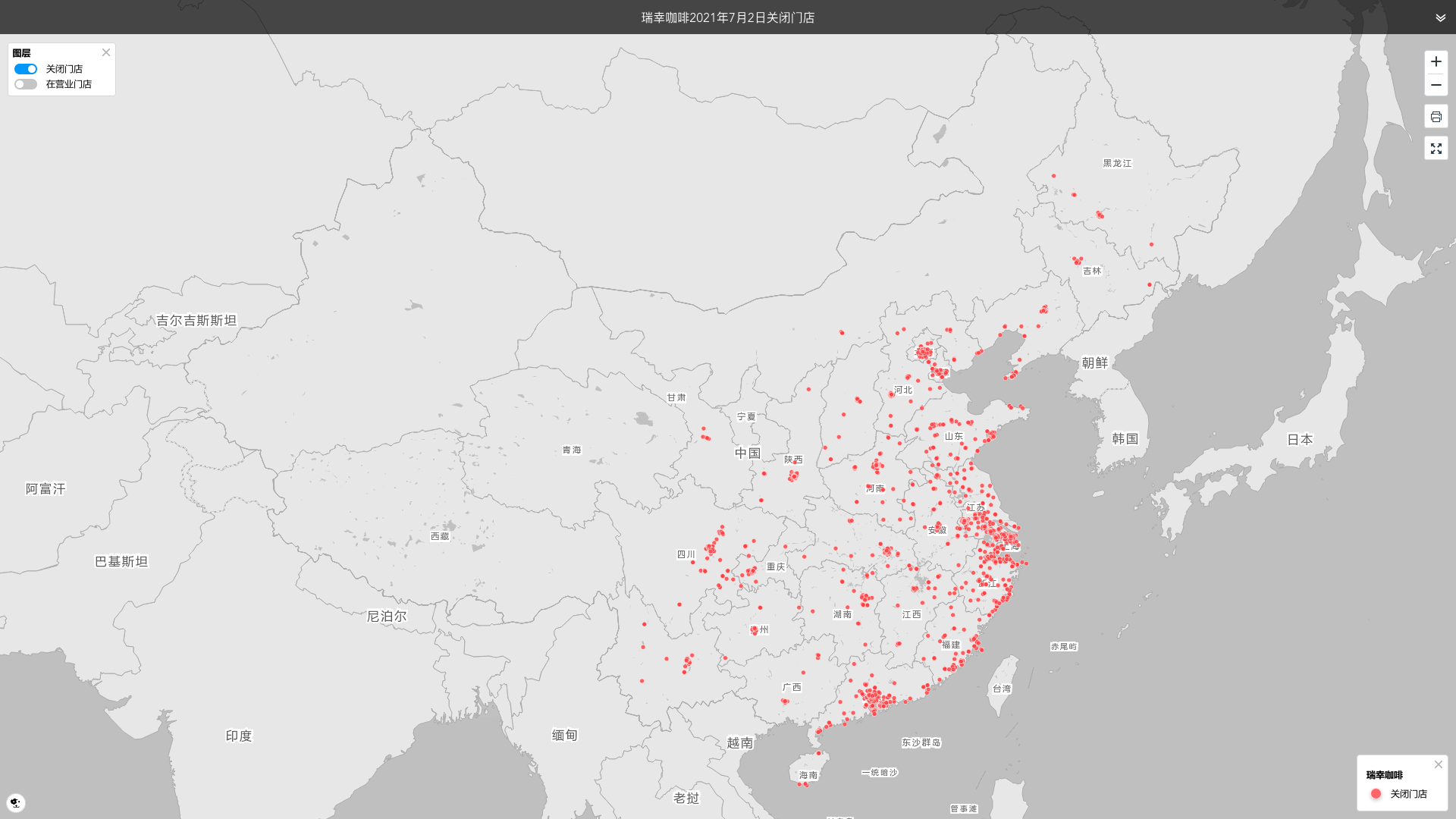
为什么沃尔德会想到没有飞回来的飞机呢?好像这样的洞察真是大开脑洞。但对于统计学家来说,将数据分成看得见的和看不见的也许都已经成为习惯了,也就是说背后的故事,对于统计学家来说就是眼前的故事。但这对于常人来说,却是不容易做到。这也是我们极海品牌数据监测产品为什么要记录那些关掉的店:不止看到眼前的热闹,还要看到背后的沧桑——通过订阅式的产品,不依靠用户自己有沃尔德式的洞察,依靠的是系统,自动自觉的去了解这类背后的数据。
后面的五条法则,待续