
数据决策的10条简单法则(下)
前文《数据决策的10条简单法则(上)》,说的是How:作为数据观察者的你,是怎么理解数据的——既有情绪上的感性,也有认知上的局限。所以数据看似客观,到了人类的感知层面却是很主观。本文是10条法则的下篇。说的是What和Why。数据缺什么,数据为什么被这样或那样解读。
六、法则六:询问缺失了“谁”
这条法则与法则五的核心原理一致,只不过更聚焦在统计数据背后缺失的“人”上,也就是说,眼前的数据代表的是哪一类人?这一类人可以代表全体吗?作者在本章中的一个例子说的是当年波士顿政府开发了一个iPhone的app,下载了该app的驾车者遇到路面破损的情况可以方便的上报路面破损位置,这样道路养护人员就不必全城“迅游”式的扫街了。本以为是众包大数据的好主意,结果汇总上来的位置特征是:有钱、年轻的、知道该App的群体经常开车走的道路,这几条道路只占波士顿很少很少的一部分。
大数据集可能看起来很全面,但“采样人群=所有人”通常是一种诱人的错觉:没有一个大数据可以囊括所有人,所以很容易做出证据不足的假设。一看到用信令数据、手机位置显示的热度地图,就认为我们已经有了代表所有人的数据。我们必须经常问:这个数据缺了谁,缺了什么。这是需要谨慎对待大数据的一个要点。

七、法则七:当电脑说“不”时,要求获得透明度
大数据滑铁卢的著名案例是谷歌曾经轰动一时的流感预测,后来被证明是无效的。当谷歌的工程师将流感爆发与搜索词条进行相关性训练时,没有意识到这些词条其实与“冬天”的各种行为都是相关的,所以这个训练后的模型并非是“流感探测器”,而是“冬天探测器”。当非季节性的流感爆发时,这个预测因子就失效了。
在早些年,对大数据特征的介绍中,都会提到通过大数据提炼的规律,大部分是来自相关性而不是因果性。但这也造成了人们的困惑,当计算机以我们不理解的方式进行决策时,很容易导致我们对机器的粗心大意——反正我们也无法考虑这么多维度的相关性。现代数据分析可以产生一些奇迹般的结果,但大数据的可信度有时候还不如小数据。小数据通常可以被仔细审查;大数据却往往是数据工程师的高级黑话——模式识别算法就是神秘的黑匣子。
虽然很多时候,机器学习训练出来的模型在解释因果上确实困难重重,但是我们还是可以探究一些问题:底层数据是否可访问?算法的结果是否经过了严格的评估?独立专家有机会对算法进行验证吗?我们不应该简单地相信算法在任何时候都比人类做得更好,但也不应该假设如果算法有缺陷,人类就会完美无缺。
极海的智能化业务对用户非常透明,不仅仅将用到的原始数据都原封不动的提交给用户,也会将机器学习算法的代码和说明文档也都作为交付物用于用户下一步的调整和反复验证。
八、法则八:不要理所当然的认为统计部门发布的数据就是真实的
作为2016年的总统候选人,唐纳德·特朗普为了击败希拉里·克林顿,作为竞选战术之一,他要给美国民众描述一个美国的囧相:他的竞选团队想宣称美国经济已经崩溃。但官方统计数据显示失业率非常低,低于5%,而且还在下降。对此,他本应该有一个深思熟虑的回应——例如,失业率并不能衡量工作的质量、安全性或挣钱能力。但特朗普选择了更简单的方式,他一再驳斥失业数字是“假的”和“完全虚构的”,并声称真正的失业率是35%。
特朗普的笑话太多了,作者不是想嘲笑特朗普的天真率性,他在书中举这个例子是想说各国统计局的数字,政客们可以用来讲各种故事,也可以肆意的诋毁。作为大众,作为把政府统计数据当做基石的数据决策者们,我们不该不信,但也不要全信。
在国家管理的层面上,数据也是要为政治服务的。前两年东北三省的GDP通通的“少”量注水,政府领导们有Ta们的“不得已”;人口普查数据要有取舍的发布公开,有关部门有专业性的考量。作为中国公民,我们对于数据的透明度早就锻炼出了灵活性的理解,这一点可能不是欧美数据专家能体会的。而关于这一点法则,我的建议是如果在数据的准确度上确实有严格的要求,除了寻找官方统计口径,还要参考更多的数据源,交叉对比。
九、法则九:错误的信息也可能是漂亮的
当你在注目观看数据可视化的成果时,如果你认识到某人很可能在试图说服你去想某事儿做某事,你对这个可视化成果的理解就会更深一层。巧妙的说服性图表没有错,就像巧妙的说服性文字一样。被说服并改变主意也没有错。但你一定要识别,别被漂亮的图表给蒙了!
作者主要以南丁格尔的故事贯穿本章,还引用了另外一个颇有造诣的可视化专家Alberto Cairo的书《How Charts Lie(图表会说谎)》。我跳到《How Charts Lie》,选了一个例子提醒读者:看地图的时候要小心。
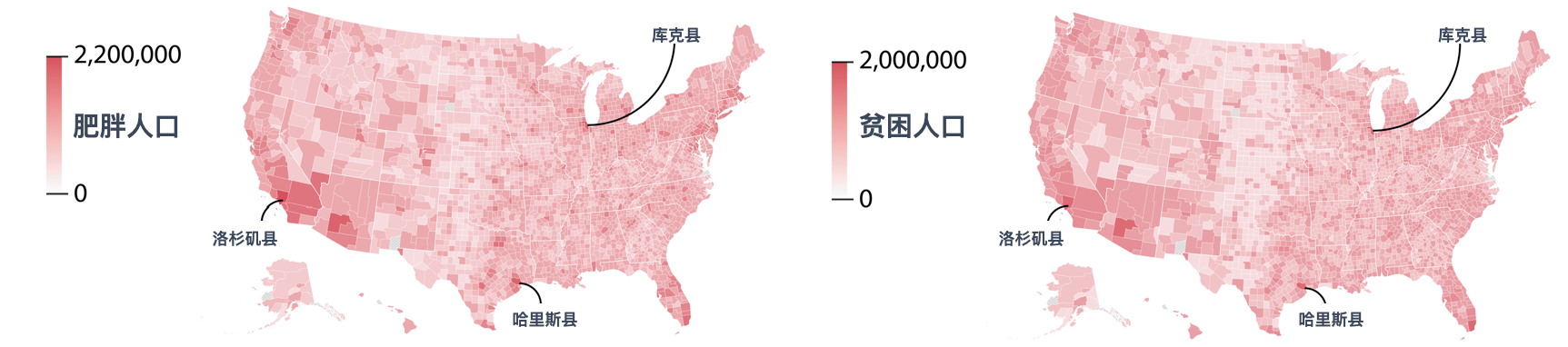
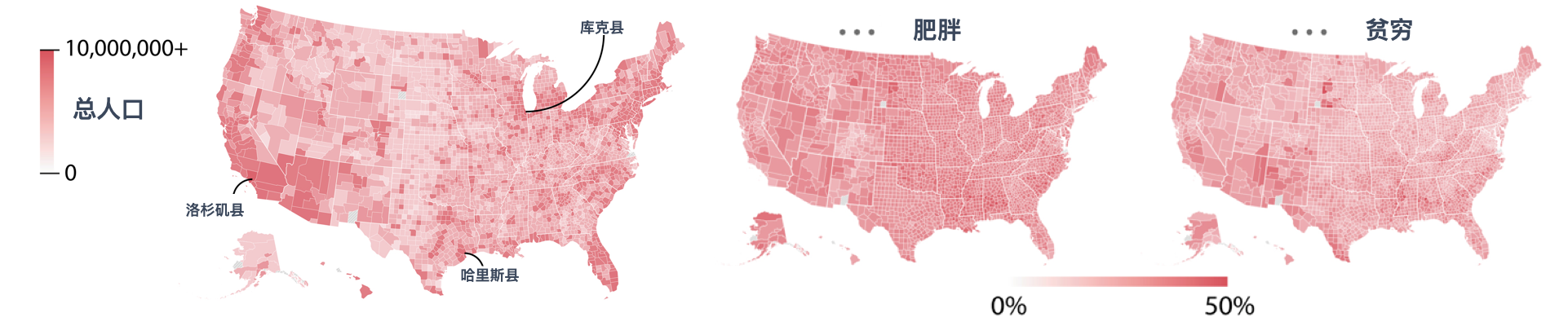
那如何避免被漂亮的图表错误的引导?
首先,也是最重要的,视觉来自如此快思考的本能,请检查你的情绪反应。停一停,看看这张图给你的感觉是什么:胜利、防御、愤怒、骄傲?识别到这种感觉。
其次,检查你是否了解图表背后的基本知识。横轴和纵轴到底是什么意思?你知道什么变量是被测量或计算的吗?有没有要理解的上下文,或者图表只显示了几个数据点却没有包含上下文的数据?如果图表反映了复杂的分析或实验结果,你了解作者正在做什么吗?
十、法则十:保持开放的头脑
这条法则如果没有落实到具体方法的话,就只能是正确的废话了。我相信没有一个人愿意承认自己是:老脑筋;顽冥不化。就是问一个特别不接受新鲜事物的老人家:您是不是头脑很封闭呢?Ta也不会承认的。其实每个人的开放都是有限的开放——对自己愿意相信的观点开放。
作者倡导做一个“积极开放的思想家”。这可不是说说而已的头脑灵活,而是特别主动的开放:根据新的证据轻松抛弃旧观点,并将与他人的分歧视为学习的机会。Ta们的态度是:快说说有什么我不知道的论据和观点?证明给我听听,我的观点哪儿出错了?
“一致性”是人的心理上最重要的潜意识。主动破坏自己的一致性就会担心别人感觉你这个人没有立场,总是在出尔反尔,所以主动寻找自己的观点错误是很反人性的。那对于数据决策者来说,怎么能轻松的开放又不是被反人性煎熬呢?我建议是将外部观点和内部观点结合起来,也就是说统计数据加上个人经验。但是,提醒您注意的是,要从外部数据开始,从外部观点开始,然后根据个人经验对其进行修改。如果你从内部观念开始,你没有真正的参照系,没有数据的尺度,你出错的概率会大的多。
写在最后:
本书最后还给出了条终极黄金法则:要有好奇心。这一条就忽略了吧。好奇就会谦虚,就会探索,就会学习;学习就会迭代,就会进步,就会突破。还有过不好的人生吗?这么简单的道理,谁还不明白呢?无非是,对孩子来说,好奇心极其简单,对成人来说,想要保持,哪怕是拥有,都太难了。
结合本书,对于数据决策者来说,我给三点很简单就能尝试的建议吧:
1、周一到周五每天固定十分钟,就看数字化的新闻、图表、故事,什么都行,用数据每天刺激自己的神经;
2、每当遇到决策的场景,问问手下、同事、同行,有数据吗?如果有,问问数据都覆盖哪儿了,谁了,多久了?
3、每年看一本有关数据的书。