
我用codex做了一张瑞幸 GIS 地图,体会了AI多巴胺和内啡肽
最近我和 Codex/Cola 协作,有一个很微妙的体会:单个任务的效率变高了,但总工作时间反而变长了。
以前做一个 GIS 项目,比如抓链家的小区数据、清洗边界、接地铁、做板块分析,我知道这事不可能一天搞定。做到晚上某个时间点,心里会自然出现一个暂停键:算了,明天再说。
AI 助手也可以有这个暂停键,但我不舍得停。
我说“帮我把瑞幸门店接到北京板块上”,它一分钟就跑完了;我又说“那再加地铁覆盖率看看”;它又跑完;我再说“如果加小区、房价、教育指数,会不会能看出开店机会?”它继续往前推。
于是一个原本很小的任务,慢慢滚成了一个大货。
这件事危险,也迷人。危险在于容易停不下来;迷人在于它真的淌出心流。你不是在刷短视频等刺激,而是在不断提出更好的问题,马上得到反馈,再把反馈变成下一个问题。大脑里那种期待之乐和征服之乐交织起来,时间感会变淡。

刚好我在复习万维钢老师的现代思维工具100讲,其中《主动高认知负荷:注意力的 Pro 模式》正好解释这件事儿。他讲了一个很关键的观点:真正的专注,不是靠意志力硬扛,而是让任务本身调用足够多的注意力资源。外在负荷要降,真正带来学习和产出的是增益负荷。换句话说,快乐不是来自“轻松”,而是来自你主动把世界变成一道刚好够难的题。
AI 助手最有意思的地方也在这里:它不是替你少想,而是替你卸掉杂活,让你有余力想更复杂的东西。
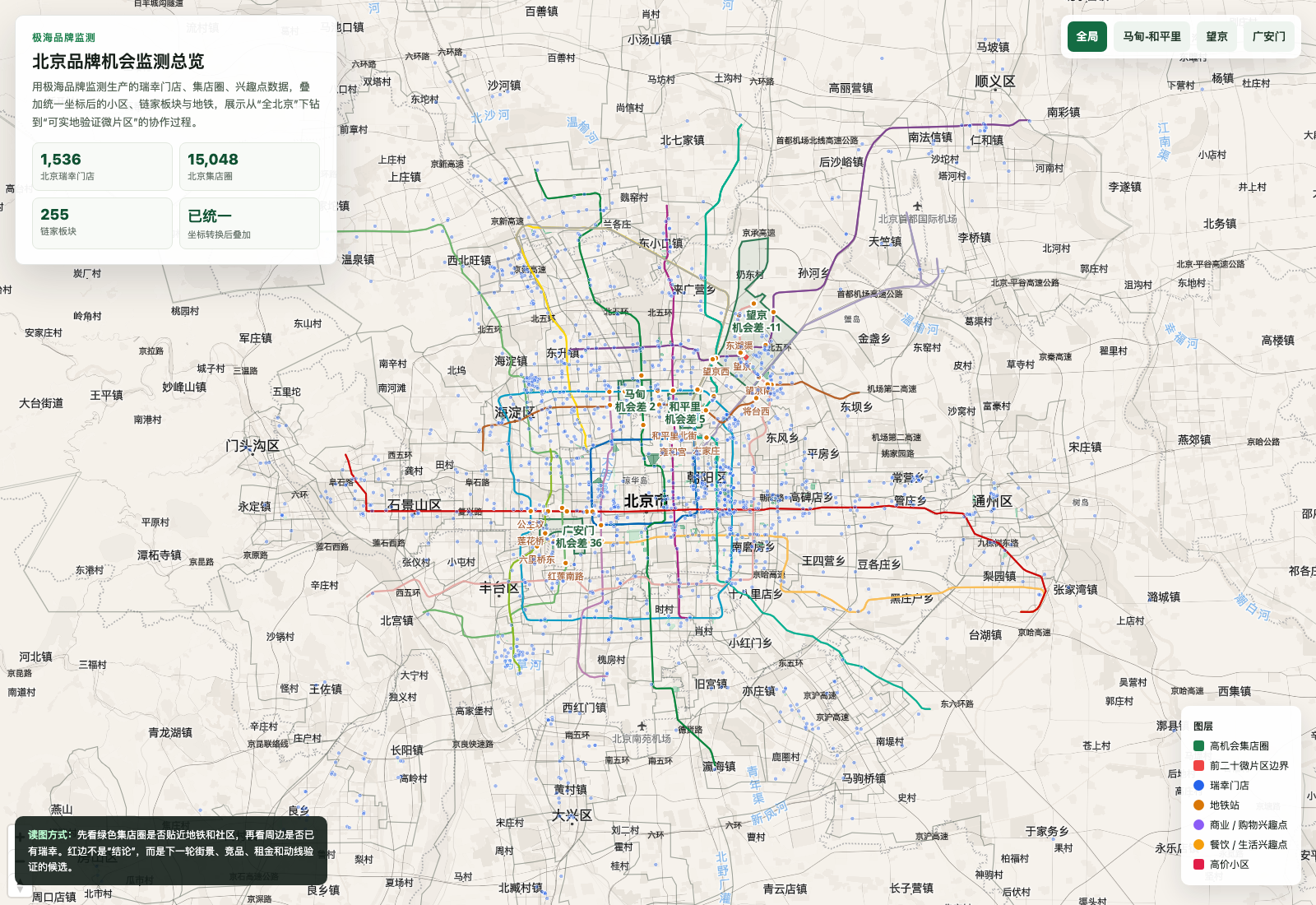
我有一个真实的小项目示范:如何从“瑞幸在北京开在哪儿”这个小问题,一步一步进入 GIS 与品牌位置分析的心流。
这次数据里还有一个重要主角:极海品牌监测的集店圈。除了集店圈,瑞幸门店、兴趣点、地铁线路和站点都来自极海品牌监测生产的数据,坐标是高德的gcj02。
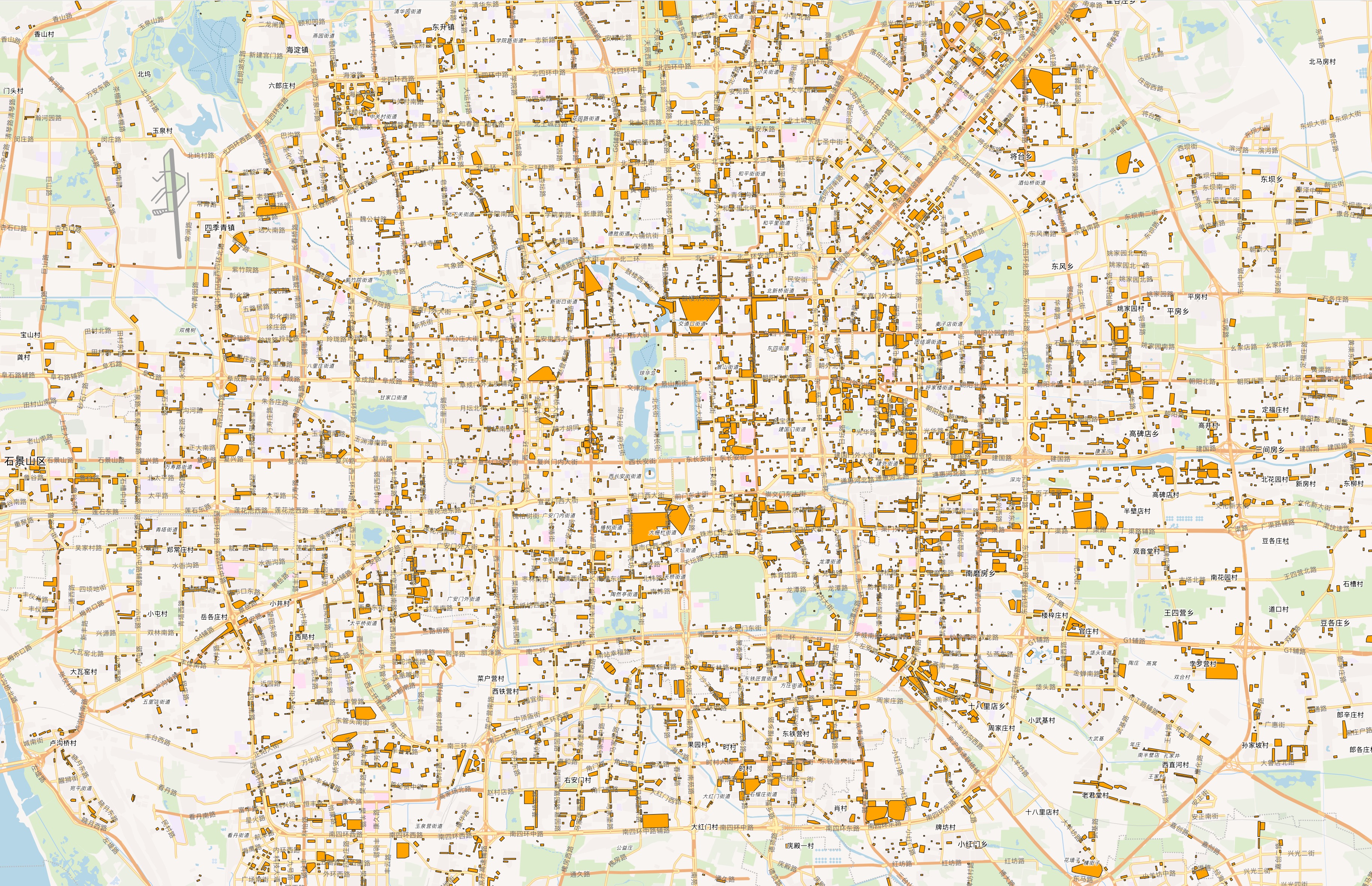
北京小区、链家板块是百度坐标。我为了可以自定义底图的样式,选择了 WGS84坐标的OSM 。咱们专业GISer干活,得让地图真的是在 GIS 中工作,而不是几层数据粗暴叠上去,我用QGIS中的geohey 坐标转换插件将所有的数据转成 WGS84,再做空间连接。
任务 0:先别宏大,从一个小问题开始
我的第一个提示词很简单:
把北京瑞幸门店按链家板块归属统计一下。先别建分析模型,只告诉我哪些板块已经很密,哪些没有店。
这一步用到本地数据:
- • 极海品牌监测生产的瑞幸咖啡门店表,数据日期 2026-05-30,北京 1536 家门店;
- • 极海品牌监测生产的北京集店圈,15048 个微片区;
- • 极海品牌监测清洗的北京兴趣点,用于观察商业、餐饮、办公和生活服务;
- • 北京链家板块边界,255 个板块;
- • 北京小区边界,7473 个小区;
- • 板块地铁覆盖率、教育指数、房价和二手房活跃度等已处理指标。
第一张图不再只是把门店点上去,而是做成一个 GIS 监测视图:底图、地铁、板块、门店和高机会微片区同时出现。
这张图的价值不在于答案多高深,而在于它把注意力预加载起来了。
看到地图后,你开始看到问题:中心城密度很高,通州、回龙观、望京、CBD 一带明显被点亮,但有些轨道条件不错、社区也不弱的板块,瑞幸并没有那么多。
这时候最容易发生心流的入口出现了:不是“我完成了”,而是“我还想再看一眼”。
任务 1:加一个变量,问题立刻变聪明
第二个提示词:
把板块地铁覆盖率和 1km 站点数接进来,看看瑞幸是否更偏向轨道交通友好的地方。
这一步开始从“点位统计”进入“城市机制”。
咖啡店不是随机落点。瑞幸尤其依赖通勤、办公、学校、社区复购这些高频路径。地铁不是全部,但它是一个很好的入口变量。我们不需要一开始就完美,只需要让问题多一层结构。
AI 的价值开始显现:它帮我做空间关联、字段合并、异常检查、导出结果。我不用把注意力花在重复操作上,可以一直停留在判断层面。
这就是万老师说的“降低外在负荷”。真正让人上头的不是复制粘贴字段,而是追问:为什么这个板块地铁很好,门店却少?
任务 2:再加居住底盘,模型开始有解释力
第三个提示词:
再把小区数、二手房挂牌量、均价接进来,区分办公流量和社区复购可能。
这一步加入了社区规模和房产活跃度。一个板块有没有开店空间,不能只看地铁,也要看周围是否有足够稳定的生活半径。
于是问题变成了:
- • 这个板块有没有足够多小区?
- • 二手房活跃度是否说明它是成熟生活区?
- • 地铁是否能带来通勤流量?
- • 现有瑞幸数量是不是已经过饱和?
注意,任务此时已经变难了。你需要同时托举多个变量:板块边界、门店点、小区、多指标、现有密度、潜在需求。
但这不是坏事。恰恰是这种难度,把走神挤出去了。
任务 3:先做一个粗糙但可讨论的机会分
第四个提示词:
不要追求完美,先用社区规模、二手房活跃度、地铁覆盖、板块复合分做市场底盘,再扣掉现有瑞幸饱和度,给我一个机会差。
我让 AI 先做一个演示模型:
市场底盘 = 社区规模 + 二手房活跃度 + 地铁覆盖 + 站点数 + 板块复合分 + 教育指数
当前饱和度 = 现有瑞幸门店数 + 单位面积门店密度
机会差 = 市场底盘 - 当前饱和度
这个模型当然不等于真实开店决策。真实决策还要看租金、竞品、楼下动线、外卖半径、合同条件、商场招商、消费券、品牌策略。
但它已经足够让讨论进入下一层。因为我们终于不只是在说“感觉哪里不错”,而是在说“为什么这个地方值得看”。
第二张图就是机会差。
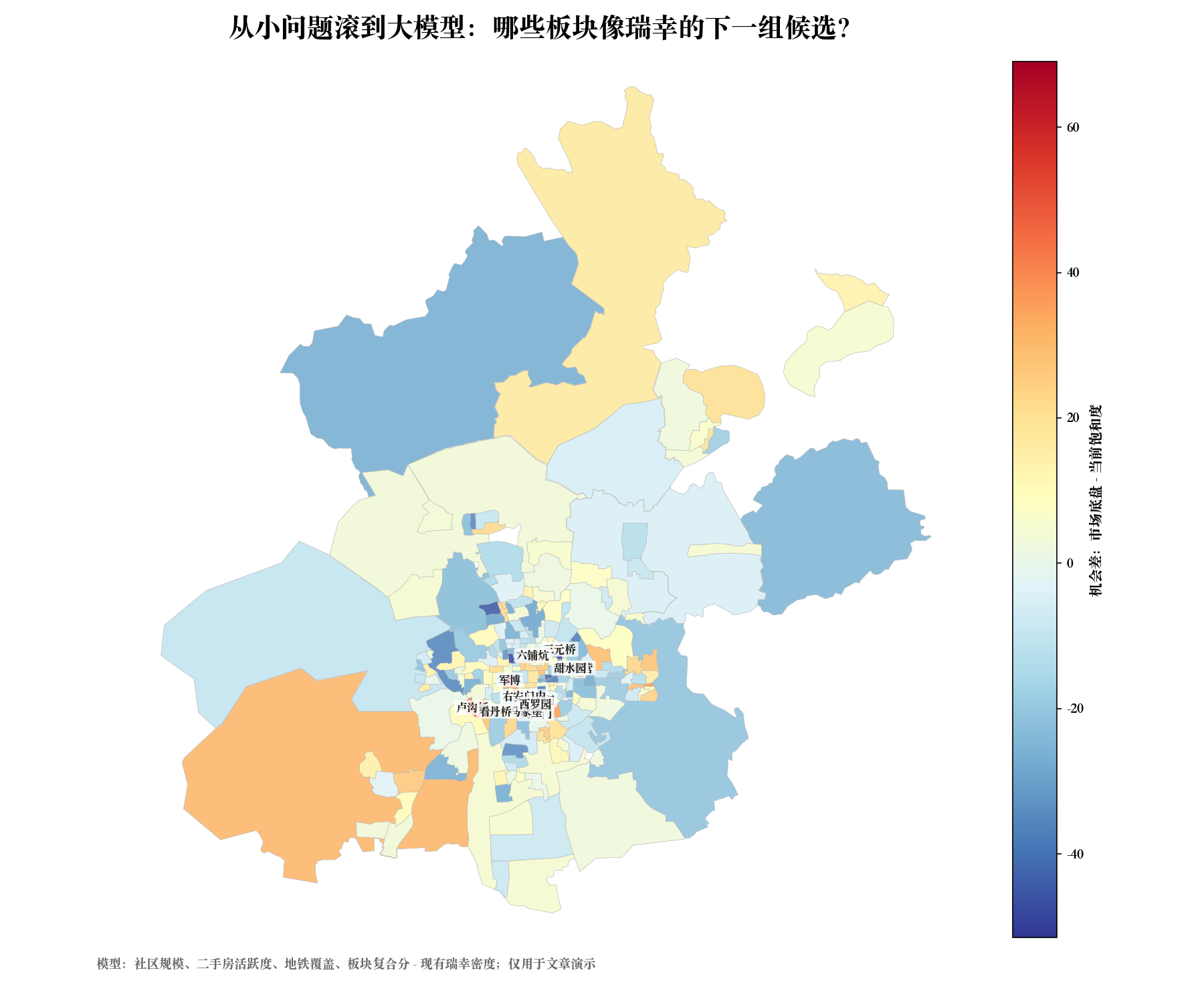
这一步的快乐很强。因为你能看见一个抽象判断被压成了地图。
任务 4:先从地图回到候选清单
第五个提示词:
把机会差最高的板块列出来。每个板块给我现有瑞幸数、小区数、地铁覆盖率和一句模型解释。
坐标修正后,板块层 候选包括:
- • 军博:板块底盘强,地铁覆盖约 90%,现有瑞幸覆盖低;
- • 永定门:小区约 75 个,地铁覆盖约 82%,社区底盘很厚;
- • 甜水园:轨道友好,且现有瑞幸覆盖低;
- • 看丹桥:小区和地铁条件都进入观察区;
- • 西罗园、卢沟桥、石佛营、六铺炕、马家堡、三元桥等也进入候选。
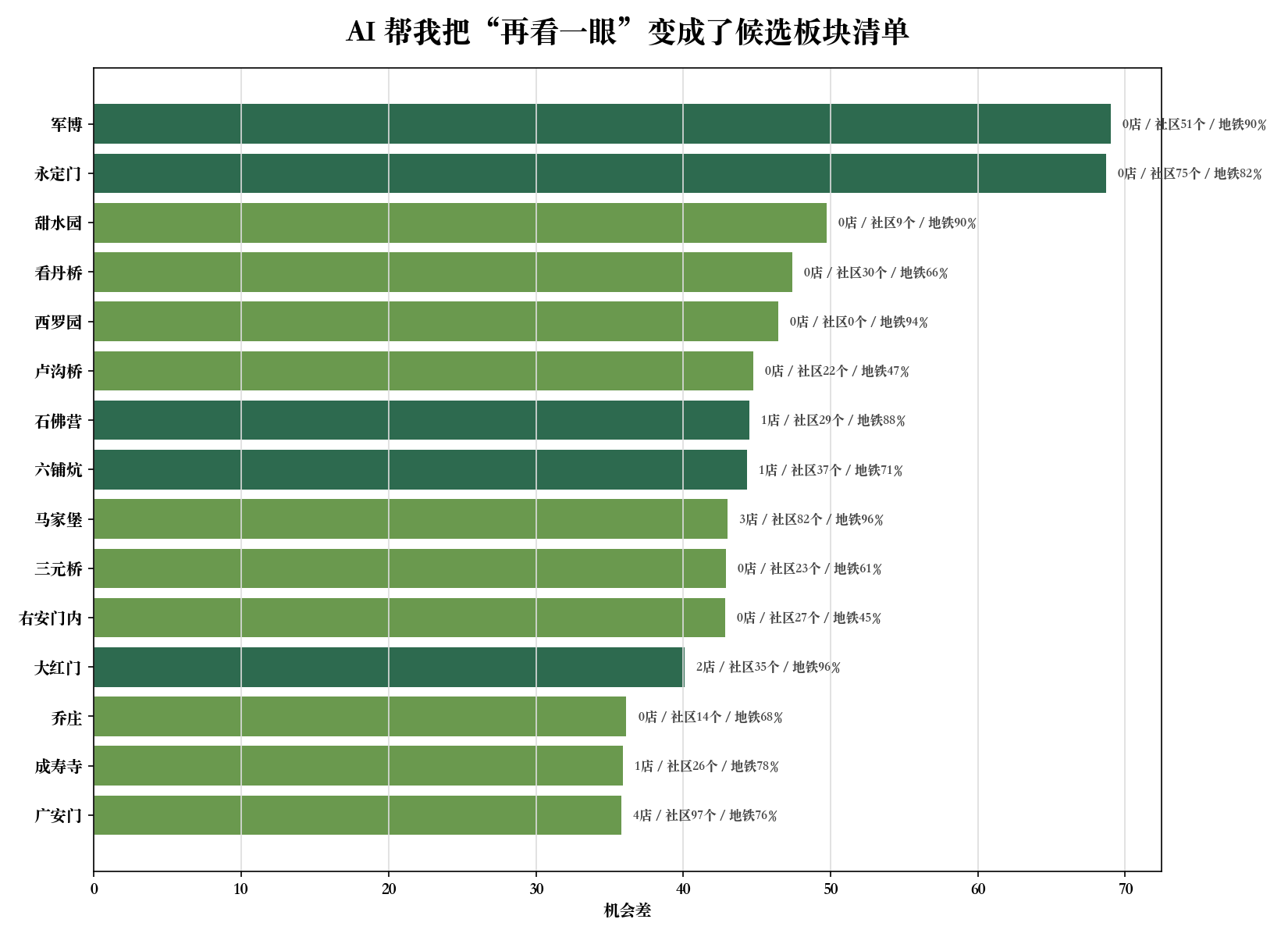
看到这里,任务已经从“做一张图”变成“做一套品牌位置分析样机”。
但这还不是最有意思的地方。
板块适合讲故事,却不适合直接指导实地动作。一个板块可能很大,里面有办公区、老社区、学校、商场、断头路和纯居住片。真正去看店,不会说“去望京看看”,而是要问:“望京里的哪一个微片区值得先走一遍?”
于是我加了一个更细的数据:geohey block.gpkg,也就是最小单元的商圈。
任务 5:从板块下钻到集店圈
第六个提示词:
用极海最新版的北京集店圈做微片区模型。每个商圈接入瑞幸数、小区数、600m 地铁站数和所属板块分,给我实地验证候选。
这一步把分析粒度从 255 个链家板块,下钻到 15048 个北京集店圈。
模型逻辑也稍微变了:
- • 板块负责“底盘”:这个地方大方向是否成熟;
- • 集店圈负责“落点”:这个微片区附近有没有小区、地铁和低覆盖;
- • 瑞幸现有门店负责“饱和度”:如果已经有店,就降低优先级;
- • 最后输出的是“可以去实地验证”的微片区,而不是宏观板块。
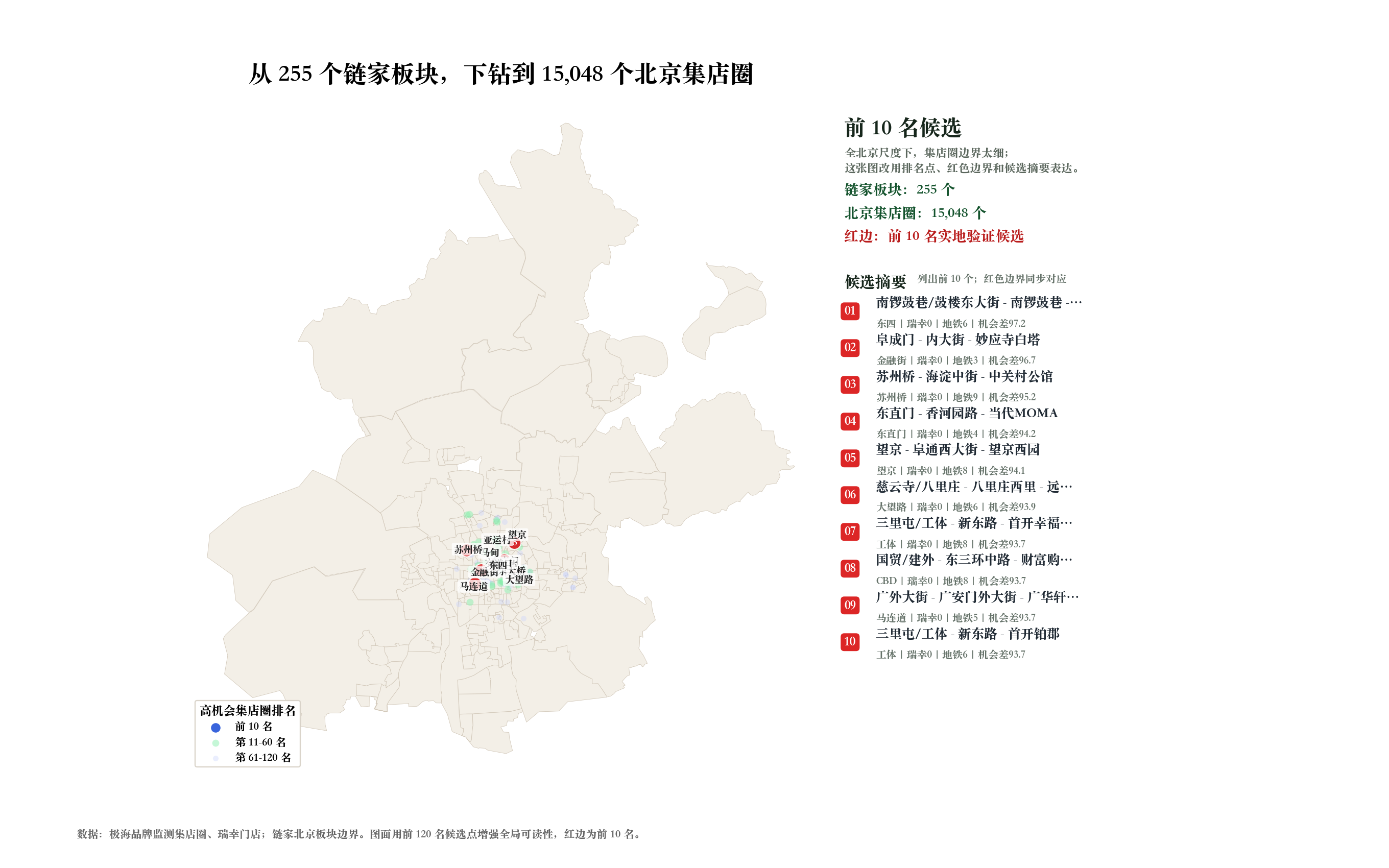
这个下钻动作很有心流感。
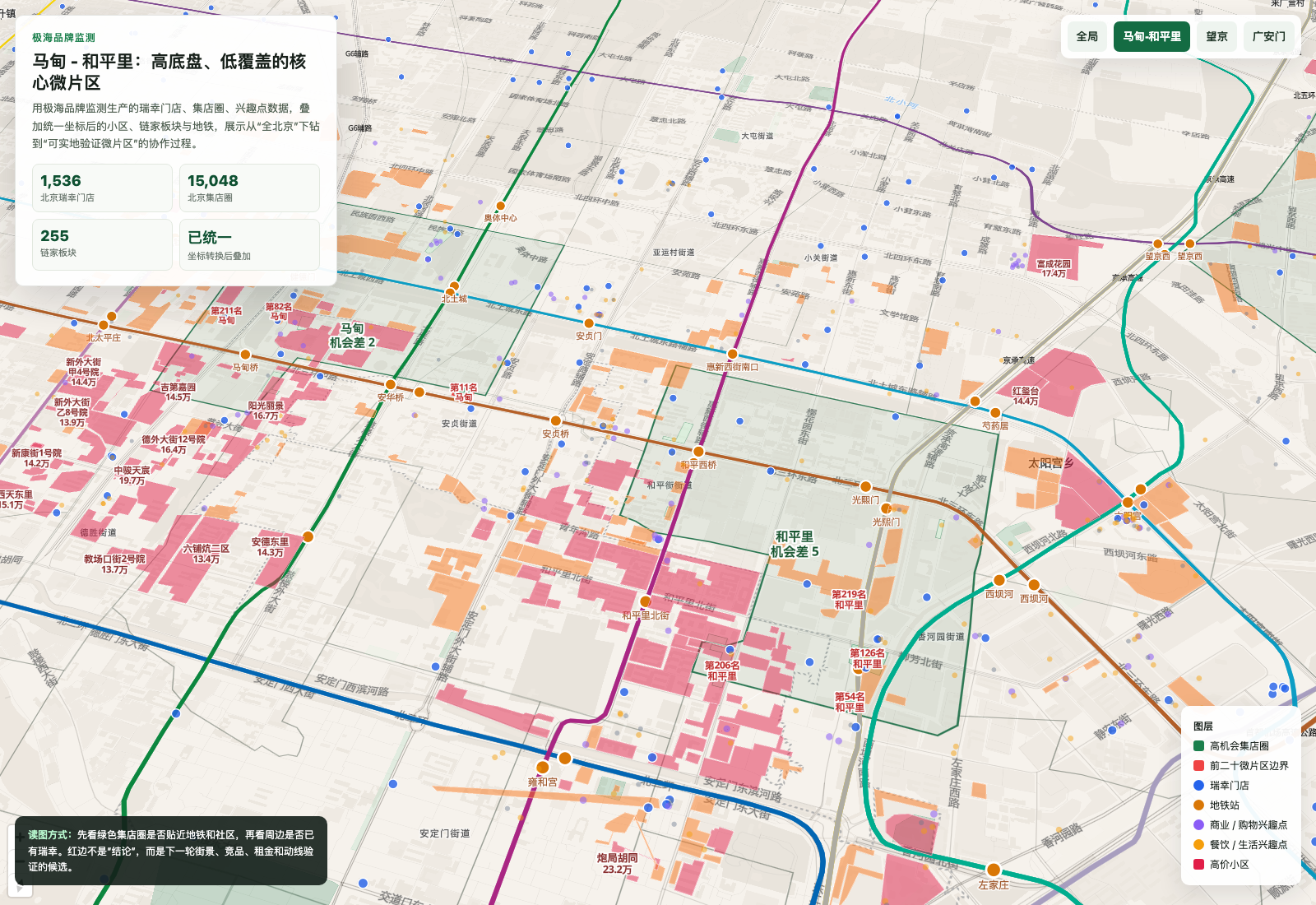
因为你会感觉自己从一张概念地图,进入了城市的毛细血管。结果不再只是“马甸、和平里、望京、广安门这些板块值得关注”,而是“马甸和和平里里的某几个集店圈,周边小区、地铁和 兴趣点 都强,但瑞幸覆盖仍低,可以作为下一轮街景和实地验证对象”。
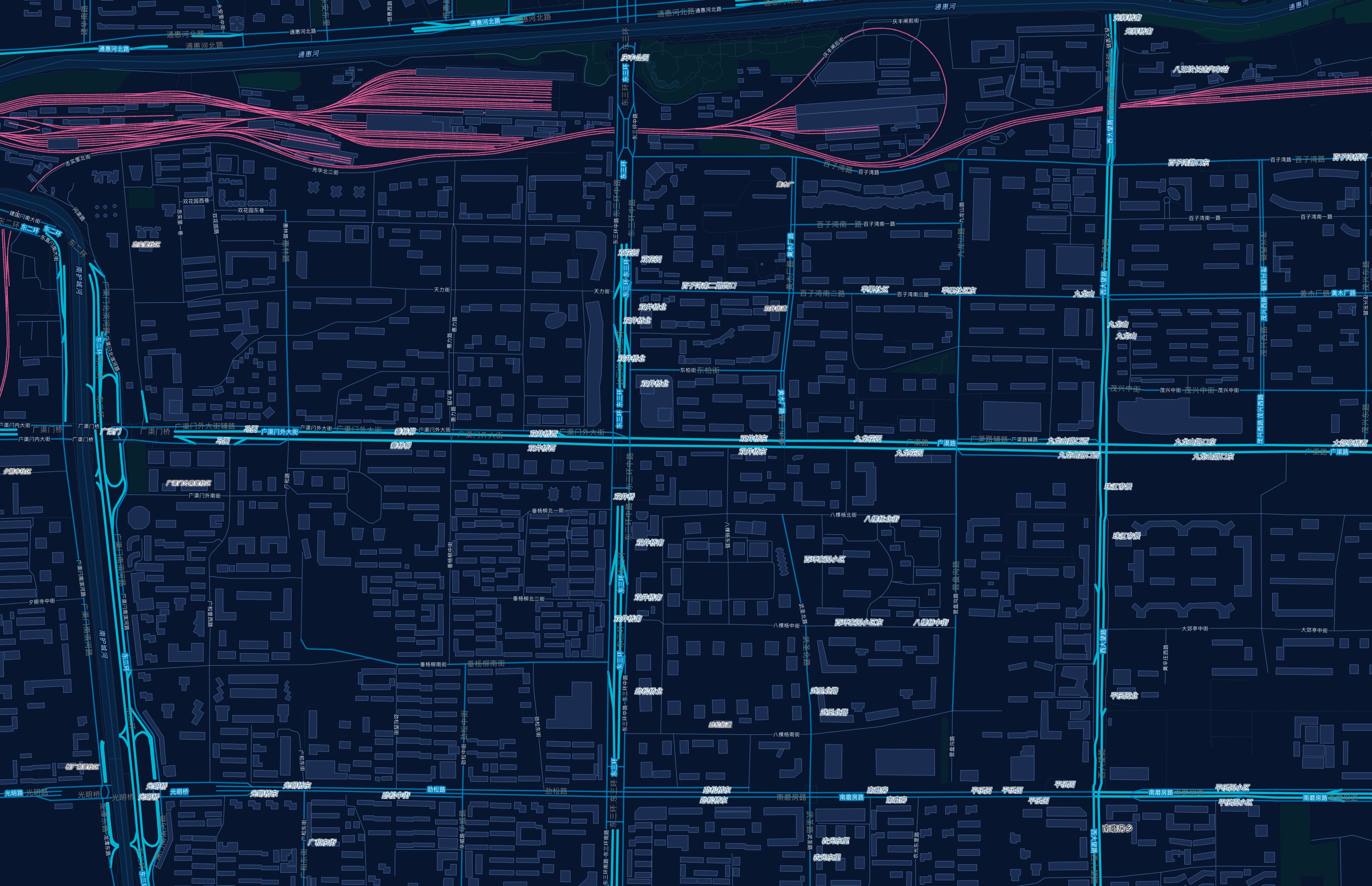
比如马甸-和平里这张放大图,读者终于能看见“为什么”:高机会微商圈贴着地铁线、小区和商业 兴趣点,周边已经有城市生活密度,但绿色瑞幸点并没有把所有微片区填满。
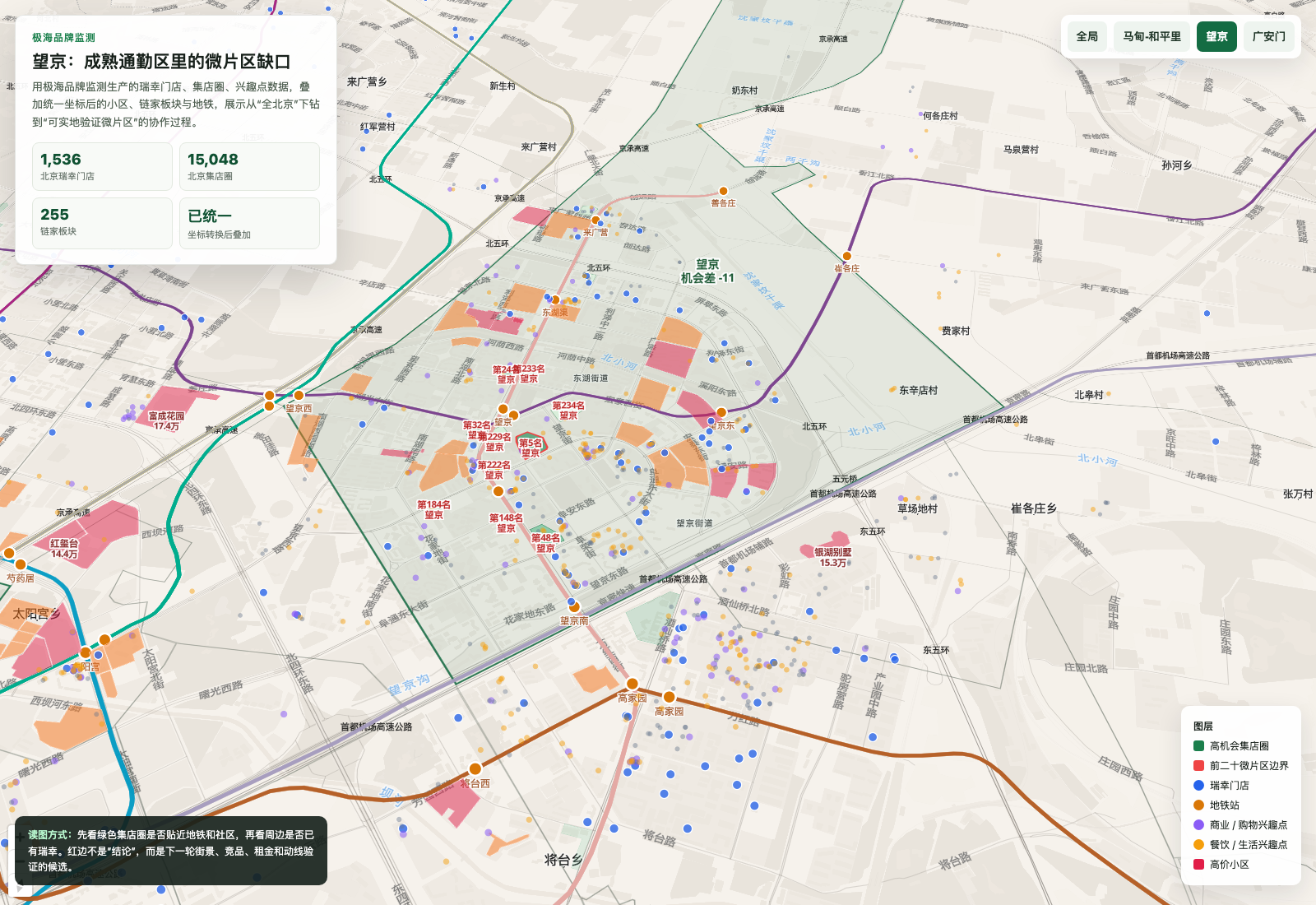
望京则是另一个典型:它不是“没有瑞幸”的地方,而是成熟通勤区里仍有局部微片区缺口。全北京图看不出来,放大到街区尺度才有感觉。
广安门这张图,则把高房价小区、地铁走廊、商业/生活 兴趣点 和候选微片区叠在一起。它让“高底盘低覆盖”不再只是一个分数,而是一组肉眼可见的城市关系。
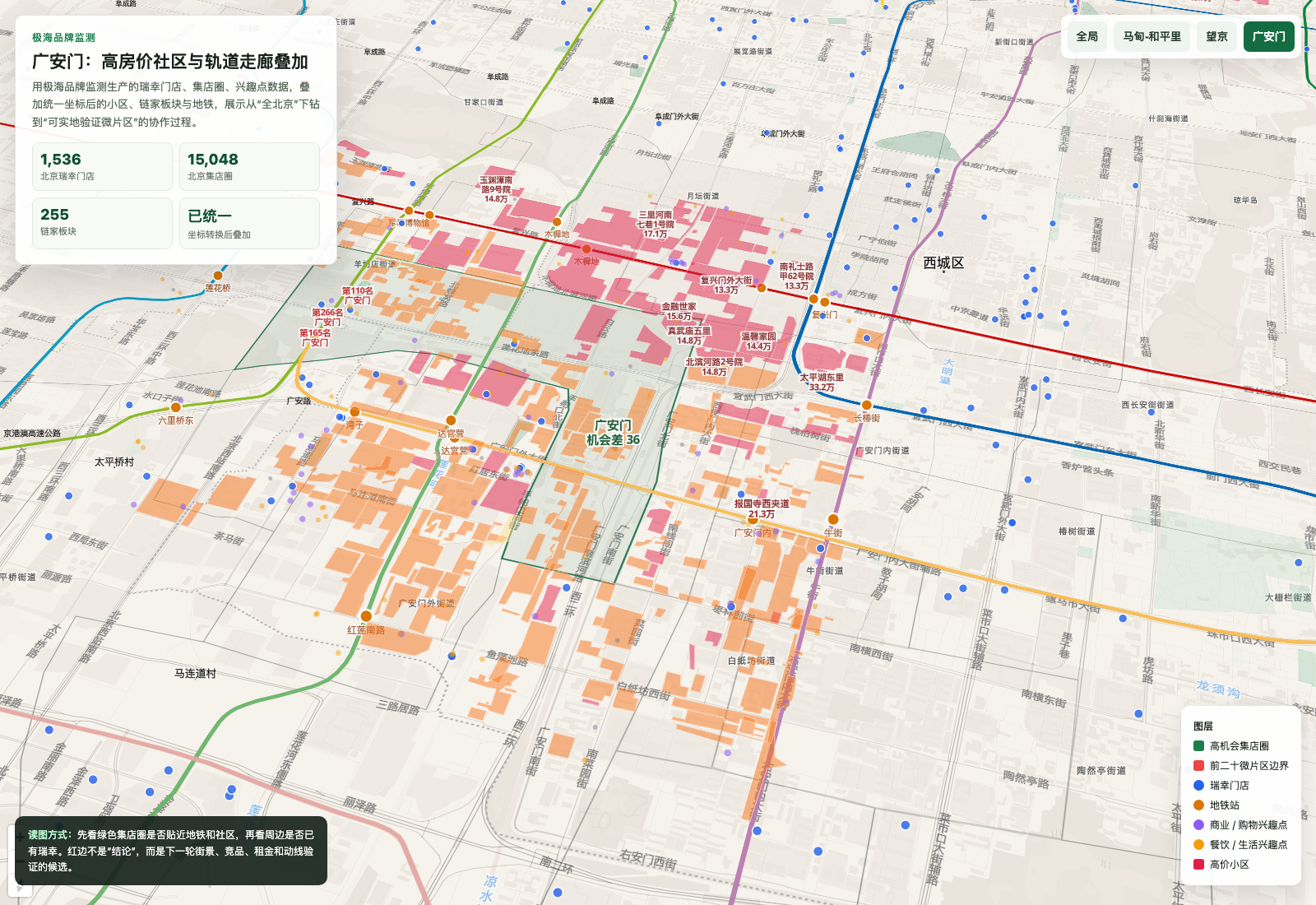
这就是小任务滚成大货的典型时刻:我本来只是想画一张瑞幸地图,最后却拿到了一个“板块方向 + 微片区候选 + 下一步实地验证”的工作流。
最后把所有的故事再整理修改一下,增加飞行到前20个潜力集店圈位置的功能,完整的WebGIS 应用可以发布了:
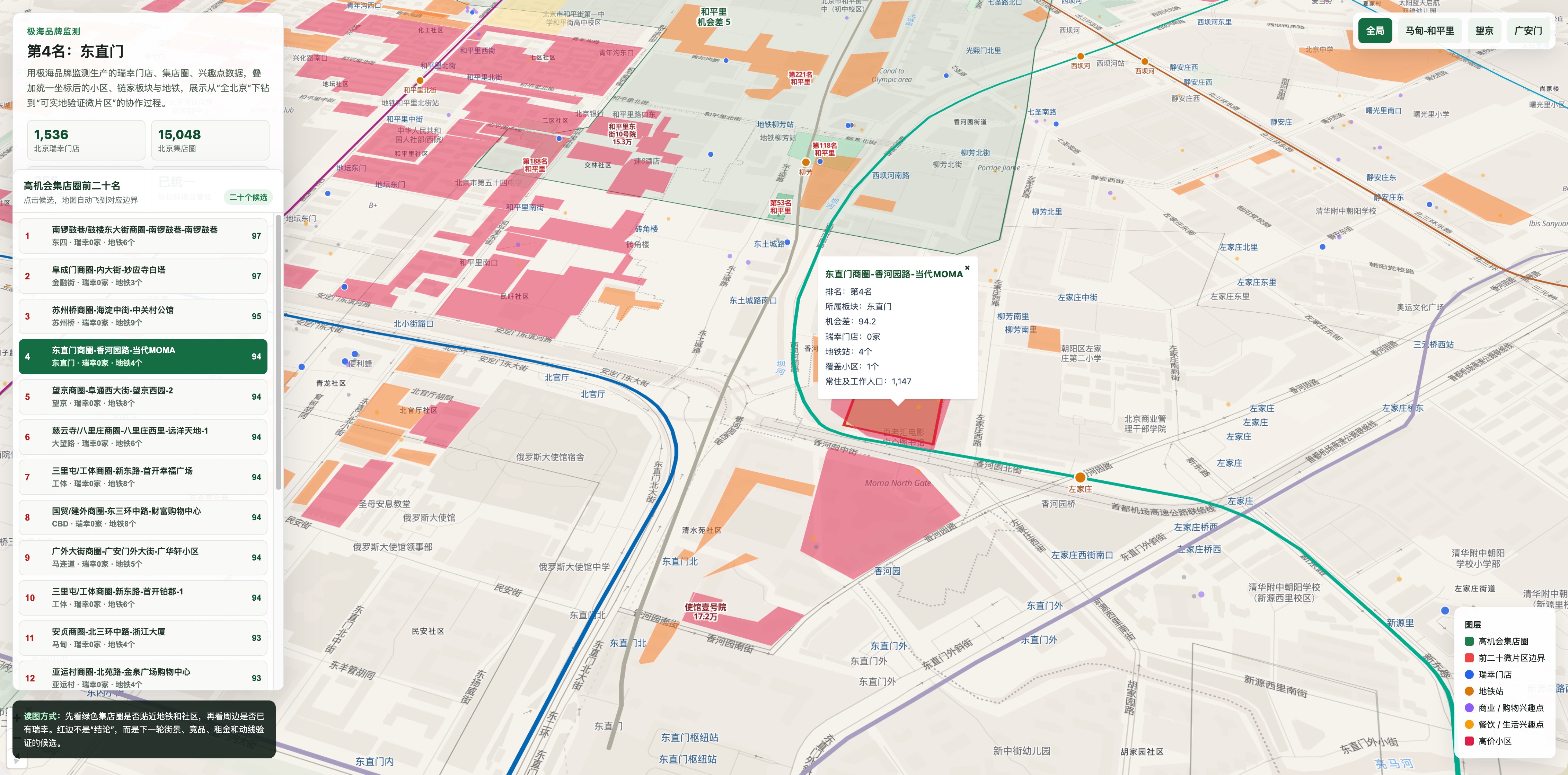
这就是 AI 协作的滚雪球效应:每一步都不大,但每一步都给你一个新的问题。
任务 6:把过程写成一个可复用提示词链
如果你也想试,可以照着这个节奏来。
第一步,只做归属:
读取品牌门店经纬度和城市板块边界,做空间连接,输出每个板块的门店数、门店密度和无门店板块清单。
第二步,加一个城市机制:
接入地铁站和地铁覆盖指标,分析品牌门店与轨道交通的关系。请区分“门店数多”和“单位面积密度高”。
第三步,加生活底盘:
接入小区数量、房价、二手房活跃度,构造一个社区复购潜力指标。先用百分位标准化,不追求商业完美。
第四步,做机会差:
构造市场底盘分和当前饱和度分,输出机会差。请列出 前 15 个候选,并解释每个候选的风险和下一步验证方式。
第五步,画图:
输出公众号可用地图:先给全北京监测总览,再给重点区域放大图。地图要有 GIS 图层感:底图、地铁、小区、兴趣点、品牌门店、集店圈边界和标签。
第六步,下钻:
接入集店圈边界,把板块机会分传导到微片区。每个微片区统计品牌门店数、小区数、600m 地铁站数,输出 实地验证候选。
第七步,坐标质检:
检查各图层坐标系。瑞幸、集店圈、兴趣点是 GCJ-02;小区、板块、地铁是 WGS84。请统一到 WGS84,再重新做空间连接和地图。
第八步,复盘:
把这次分析过程写成一篇分析报告,重点不是品牌结论,而是分析师如何借助 AI 探索品牌门店的分布规律和潜在机会。
真正的收获不是地图,而是注意力的重新分配
这次模拟里,AI 做了什么?
它做了空间连接、字段检查、模型计算、地图输出、结果整理。它很快,很耐心,不怕重复,也不会抱怨我临时多加一个变量。
我又做了什么?
我决定问题往哪里走。我判断哪些变量有意义。我决定粗糙模型能不能先用。我看着地图提出新的疑问。我把结果放回真实商业语境里。
这就是我觉得最值得分享的地方:AI 不是把人从思考中解放出来,而是把人从低价值负荷中解放出来,让人更容易进入高价值负荷。
万老师说,主动高认知负荷就是手动开启注意力的 Pro 模式。我的理解是:
AI 帮你把“找资料、接字段、画草图”的外在负荷降下来;你把省下来的注意力,投入到建模、解释、质疑、迭代这些增益负荷里。
于是工作不只是工作,它会变成一种探索游戏。
这也解释了为什么我会停不下来。
以前一个复杂 GIS 任务,中间有太多等待和卡顿:数据跑不通、字段对不上、图出不来。卡顿会自然打断我,让我明天再说。
现在 AI 把这些卡顿变短了。一个任务刚出结果,下一个更有意思的问题已经出现。多巴胺来自“它马上就能跑出来”,内啡肽来自“我终于把这个问题拿下了”。
这确实能提升幸福感。
但要补一句:不要把心流误用成熬夜。
高认知负荷是快乐的源泉,不是无限加班的借口。最好的做法是给 AI 协作加一个收束提示:
现在不要继续扩展任务。请帮我整理今天已经完成的结果、明天最值得继续的 3 个问题,以及一个可以放心停下来的保存点。
这句话很重要。
因为真正成熟的 AI 工作流,不是让你永远停不下来,而是让你知道:今天已经有了一个阶段性大货,明天还能从一个清晰的上下文继续进入心流。
我的结论是:幸福感不一定来自少工作一点。有时候,它来自更少空转、更少内耗、更少无聊等待,以及更多主动建模、即时反馈、持续征服。
当 AI 把世界的摩擦降下来,我们要做的不是把脑子也交出去。
我们要把自己的注意力,调到 Pro 模式。