
信任机器智能的决策得看下一代人了
现如今,我们每天都说这是一个数据充斥一切的时代,机器学习与大数据技术的崛起一定会为商业决策和城市规划带来了前所未有的精准度和智能化。然而,正如任何技术变革一样,当这些复杂的算法与传统的人类认知交汇时,摩擦与冲突随之而来。在我们看来,尤其是在商业选址、城市分区等本来高度依赖数据的领域,企业和组织面临着一个艰难的困境:如何在机器智能的精确性与人类决策者对简单逻辑和因果关系的偏好之间取得平衡。
机器智能的精确性与人类认知的困境
机器学习,特别是深度神经网络(DNN)等方法,展现出了超乎想象的强大能力。通过处理多源大数据,这些模型能够捕捉复杂的非线性关系,从人口统计到社交媒体数据,无所不包。这种计算能力使其在城市分区和商业选址等场景中大放异彩。以餐馆选址为例,传统的分析方法,在美国如 Esri、尼尔森等制作的基于普查数据和地理位置的目标市场细分,可能会根据社区的收入水平、家庭结构等因素,将某个街区标注为“富裕家庭”或“年轻单身者”的居住地,从而得出该区域适合高端餐饮或快餐连锁店的结论。
Esri的这个分类叫做Tapestry Segmentation 是英文中的“挂毯”之意,象征着一种缤纷、复杂的图案和故事。Esri 选择“Tapestry”命名其市场细分系统,意在比喻美国社区的多样性,就像一块色彩斑斓的挂毯,展示了不同社区的社会经济地位、人口特征和生活方式的交织。Segment 则是“分段”的意思,指的是将美国各个社区根据相似的特征划分为不同的“段”或“群体”,即市场细分。
Esri 的 Tapestry Segmentation 系统基于地理、人口统计和生活方式等变量,将美国社区划分为 67 个细分市场,并进一步归类为 14 个生活模式组(LifeMode Groups)和 6 个城市化组(Urbanization Groups)。每个细分市场反映了社区的独特性,帮助我们理解社区的复杂社会经济动态。

esri总部所在地的市场细分地图(引自esri官网)
这种分类方法一看便懂,既有可解释性也有可操作性。你家产品的目标人群就在那里呢,到这个社区开店即可。但你也一定会质疑,在一个地块居住和工作的人,林林总总,就这三言两语就能概括?相比之下,机器学习模型则更加复杂和精确。它们能够结合人口动态、交通流量、竞争对手分布、社交媒体趋势等多维度数据,预测出一个特定区域的潜力。例如,模型可能发现一个非直观的结果:虽然某个区域的居民收入中等,但由于高社交媒体活跃度和较低的竞争密度,该区域的餐馆将很有可能成功。这样的结论,通过深度神经网络的“黑箱”计算得出,通常难以被人类理解和信任。
简化模型的吸引力:Esri Tapestry Segmentation 的实例
尽管机器学习方法拥有更高的精度,但像 Esri Tapestry Segmentation 这样简化的模型仍然在商业决策(美国的情况)中占据重要地位。这类模型通过将美国社区划分为 67 个细分市场,帮助商业决策者快速理解社区的关键特征。例如,富裕庄园(Affluent Estates) 这一细分市场描述的是高收入、高消费家庭,他们重视高品质服务和产品。这样的分类既直观又易于理解,为商业决策者提供了一种快速评估社区潜力的工具。
LifeMode 1: Affluent Estates(富裕庄园)
描述:
- 这个细分市场代表的是受过良好教育、富有、且经常旅行的已婚家庭。
- 社区中不到 10% 的家庭占据了 20% 的家庭收入。
- 近 90% 的居民为房主,其中 65.2% 负有房贷。
- 这些家庭通常是有孩子的已婚夫妇,孩子的年龄从小学到大学不等。
- 他们重视高质量的服务,愿意投资于节省时间的产品和服务。
- 他们积极参与社区事务,喜欢运动,热衷于旅行。
再次说说这种简化的分类模型明显的优势。首先,它易于操作和解释。决策者可以直接根据分类结果采取行动,而无需深入理解复杂的算法。其次,模型的输出符合人类大脑对因果关系的偏好。我们倾向于相信“富裕社区=高消费能力”这样的简单逻辑,而非深度学习模型中那些难以解释的非线性关联。
然而,正如我们通过两个 Tapestry 细分市场(富裕庄园与市区单身群体)的分析所揭示的,简化模型虽然方便,但也存在明显的不足。它们容易忽视社区内部的多样性和动态变化,过度简化了复杂的社会经济现实。例如,富裕家庭可能存在不同的消费偏好——有些追求奢华,有些则强调环保和节俭。而市区的年轻单身群体也并非都偏好廉价品牌,其中部分人可能愿意为时尚和品牌买单。这些细致入微的差异,往往在简化的模型中被忽略。
商业决策的未来:机器预测与人类决策的结合
尽管当前的现实是简化模型更容易被接受,但不可否认,未来的商业决策将不可避免地朝着“机器预测+人类决策”的模式演进。随着机器学习算法的不断发展和数据科学的普及,企业将逐渐认识到这些技术带来的效率和质量提升。在一个竞争日益激烈的市场中,能够更精准地预测消费者行为和市场趋势,将为企业带来巨大的优势。
然而,要实现这一点,企业需要解决一个关键问题:如何让人类决策者信任机器的预测结果。目前,深度学习模型的“黑箱”特性让其难以被人类理解和接受。决策者常常质疑模型的输出,尤其是当这些结果与他们的直觉和经验相悖时。即便模型的预测更为精准,缺乏可解释性的结果仍然会引发不信任。
机器学习方法:深度神经网络模型预测商业选址
对于极海这样长期积累大量地理位置、人口数据的创业企业,很容易就想到使用深度学习模型,从多个维度的数据中找到更加精准开店位置的选址方案。比如这个模型可能会结合以下几类数据:
- 人口统计数据(如年龄、收入、教育水平)
- 地理数据(如交通流量、商业密度、竞争对手位置)
- 社交媒体数据(如在某个区域的流行趋势、餐馆评分)
- 实时动态数据(如腾讯 API 提供的实时人口流动、消费热点等)
通过这些数据,深度神经网络可以自动学习和捕捉到复杂的非线性模式,预测出最有可能成功的开店位置。模型可能会基于数百万个数据点,通过多层神经网络的计算,输出一个难以用人类语言描述的结果——例如,某个特定街区的一个特定位置是最佳选址。
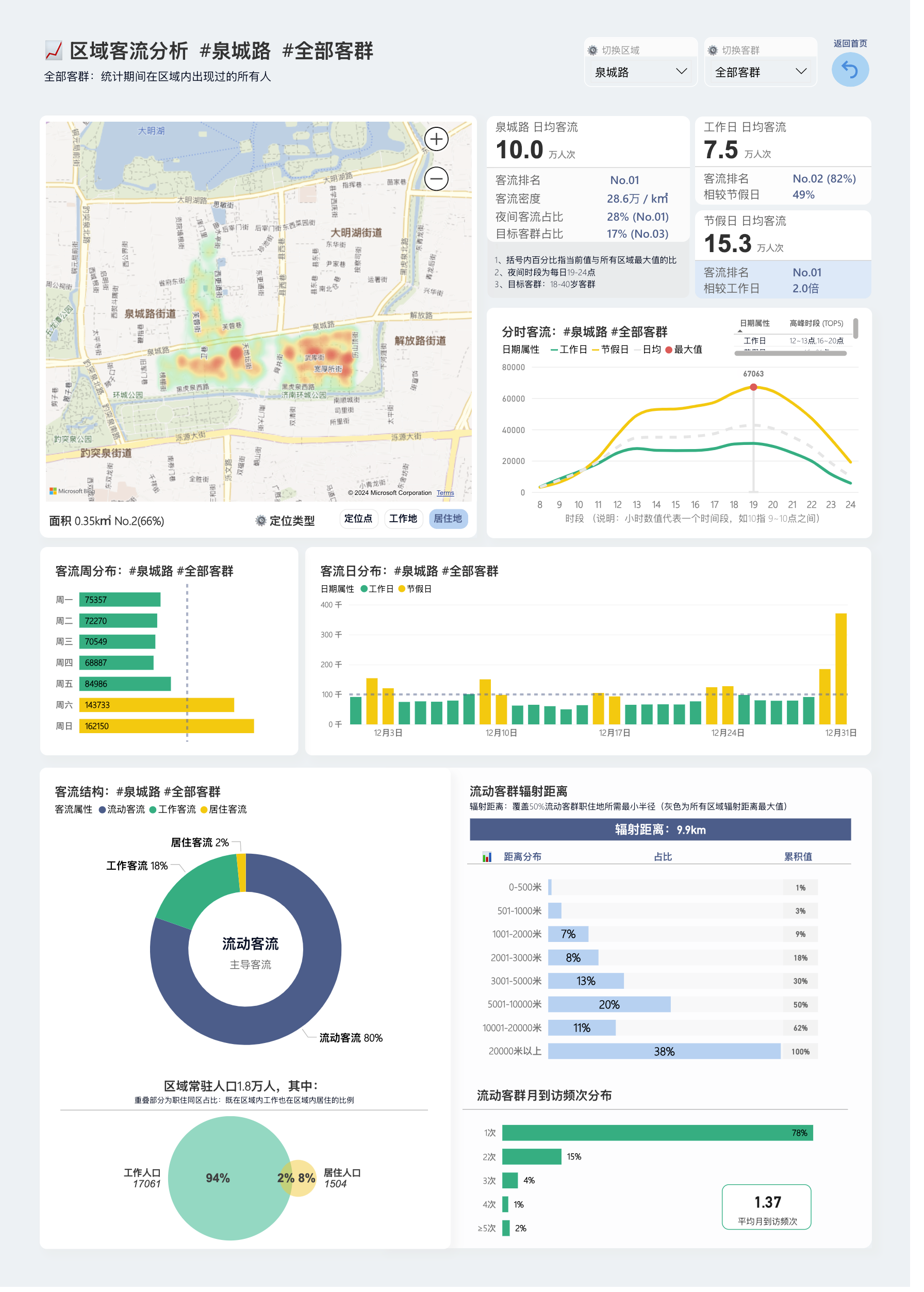
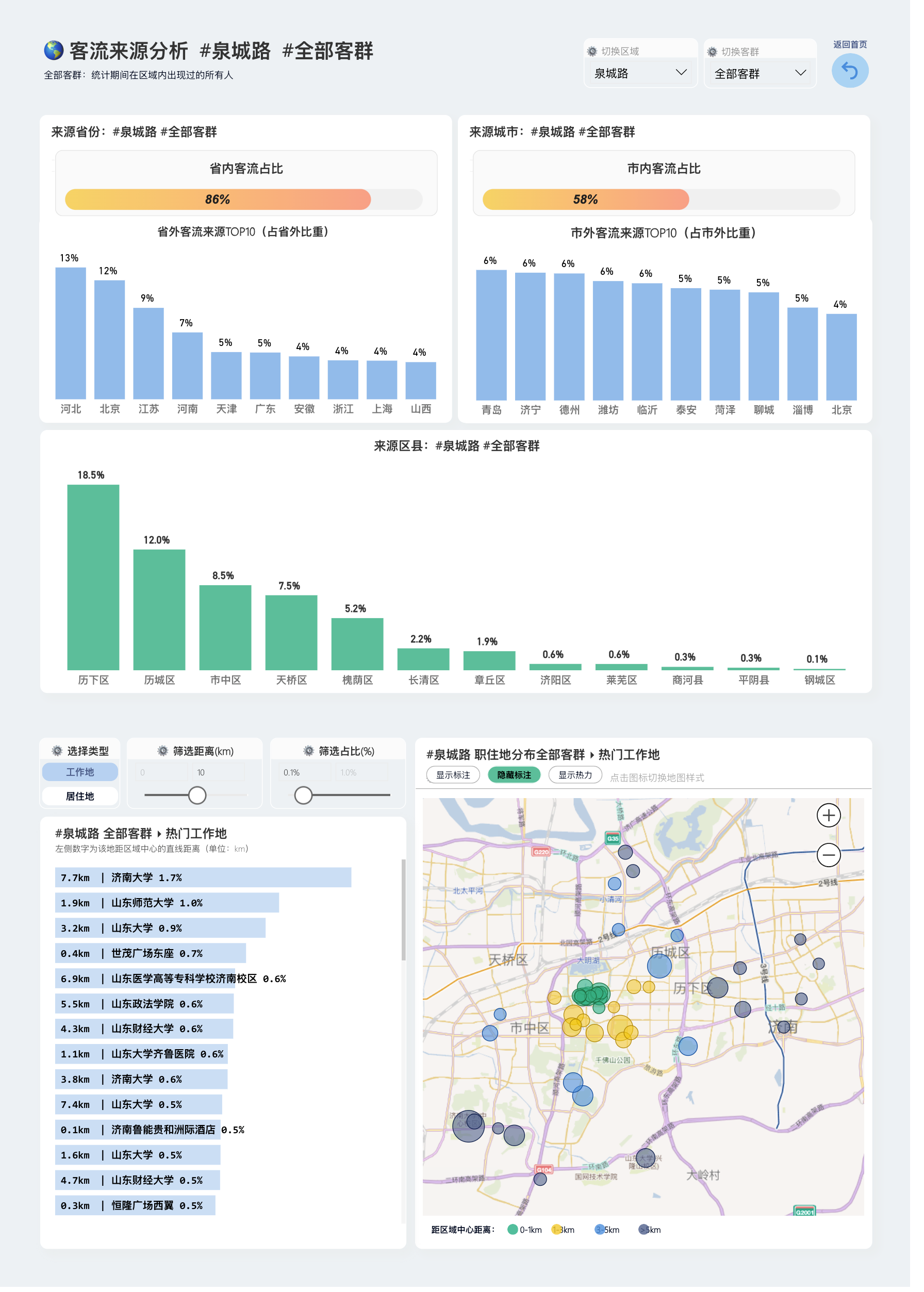
极海人群细分动态交互报告,访问地址:在这里
仅仅是一个客流数据就有若干维度需要表达,还要加上另外三大类数据协同分析,不借助机器学习的算法是无法精准计算的。但这么多维度压缩成一个结论就不是人脑容易理解的了。
为什么这种方法更精确?
- 高维度与复杂性捕捉:深度学习可以处理大量的复杂因素,并通过其多层的结构自动学习到数据中的隐含关系。例如,模型可能会发现一个很难通过传统分析得出的结论:某个区域的中等收入群体,虽然不符合传统的高消费人群标准,但由于该区域的高社交媒体活跃度和较低的竞争密度,餐馆可能仍会成功。
- 非线性关系:深度学习能够捕捉到变量之间的复杂非线性关系。比如,交通流量、社交媒体评分和消费习惯之间可能存在复杂交互作用,深度学习模型能够通过训练自动调整权重,找到这些因素之间的最优组合,而不是简单地基于某一个变量的高低做出决策。
为什么人类大脑难以理解和接受?
尽管机器学习的结果更精确,但它的复杂性让人类大脑很难理解和信任。这种现象背后有几个原因:
“黑箱”效应:
- 深度神经网络是一个高度复杂的“黑箱模型”,它的决策过程对用户来说是不透明的。即使是模型的设计者,也很难解释每个输入变量是如何影响最终输出的。比如,领导可能会质疑:“为什么模型预测这个位置是最佳的?它具体是基于哪些因素得出的结论?” 而模型可能无法提供一个简单、直观的答案。
- 人们习惯于线性思维,喜欢看到明确的因果关系。例如,某个社区的高收入人群更可能接受高端餐饮服务——这是一个简单易懂的逻辑。然而,深度学习模型可能会基于众多复杂且非线性的关系进行计算,得出结论时并不依赖于这种简单的因果推理,从而让人难以理解。
缺乏可解释性:
- 尽管深度学习模型得出的预测可能非常准确,但它无法提供人类易于理解的解释。对于许多企业领导来说,理解模型的决策依据是信任模型的前提。如果模型无法提供清晰的解释,领导很可能会选择更易理解的传统方法,即使这些方法的预测结果不如机器学习模型精确。
- 举个例子,如果模型预测某个位置适合开店,但无法解释为什么,决策者可能会认为该模型不可靠,尤其是在该预测与他们的直觉或经验相悖时。
认知偏差与过度简化的偏好:
- 人类大脑喜欢简化复杂事物,倾向于寻找简单的因果关系(如“高收入社区=高消费能力”)。复杂的机器学习模型打破了这种简单的因果推理,提供的是基于数千个变量的高维度、多层次的结果。这种复杂性超出了人类大脑的认知舒适区,容易引发不信任。
- 例如,领导可能更愿意相信一个具有传统统计分析背景的报告,如“基于人口统计学和收入水平,这个地区适合高端餐饮”,而不是接受一个无法解释、但预测准确的深度学习模型。
模型结果的不一致性:
- 机器学习模型可能会随着数据的变化而给出不同的结果,尤其是在实时数据输入的情况下。领导可能会质疑:“为什么上个月模型说这个位置好,而现在又变了?” 这种结果的不一致性,虽然在数据科学中是合理的,但在人类的商业决策中往往被视为不稳定或不可靠的表现。
故事的力量与机器智能的融合
正如认知心理学指出的那样,人类大脑天生倾向于寻找因果关系和简单的叙事。我们更容易接受“高收入社区适合高端餐饮”这样的明确逻辑,而不是一个基于复杂算法得出的模糊预测。因此,在推行机器智能的过程中,企业不仅要依赖数据和算法,还要运用故事的力量。
这意味着,提供基于机器学习的服务时,企业需要找到一种将数据背后的逻辑转化为易于理解的叙事方式。尽管深度学习模型的输出可能难以解释,但可以通过将关键数据点转化为直观的故事来增强其说服力。或许模型无法解释每个变量的权重,但企业可以通过场景化的描述,帮助决策者理解为什么某个区域适合开店。这种结合了数据和故事的方式,不仅能够提升模型的可解释性,还能增强人类对机器智能的信任。
结语:数据与故事的平衡
也许对深度学习算法的理解、对机器智能的信任,这一代人怎么都做不到自然流畅了。但在未来,其实就在当下的商业决策中,数据驱动的机器智能将不可避免地占据重要地位。然而,机器预测的精确性与人类大脑对简单因果关系的偏好之间的冲突,仍然是这一领域面临的最大挑战之一。我们必须认识到,尽管机器学习模型能够捕捉到复杂的非线性模式,我对下一代人非常乐观,不过人类决策者对简单逻辑和故事的需求不会改变。因此,企业在构建基于机器智能的数据产品时,必须找到一种平衡,在提供精确预测的同时,也要通过叙事让其结果更容易为人类所理解和接受。
正如 Esri Tapestry Segmentation 这样简化的模型能够通过精炼的描述赢得用户的信任一样,未来的机器学习应用也需要结合复杂数据与直观叙事的双重力量,才能真正改变商业决策的方式。