
一个脚本,你就是拥抱AI的GISer了
上周我写了一篇文章,说GIS从业者面对AI时的那种茫然感,本质上是认知层面失去了坐标参考系。文章发出来之后,收到两份私信:
一个说"你写得对,但你没给解药"。
另一种更直接:"道理我都懂,你给我看个具体的。"
想想也是,大道理说了一箩筐,不如来点实在的。罗胖老师常说:一具体就深刻。这周我就给具体的。
今天下午发生的事
上周末我打开QGIS,准备做一张全国地级市GDP分级地图,一张霸王茶姬全国分布图,还有几家门店的辐射范围图(简单buffer)。手边有几样东西:一份整理好的全国345个地级市十年GDP的Excel表格,一份地级行政区矢量底图,还有霸王茶姬门店的分布列表,同样也是Excel的。
这种活儿我做过无数遍了。流程烂熟于心:加载矢量图层,转换Excel,再导入CSV,字段关联,设置分级渲染,选色带,调断点,出图。每次大概要二十分钟到半小时,取决于数据脏不脏、要不要重投影。
但这次我换了一种做法。
我写了三个脚本,让本地跑着的大模型替我干了三件事。整个过程,从写脚本到地图渲染完毕,没有打开任何一个工具箱对话框。
这不是什么"AI重构工作流"的宏大叙事。就是三件小事,三步台阶。
第一步:别再手查EPSG了
GIS从业者有一个共同经历:你拿到一份经纬度数据,要做缓冲区分析,第一件事是什么?
投影转换。从WGS84转到一个以米为单位的投影坐标系,否则buffer出来的是个椭圆。
问题是——转到哪个投影?
如果数据在北京,你可能条件反射地知道是UTM 50N,EPSG:32650。但如果数据在乌鲁木齐呢?在昆明呢?在海口呢?
大多数人的做法是打开搜索引擎,输入"昆明 UTM zone"或者"EPSG 云南",然后在一堆结果里找到那个六位数编号,复制,粘贴到QGIS的重投影对话框里。
这件事每次花两分钟。一年做一百次,三个小时就这么没了。
现在的做法:脚本里嵌了一个本地大模型调用。你只需要告诉它"这份数据在云南",模型返回一个EPSG编号,脚本自动验证这个坐标系是否有效,然后直接执行重投影。
整个过程三秒钟。其实关键就是把那些拿不准的,没有提前准备好的答案转给一个大模型的API。实在是简单(模型随便,我选了个免费的):
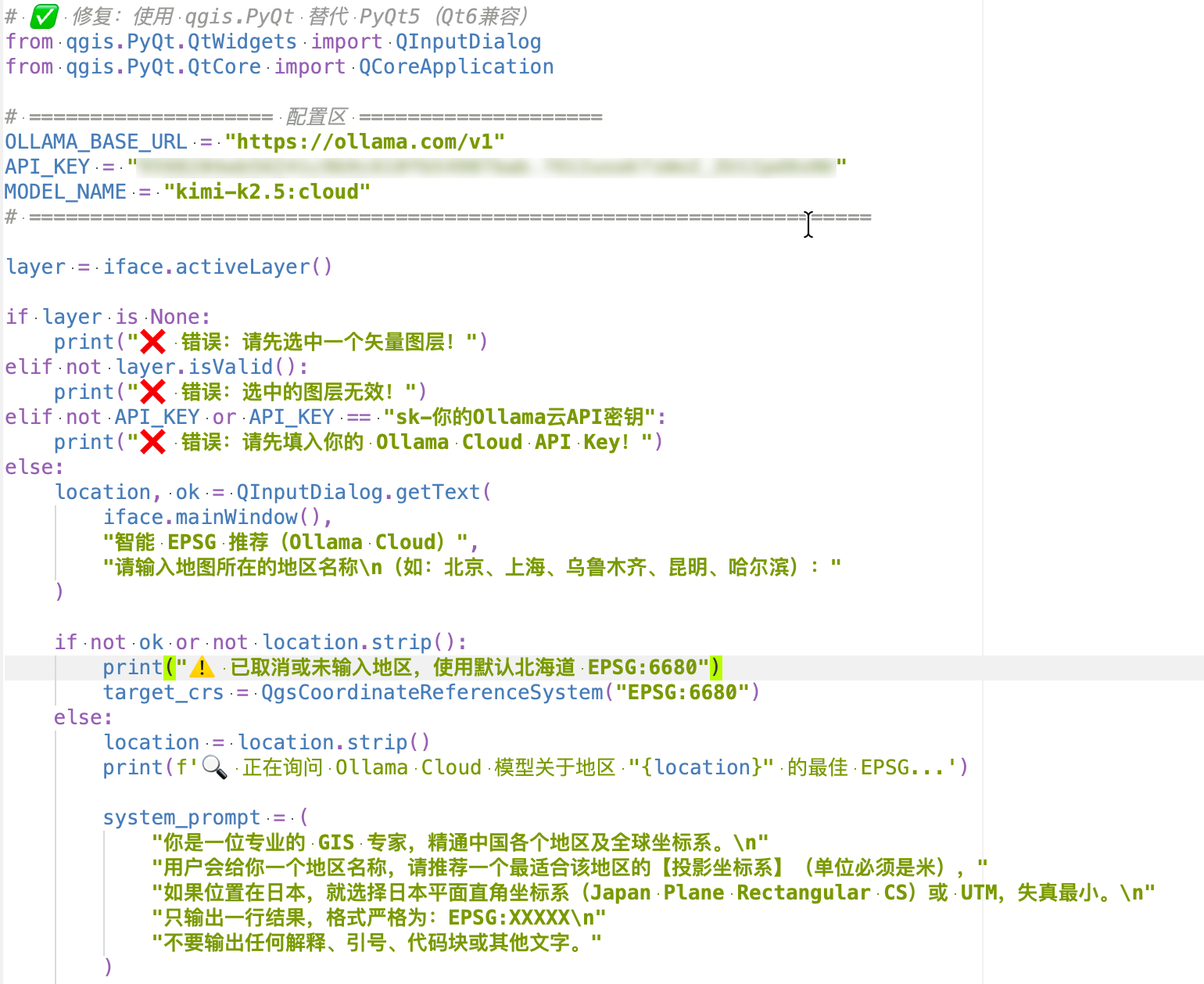
代码只有一个函数。它问模型一个问题:"这个地区最适合用什么投影坐标系?只输出EPSG编号。"模型回答,正则提取,验证,完事。模型不可用?兜底用UTM 50N,也不会崩溃。
这就是上周文章里说的"低惊讶闭环"。你不需要理解Transformer架构,不需要知道什么是temperature和top_p,你只需要知道:有一个东西能帮你查EPSG,而且比你自己查更快。
第二步:一键从Excel到地图
第二个场景更日常。
假设你手头有一份品牌门店数据的Excel,里面有经纬度、营业状态、门店名称。你想把它加载到QGIS里,按营业状态过滤,在地图上显示为彩色散点。
传统做法是什么?
打开Excel,另存为CSV。加载CSV到QGIS,设置X/Y字段,选坐标系。然后打开图层属性,进入符号设置面板,选一个颜色——等等,这个品牌的主色调是什么?瑞幸是蓝色还是灰色?霸王茶姬是红色还是棕色?打开浏览器,搜索"瑞幸咖啡品牌色",找到一个十六进制色值,复制,粘贴到颜色选择器里。
现在的做法:脚本从Excel文件名自动提取品牌名,调用本地大模型获取品牌主色调,自动匹配经纬度列,自动过滤营业状态,一键生成带品牌色的点状符号图层。
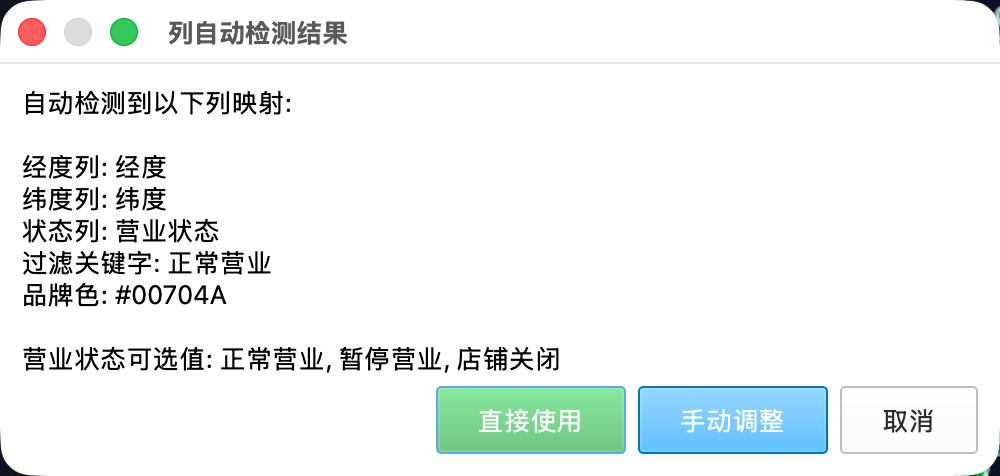
模型在这里做的事非常简单:你告诉它"瑞幸咖啡",它告诉你"#0078D4"。就这样。脚本里预置了二十个常见品牌的颜色缓存,命中缓存连模型都不用调。只有遇到不认识的品牌才会问模型。
以及是不是做Draw Effect,stroke的line多粗多细,你都可以设置默认或者自动智能化的。
有人可能会说,这不就省了查颜色那三十秒吗?
不只是三十秒。关键在于流程连续性。原来从"拿到Excel"到"看到地图"之间有六七个手动步骤,每一步都可能被打断——列名不对、坐标系没选、颜色不满意。现在是一个入口进去,一张图出来。你的注意力始终在 "数据本身",而不是在"工具怎么操作"。
第三步:让AI帮你挑色带
第三个脚本是这次折腾时间最长、但效果最好的一个。
做分级色彩地图时,每个GIS从业者都面对过这组选择题:
- 分几级?5级?7级?10级?
- 用什么分级方法?自然断点、等间距、分位数?
- 用什么色带?红黄?蓝绿?光谱色?
这些选择没有标准答案。取决于数据分布、取决于你想表达什么、取决于审美偏好。大多数人的做法是反复试:选个色带,看看效果,不满意,换一个。有时候调到凌晨三点,就为了让深色底图上那些面状色块既能区分,又不刺眼。
现在的做法:脚本先统计数据的分布特征——均值、中位数、偏度、四分位数——然后把这些统计量丢给本地大模型,附带一句你的偏好,比如"绿色系,10级,等间距"。模型看完数据后,输出一个分级方案,包含方法、级数、色带名称和一句理由。
我测试了一下2024年全国344个地级市的GDP数据。数据偏度3.53,极度右偏——少数城市GDP极高,大量城市集中在低区间。
当我什么偏好都不给的时候,模型推荐了Jenks自然断点、5级、黄到红色带。理由是"右偏分布适合自然断点,暖色调渐变适合单一指标的量级展示"。
当我输入"绿色系 10级 等间距"的时候,模型直接尊重了我的要求,选了Greens色带、10级、等间距。理由是"尊重用户明确要求"。
当我什么都不说只选了2025年的时候,模型推荐了Jenks自然断点、7级、紫色系。理由是"数据呈右偏分布,Jenks算法能识别数值聚类特征,配合7级紫色系色带可清晰展示层级差异"。



三次都不一样。三次都说得出道理。而且整个过程里,我没有打开过一次"符号"面板。
台阶,而不是天梯
回到上周的话题。
上周说的是,GIS从业者面对AI时的阻力,不是因为懒或者固执,而是因为认知落差太大——那个空白输入框,就像一个没有坐标参考系的空间。
这周做的三个脚本,本质上是在做一件事:把那个空白输入框变回GIS从业者熟悉的操作面板。
不需要你知道怎么写prompt。不需要你理解模型背后的原理。你只需要运行一个脚本,它问你两个你本来就知道答案的问题——数据在哪个省?你想要什么颜色?——然后帮你把从前需要手动操作十分钟的事情在三秒钟内完成。
这就是我说的台阶。
不是从地面直接跳到楼顶的天梯,是一步一步、每步都踩得到的台阶。你脚下踩的还是GIS——QGIS还是那个QGIS,投影还是那个投影,分级渲染还是那个分级渲染——只不过中间有些步骤被模型接管了。
而且是本地模型。跑在你自己机器上的,不传数据、不用付费、甚至不要联网(Ollama本地模型测试也都OK)。QGIS的Python控制台就能运行,不需要装任何额外的软件。
一个更深层的变化
不过我觉得最值得说的,不是效率提升本身。
是使用过程中出现的一种微妙的变化:你开始用自然语言思考GIS操作了。
以前你的思维路径是:打开工具箱 → 找到"重投影"工具 → 选源图层 → 选目标坐标系 → 运行。这是一个工具驱动的路径,你的思考跟着界面走。
现在的路径是:我想把这份数据转到适合云南的投影。说完这句话,事情就发生了。
这个变化看起来很小。但它意味着一个根本性的转向:从"我要怎么操作工具"变成了"我想对数据做什么"。
工具在退向后台。意图在走向前台。
上周文章的结尾,我说分水岭不在"会不会AI",而在"面对不确定性时能不能用最小成本迈出一步"。
这三个脚本,就是最小成本的那一步。
它们不完美。匹配算法遇到"巴音郭楞蒙古自治州"和"巴音郭楞州"的时候需要查找表兜底。大模型有时候思考太久、JSON被截断,需要把超时时间拉长。数据缺口需要额外一轮搜集。
但它们跑起来了。地图渲染出来了。而且下一次再做同样的事情,不需要重新开始——脚本在那里,模型在那里,你只需要改一个Excel路径。
上周结尾我说,试着今天就问AI一个你工作中的小问题,只一个就够了。
这周我想把这句话说得更具体一点:那个"小问题"不用找,它就在你每天的琐碎工作里。
你每次查EPSG编号的那两分钟,是一个小问题。你每次从Excel另存CSV再手动加载的那五分钟,是一个小问题。你每次在色带列表里反复切换、对比、拿不定主意的那十分钟,也是一个小问题。
这些小问题太小了,小到你从来不觉得它们是"问题"——它们只是工作的一部分,是你早就习惯的操作成本。
但它们加在一起,就是你和AI之间最短的那段距离。
因为它们足够小,所以试一次不会有任何风险。因为它们足够日常,所以你不需要专门腾出时间"学AI"——下次做这件事的时候,顺手试一下就行了。
不需要全部三个脚本。就从最简单的那个开始。
然后你会发现,原来这件事真的没那么复杂。