
用机器学习做靠谱的聚类——谱聚类(Spectral clustering)
前段时间,在参与一个项目的过程中无意间接触到了谱聚类(Spectral clustering)。大神说:这种聚类区别于“系统聚类”和“k-means聚类”等传统聚类方法,它的计算量小、对数据分布的适应性强、聚类效果好,并且通过MATLAB或者sklearn的机器学习算法都能够实现。这么高大上的聚类算法岂是我等线代学渣所能驾驭的?但是,孔子曰:“学渣也要有春天!”,于是我便查阅了大量和谱聚类相关的文章和资料,跋山涉水、翻山越岭之后,还是觉得——孔子说得对啊!

一、谱聚类是啥概念?
谱聚类:是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类。即把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
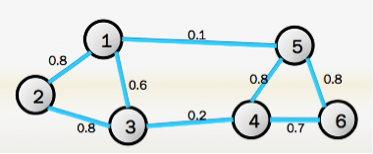
图论:对于一个图G,一般用点的集合V和边的集合E来描述,即为G(V,E)。其中V即为数据集里面所有的点(v1,v2,...vn)。对于V中的任意两个点,可以有边连接,也可以没有边连接。如下图所示:
拉普拉斯(Laplacian)矩阵:定义拉普拉斯矩阵L=D−W。D为度矩阵,W是邻接矩阵。
那么,度矩阵D是啥?
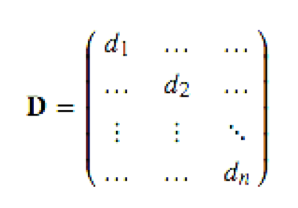
对于有边连接的两个点Vi和Vj,Wij>0,对于没有边连接的两个点Vi和Vj,Wij=0。对于图中的任意一个点Vi,它的度di定义为和它相连的所有边的权重之和,即:
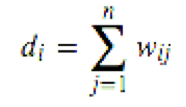
那么,邻接矩阵又是啥?
由任意两点之间的权重值Wij组成的矩阵。即距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,因此可以通过样本点距离度量的相似矩阵S来获得邻接矩阵W。构建邻接矩阵W的方法有三类。ϵ-邻近法,K邻近法和全连接法。
-
ϵ-邻近法:即设定一个距离阈值,小于阈值的权重为0,大于阈值的权重为ϵ;
-
K邻近法:取样本点中的k个最邻近点计算权重(又分为单邻近和互邻近)。
-
全连接法:样本中一个点与其他所有点都连接,并计算相应权重。
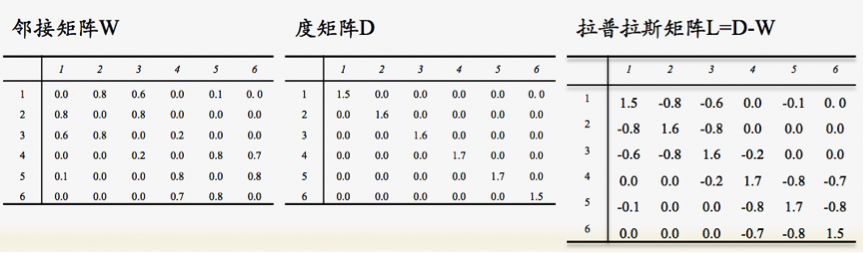
最后,上一张L,D,W全家福:
二、切图
当前面的工作都做好了以后,接下来就是做分类,谱聚类分类的方式为“切图”,如图:
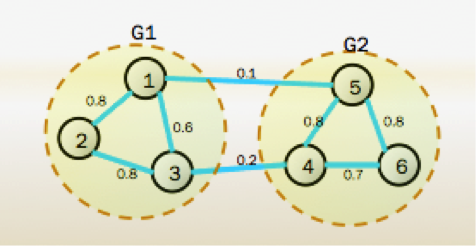
切图的原则:同子图内的点相似度高,不同子图的点相似度低。与传统聚类组内离差平方和最小、组间离差平方和最大类似。切图的效果可用损失函数来评价,即划分时子图之间被“截断”的边的权重和:
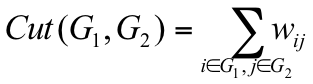
切图的方法有多种,这里主要介绍Ratio cut和Ncut(Normalized Cut)两种:
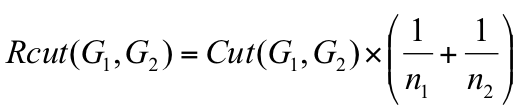
n1和n2为划分到子图1和子图2中的顶点个数。
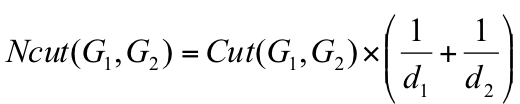
d1和d2分别为子图1和子图2的权重和。
由以上两个公式,结合切图的原则可知,Ncut的方法较好。
综上所述,谱聚类可以理解为:降维过程+其他聚类方法,常用的聚类方法为K-means,需要注意的关键点是邻接矩阵的生成方式、切图的方式和最后的聚类方法。
三、实例
本次谱聚类主要使用了python机器学习sklearn里的方法,需要注意的是sklearn库的版本必须在0.18.1以上,否则无法调用metrics调参。由于sklearn的SpectralClustering方法已经把谱聚类的相关算法封装好,所以我们在通晓了以上谱聚类的基本原理之后,再结合sklearn的官方文档调整并设定好SpectralClustering方法中的参数即可。
import pandas as pd
from sklearn.cluster import SpectralClustering
from sklearn import metrics
from sklearn import preprocessing
输入数据:北京大型商场“均价比较指数”、“户数比较指数”、“母婴店铺比较系数”等8个特征的数据,样本容量为81。
目标:对商场进行聚类。
步骤:
1.先对数据进行标准化处理。
2.调整参数:
此处结合数据分布特点选取了K邻近法来构建邻接矩阵(即affinity=’nearest_neighbors’,默认为高斯函数’rbf’),因此需要调整的参数为“n_clusters”和“n_neighbors”。做循环之后结果如下:

通过调参,可以看出在n_neighbors=11且n_clusters=4时,Calinski-Harabasz Score最大,因此n_neighbors设为11,n_clusters设为4,其他参数为默认即可(默认聚类方式为k-means,切图方式为N-cut)。
y_pred=SpectralClustering(affinity='nearest_neighbors',n_clusters=4, n_neighbors=11).fit_predict(X)
3.分类结果:

注意:每次运行程序,可能分类的标签不一样(即0-3的标签是随机的),但是聚类结果都是一样的。
GeoHey上图:
参考资料: