
做一个好决策很难,你更愿意依靠谁?
本周最大的话题是北京会不会封城。如果一天新增的感染数量超过了150人,要不要全体居家,这个决策让你来定,你会怎么定?对,比你更高阶的领导已经授权了,你就是最终决策者,这个时候你要怎么思考?怎么行动?
绝大部分人一辈子也不会为做这样的决策而痛苦。但请想象一下这个场景:你手头正在用的笔记本电脑今天死活点不亮了,它已经为你奋斗了5年;你打算还是不再检修换件了,换一台吧,也为此准备好了一定的银子。你最后决定买的是联想?小米?还是苹果?你打算问问周边达人的建议还是自己从小红书上找找哪个博主种的草最香?选好的型号是从京东上下单买一台全新的还是在咸鱼上转转,找一台八成新但便宜好多的?巧了,你本人就是电脑硬件爱好者,这些“业务”你都熟悉的紧,平常你都是在给别人当推荐达人,你不需要这些纠结。那你想象一下如果要送给给女友或太太一支口红做礼物,你怎么做选择?类似这样的情景,我们倒是家常便饭似的碰到。

日常生活中买些小物件,从买什么牌子,花多少钱,到去哪儿买顶多算是个决定,远算不上决策。决定错了,狠狠心可以重新买;决定对了,愉悦一下自己或者周边的人,也就是一时的开心。不说北京封城这样的大事儿,那决定要不要背上很重的贷款买房呢?替老爸老妈拿主意把大半的积蓄掏出来在老家加盟一个连锁品牌呢?那你是只愿意听心中直觉的声音,还是要去找找“明白人”咨询一下?或者用比较长的时间认真做做功课?
工作中很多场景虽然不都像买房投资需要那么仔细的盘算,但大部分的决定也不像买支口红这样简单。用什么样的人,做什么样的研发,布什么样的局,放弃什么样的业务,这些都需要做决策,后续的影响可能也会很重大。就拿我们业务中常见的连锁品牌拓店决策为例:你作为品牌主,是先把一个城市继续增加密度、做大做深,还是稍有规模就将全国铺开作为第一优先级?铺开的顺序是从一线城市开始还是从品牌基地所在城市的周边省份做起?可能你觉得自己就是明白人,那你更信任自己的经验还是更想参考一下当地的“明白人”?
当我们给自己打的标签是“明白人”时,我们更愿意相信自己的感觉,我们可以说这种感觉就是直觉,说不清道不明但有时候就是能看的又快又准。比如选址专家到了这个街区一转,多年的眼力和体验,告诉Ta这个地方就是靠谱。可能恰逢下午四点接孩子的家长和孩子们一起正熙熙攘攘穿街而过,可能是华灯初上频频有豪车缓慢停下,礼让着行人再拐入邻近的小区。这是一种让自我满意的情感体验,也是一种令人愉悦的一致感,它使我们感觉我们所考虑的证据和做出的判断是正确的,就如同玩拼图游戏时拿起来的碎片恰好都对应到了该有的位置上一样。

近几十年来的研究表明,人类的大部分思维,包括一些更高层次的认知操作(比如决策),都可能是无意识的,这已经成为现代认知科学的一个核心原则。推理不再被视为完全有意识或深思熟虑的过程。相反,意识只是头脑的“车间”,而来自“内部”的信号在为个人的判断和决策提供潜在指导的“控制面板”。直觉就是这样一种信号,它是所谓的“智能——无意识”的一种能力——它不要你的“干预”即可以控制你的车间。直觉是一种对特定行为的判断,它带有一种光环或对正确似是而非的信念,但没有清楚阐明的理由,也就是本质上“知道”什么,但不知道为什么。
我猜你听说过或者读过诺奖获得者丹尼尔·卡尼曼的经典著作《思考快与慢》,这本书让大众开始对我们人类大脑的一些克服不了的”怪异“有了科学上的认知。这些怪异的效应,丹尼尔老爷子把它们称作偏差(Bias,偏误也行)。丹尼尔去年出了新书,还是在他科研的主赛道上继续给出一些强有力的实例来说明人类在判断力上的缺陷,这个缺陷不是偏误,是另外一种噪声。万维刚老师在《得到 精英日课》第四季已结束的情况下,又给学员们“紧急”做了加餐。万老师是很喜欢这本书的,忍不住在该书英文版出版的第一时间,就给我们这些学生以国内最快的速度丰富一下认知。万老师说:
“偏差和噪声同样重要。哪怕你平时不怎么需要做什么决策判断,读一读、深刻理解此书,也能让你的思维水平上一个台阶。这本书更大的教训可能是你应该养成精确思考的习惯。”

丹尼尔·卡尼曼在这本书的搭档,法国学者和商业专家西博尼随后自己又出了一本书《You're About to Make a Terrible Mistake!》(你要犯一个可怕的错误了!),湛卢的编辑将其中文版取名为《偏差》,台湾天下文化翻译为《不当决策》。在中文的语境中,习惯上都不太喜欢用非常负面的词汇做书名或者公司的Slogan(“不当”算是温和的)。对起书名这一点也是一个“偏差”实例,如何利用或者避免产生我们人脑中的一些不太能解释的下意识感觉——如果直接翻译成《你要犯一个可怕的错误了!》,会使你不想买这本书——你会莫名其妙的觉得买这本书是在犯错误。


在《偏差》这本书里,西博尼总结了5大类24种偏差。本文并不解读这本书,我只举书中一个例子来说明我们大脑中挥之不去的“无脑判断”:
德国的心理学家托马斯·穆斯韦勒和弗里茨·斯特拉克在一项实验中,将受试者分为两组。要求第一组受试者回答的问题是:圣雄甘地去世时年龄是大于还是小于140岁。要求第二组受试者回答的问题则是:圣雄甘地去世时年龄是大于还是小于9岁。很显然,没有任何人会觉得这两个问题很难回答。但是接下来,当研究人员要求受试者估计甘地去世时的年龄时,这两个问题中所用的这些明显荒谬的“锚点”还是对受试者产生了影响:以140岁为锚定数值的那组受试者认为甘地死于67岁(按平均值),而以9岁为锚定数值的那组受试者则认为他死于50岁(按平均值)。实际上,甘地去世时78岁。
众所周知,锚定效应被大量的用于产品定价和谈判报价。不管合理与否,你都受到当下情境中冒出来的数字作为参考锚点,你所做的回应和调整,总是默默的被这锚点所束缚。锚定效应是我们人脑中偏差之一,这还不算是最不容易克服的偏差。我认为最难最难摆脱的偏差是自洽性倾向:维护自己说过观点,表过的态度,支持或反对过的人和事儿——哪怕已经知道自己是判断错了,人人都是死要面子的。
噪声和偏差是人类在做错误决策是一定会碰到的两大天敌。《噪声》和《偏差》都给出了建议和技巧,如何克服认知心理上固有的偏差和你在做判断是要避免的噪声。总结下来,最核心的要点就是:
1、让多背景、多视角的人,多个选项的方案参与到决策中;
2、对决策的因子进行量化,用量化的指标按照流程去决策。
说起量化,我又想起来一本老书(2013年出版),因为这本书帮助我们正确的认识量化,用合适的方法将不容易量化的事物映射成数字,这本书让我大大方方的变成一个贝叶斯主义者:

作者哈伯德在书中介绍的方法算不得复杂,但丹尼尔在《噪声》中的建议相比哈伯德的,就更加的简化,也更容易操作:
第一步,对决策的结论确定若干个评分指标,最好不要超过五个。
第二步,打分,给每个指标设定一个整数分数区间。
第三步,计算总分,也不用加权平均了,简单相加就行。
这么看来,科学决策的基础就得是:要量化,拉出数据清单和列表,选指标。我回想起我们极海陪伴百胜餐饮这些年做智能选址的业务,就是大力投资获取更多相关的数据,将这些数据用先进的技术使得分析师可以高效的调用,让Ta们按照自己的经验和专业知识对不同的数据进行指标化赋予权重,组合成决策建议,用大家都能理解的地图数据图表进行交流,使得大家在决策时能客观参考数据化的事实。这个过程就是在实实在在的实践《噪声》中的决策方法。
但我认为科学的决策要走向下一个阶段了。当量化成了基础,人脑中对于数字的局限和计算的瓶颈就会限制决策的效率。分析师的经验再丰富,但当Ta们需要考虑几十个指标,乃至几百个指标的时候,Ta们一定也会委托机器模型、算法来打分。50个数字的简单加总,也不是手敲计算器,要请Excel的Sum来帮忙的吧。那如果对上海各个商圈的比较,你敢说会比机器做出来的判断更准更快吗?如果再涉及到不同城市的不同业态呢?甚至都不好说怎么比较更合理。
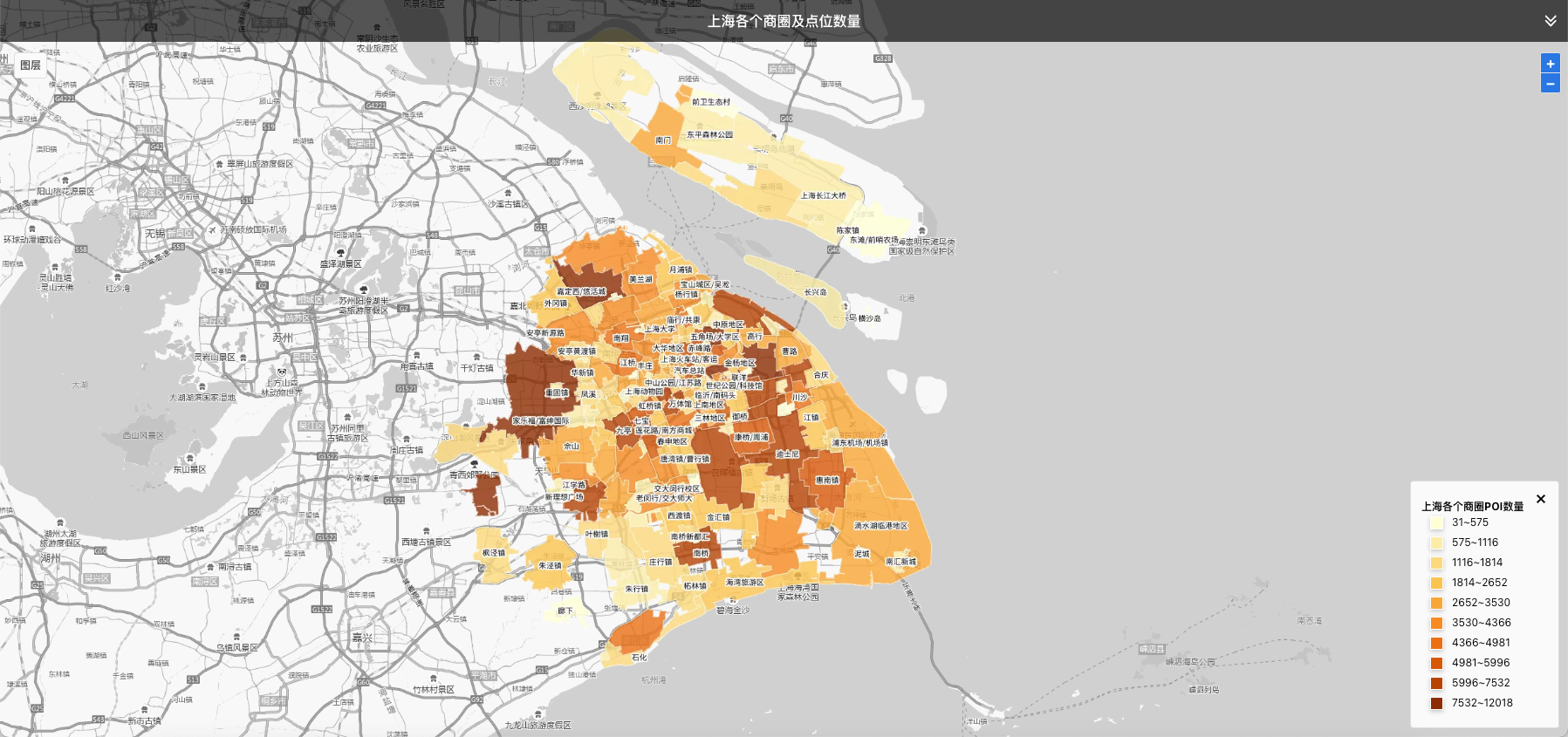
如今我们正处在一个机器智能大发展、而与人类认知激烈交锋也深度融合的阶段。我们几乎一点也不会质疑抖音的算法比抖音的小编更能精准的预测我们看视频的喜好了,但仍然会对一家公司使用算法程序筛选简历而对这家公司心存芥蒂。我们情绪的产生是因为这家公司对人才的不尊重(不用人工就显得不尊重)还是质疑其算法对简历的识别准确度不够高?但至少我自己要承认,包括我在内的大部分普通人对数学还是太“敬畏”了。一个简简单单的线性回归,就要用到偏微分;去实现一个基于线性回归的梯度下降,却不需要10行代码就能实现,这是最最简单的机器学习训练和预测,但我的脑子却需要理解好半天。
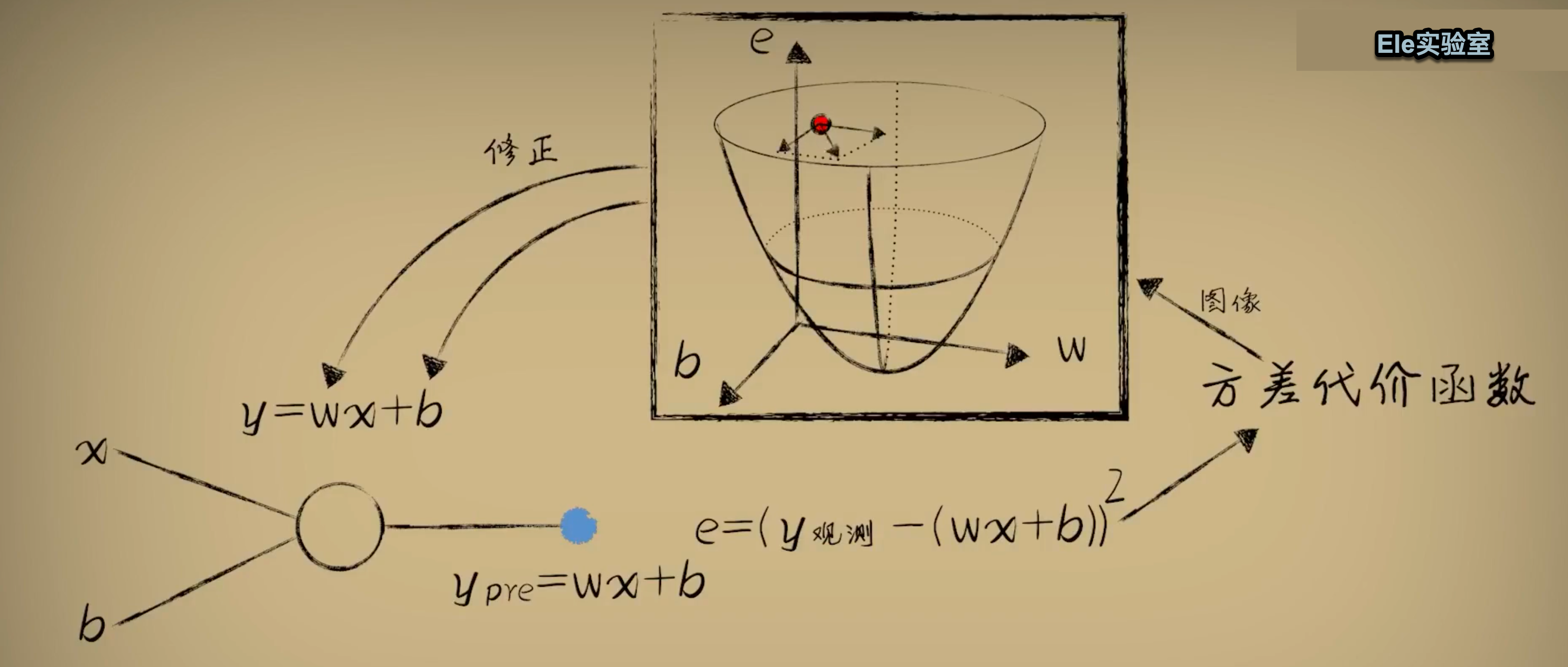
多样性的本质是拥有多种资料,做功课查资料的本质是找数据,定指标的本质是训练算法,而算法的本质是数学。从上面几本书中,我了解到人类决策和认知科学的专家们认为,决策质量的提升要更多的依靠建立在量化基础上多人参与的流程。那我们可以粗略的推导,高质量决策的本质是数学,而比拼数学水平,机器比人脑高明的太多。
再次强调决策不是决定,需要提升质量的决策也不是针对所有大事小情。成年人一天要做35000个决定,你不可能每个决定都祭起偏微分方程。工作中的场景也并非件件都涉及到利益攸关、生死存亡。当那些需要耗费精力、财力,需要依靠流程和深入的讨论而避免个人偏差、噪声造成重大损失的时候,效率就成了组织的竞争力。这个时候,一个可控的智能机器或者说智能的依据大量数据而训练出来的算法,对提升组织的效率极其重要。算法可以弥补组织中人对数字的钝感,可以代表一个绝对冷静、没有波动的噪声平衡器的意见。哪怕这个人工智能并不允许替代任何决策参与者的意见,哪怕组织中仍然要承认个人(老板,大领导)直觉的最大权重,那么多一个不会发火、生气也不会拼命辩解观点,只会陈述数据和分析逻辑的助手又有什么坏处呢?组织的决策者不一定会被别的决策者打败,但Ta一定会被拥有这个智能助手的自己打败。
极海正在努力做一个优秀的小助手。关于这个小助手的本领,请听下回分解。