
目标
依照上海市商业聚集的规则,把整个上海市划分成了201个板块(商圈),包括崇明岛、横沙等上海郊县。然后,对各个板块的人口、房价、交通、景观等因素分别进行统计分析,最后进行聚类。
数据准备
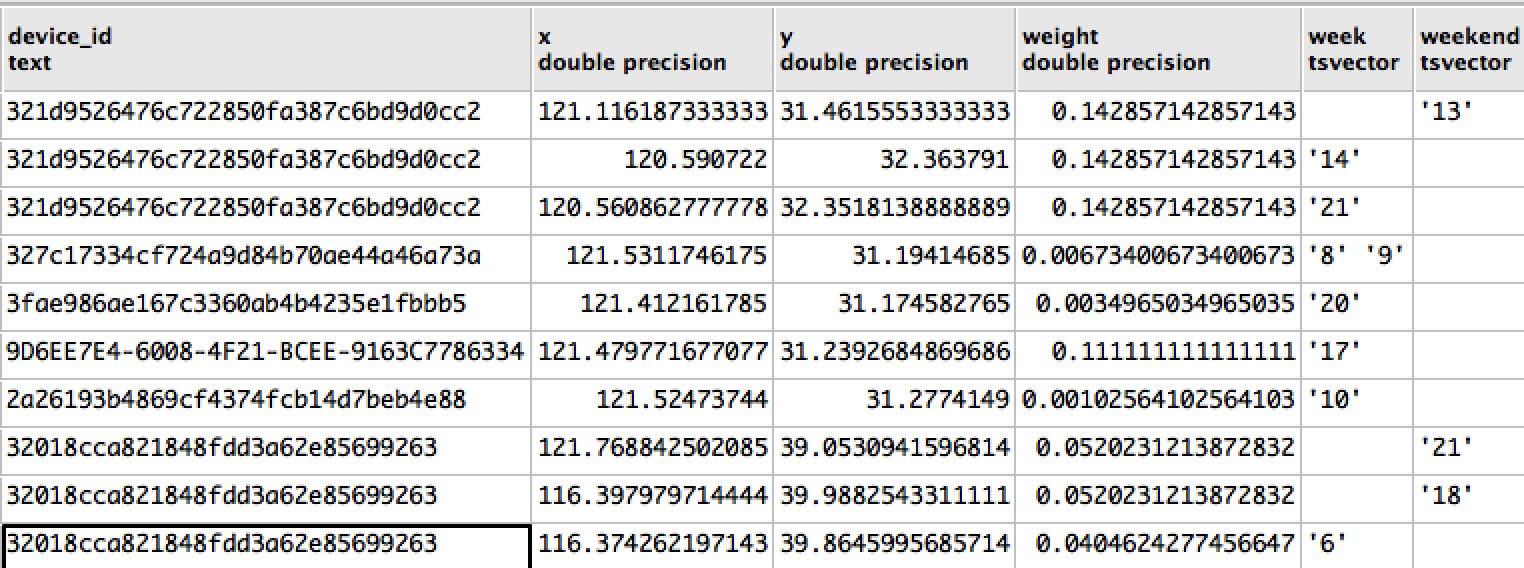
1.设备轨迹数据,代表着人口,内含:设备编号,位置坐标,位置出现过的时间(精确到小时)又可细分为平时和周末,位置的权重。来源:Talking Data。
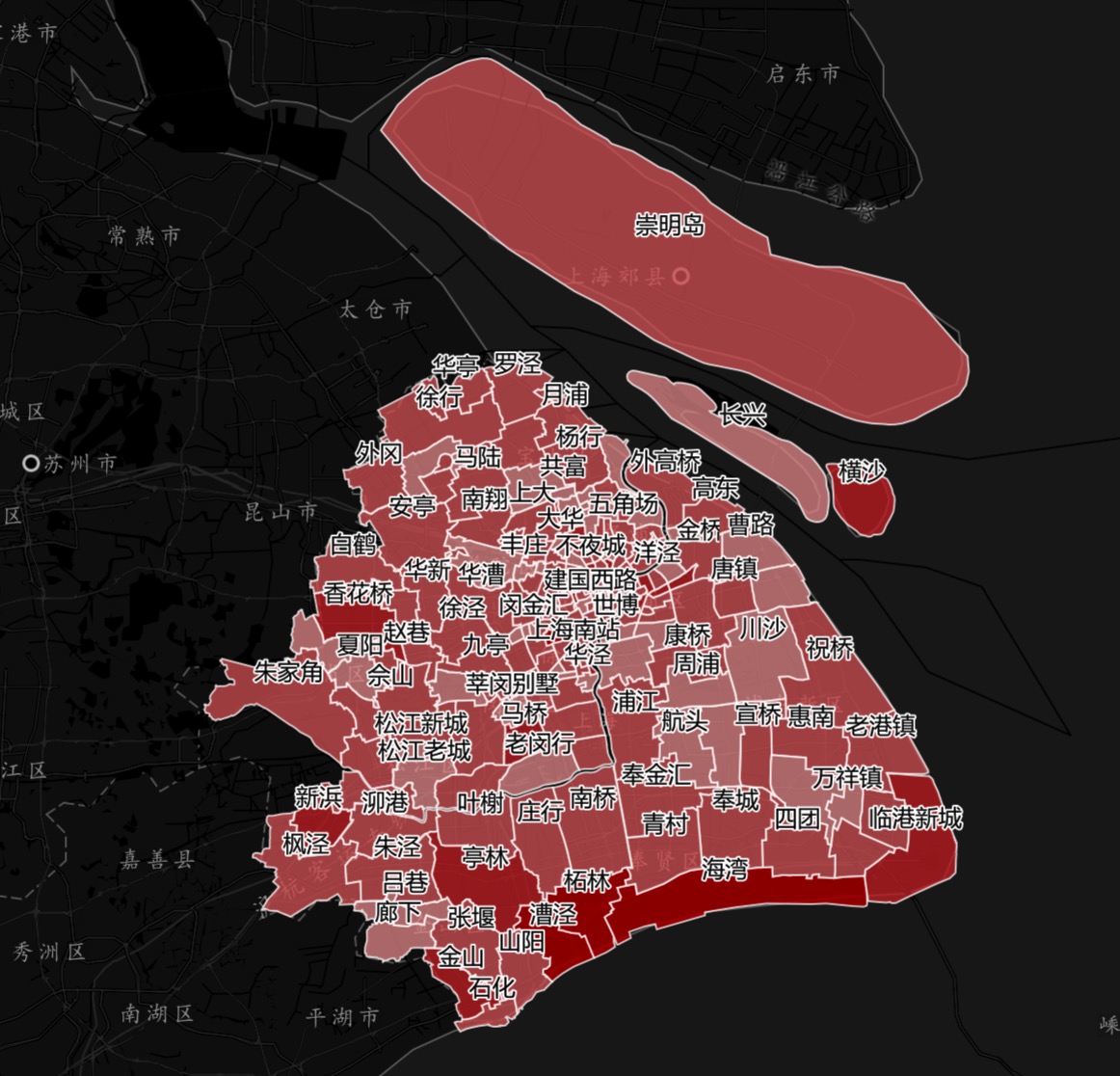
2.板块数据,即商圈,按照商
业聚集程度生成,对于郊县,参照街道行政区划生成。来自于GeoHey。
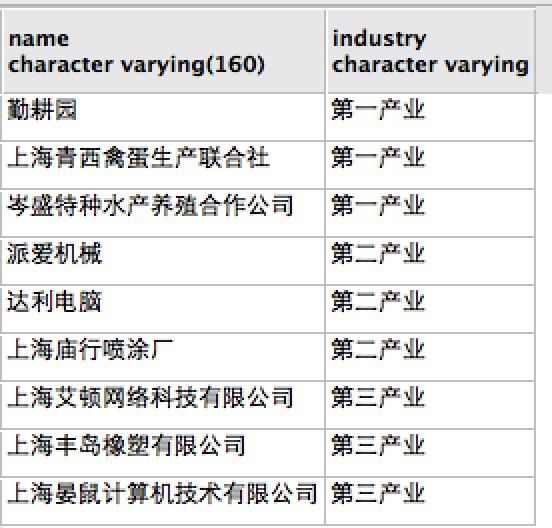
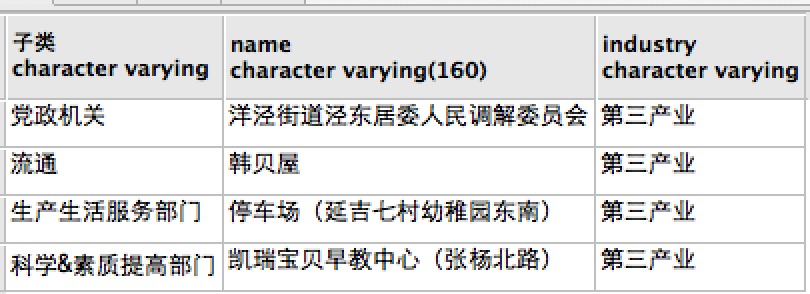
3.兴趣点数据,即POI数据,在高德分类基础上,人工进一步重新归类为第一、二、三产业,第三产业再细分:生产生活、科学素质提高部门、党政机关、流通部门。来自于GeoHey。
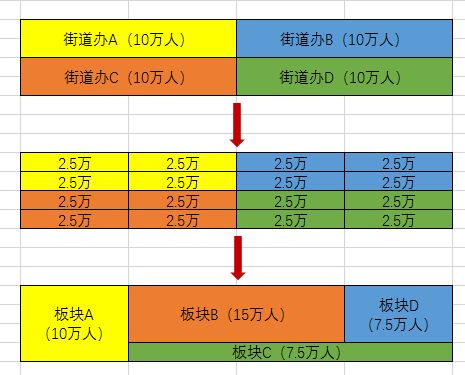
4.人口数据,第六次人口普查(2010年)得到的是街道数据,为解决街道和片区不重叠的问题,利用微积分的思想,在算法上把街道先分散到离散点上,然后根据板块包含的离散点,统计出板块的人口。来自于第六次人口普查。
5.住宅小区,包括点位和房价;来自于GeoHey。
6.专题数据:公园景点、学校(中小学幼儿园)、医院。来自于GeoHey。
7.公共交通通达性服务:输入点位,输出该点位不同时间段范围内到达的地理范围(六边形)的中心点。来自于GeoHey。
![]()
8.驾车服务范围服务:输入点位和驾车时间,从该点位出发,输入的时间范围内能够到达的区域;来自于GeoHey。
第三产业子类:
人口因子
居住密度
指板块内居住人口的密度,单位(人/平方公里)。
模型:1)仅考虑设备工作日和周末夜晚(上海:5,6,7,20,21,22,23)出现过的的位置;2)根据出现的频度(位置权重的和)决定设备所居住的区域,如果设备在不同区域内出现相同的频度,任取一个区域作为该设备的居住区域;3)以板块为单位,统计出其内的设备总量;4)居住人口 = 板块内设备总量 / 城市内设备总量 * 城市内14至65岁人口统计数;5)居住密度 = 居住人口 / 板块面积(sq km)。
工作密度
指板块内工作人口的密度,单位(人/平方公里)。模型:1)仅考虑设备工作日白天(上海:7,8,9,10,13,14,15)出现过的的位置;2)根据出现的频度(位置权重的和)决定设备所工作的板块,如果设备在不同板块内出现相同的频度,任取一个板块作为该设备的工作板块;3)以板块为单位,统计出其内的设备总量,作为工作人口,进一步计算出工作密度;4)工作人口 = 板块内设备总量 / 城市内设备总量 * 城市内14至65岁人口统计数;5)工作密度 = 工作人口 / 板块面积(sq km)。
消费人口密度
指板块内,周末来此的人口密度,单位(人/平方公里)。模型:1)仅考虑设备周末消费休闲时段(上海:11 ,12 ,13 ,14 , 15 ,16 ,17 ,18 ,19, 20, 21)出现过的的位置;2)根据出现的频度(位置权重的和)决定设备所属的板块,如果设备在不同板块内出现相同的频度,任取一个板块作;3)以板块为单位,统计出其内的设备总量,作为消费人口,进一步计算出消费密度;4)消费人口 = 板块内设备总量 / 城市内设备总量 * 城市内14至65岁人口统计数;5)消费密度 = 消费人口 / 板块面积(sq km)。
职住比
职住比 = 板块内工作人口数量/居住人口数量,反应了该板块主要的功能区:居住还是工作。
娱住比
娱住比 = 板块内消费人口数量 / 居住人口数量,反映了板块内娱乐功能是否齐全。
劳动力流入率&劳动力输出率
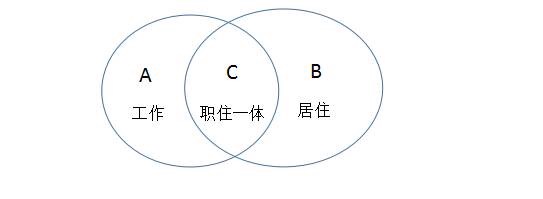
劳动力流入率=(A-C)/A,在外地居住到这里工作的人的比例
劳动力输出率=(B-C)/B,在本地居住到外地工作的人的比例
产业因子
第一、二、三产业不同的比重,反应了该地区的发达程度。国家统计局1985年对三次产业的划分作了专门的规定,即:(1)第一产业是农业(包
括林业、牧业、渔业等);(2)第二产业是工业(包括采掘业、制造业、自来水、电
力、蒸汽、热水、煤气业)和建筑业;(3)第三产业是除上述各业以外的其它产业,
它又包括四个层次:第一层次是流通部门,包括交通运输业、邮电通讯业、商业饮食
业、物资供销和仓储业;第二层次是为生产和生活服务的部门,包括金融业、保险业、
地质普查业、房地产业、公用事业、居民服务业、旅游业、咨询信息服务业和各类技术
服务业等;第三层次是为提高科学文化水平和居民素质服务的部门,包括教育、文化、
广播电视事业,科学研究事业,卫生、体育和社会福利事业等;第四层次是为社会公共
需要服务的部门,包括国家机关、政党机关、社会团体,以及军队和警察部门等。
据谢文蕙等的资料,1988年,第三产业内部这四个层次产业的比例关系是:发达国家为
25:10:30:35;亚洲“四小龙”为30:15:35:20;印度和中国大体为35:25:25:
15。第一、二层次为流通类,第三、四层次为服务类,发达国家是服务类比重大于流通
类,亚洲“四小龙”是二者大体相当,而中国和印度则相反,呈流通类比重大于服务类,
说明发展中国家和地区第三产业内部的新兴产业相对弱小。
第一产业密度
板块内,平均每平方公里内第一产业兴趣点数量。
第二产业密度
板块内,平均每平方公里内第二产业兴趣点数量。
第三产业密度
板块内,平均每平方公里内第三产业兴趣点数量。
第三产业子分类
服务业在发达城市作为支柱产业,又可进一步细分。
然后按照产业统计的方式,进行细分统计。
配套因子
医院
板块自身包含及周边5km范围内,公立的各个等级的医院(不含社区医院),专业性质上既有综合、也有专科医院,例如:"湖北第三人民医院";"三甲"
"中南医院";"三甲"
"华中科技大学医院";"二级"
学校
板块自身包含及周边1km范围内,包括:幼儿园、小学、初中、高中;
景观因子
板块自身包含及周边1km范围内,包括:公园、旅游景点、博物馆等对外开放的景点,如:"张之洞纪念公园"、
"琴台公园"、
"起义门"、
"武汉动物园"。
交通因子
分析板块内的交通状况,细分为自驾车和公共交通。
公共交通
总体权衡各个板块,乘坐公共交通的可达性。板块有大小,而且板块内部不同区域的公共交通情况也不一致,所以本模型采用了类似蒙特卡洛模型:计算板块内多个点的公共交通可达性,然后把这些点的可达性的平均值作为该板块交通可达性。单个点的公共交通可达性:从该点出发,40分能够到达的区域面积。各板块的通达性计算出来之后,为了方便比较,进行归一化:以最高的板块为100分,其他板块相对于最高板块得到自身的分数。
驾车通达性
总体权衡各个板块驾车的通达性。板块有大小,而且板块内部不同地点的驾车通达性也不一致,所以本算法采用了类似蒙特卡洛模型:计算板块内多个点的驾车通达性,然后把这些点的可达性的平均值作为该板块驾车通达性。单个点的驾车通达性:从该点出发,40分能够到达的区域面积。各板块的通达性计算出来之后,为了方便比较,进行归一化:以最高的板块为100分,其他板块相对于最高板块得到自身的分数。
城市布局
住宅布局
以公里网为分析单元,分别统计出各个公里网的格子内住宅小区(包括不同住宅小区、集体宿舍、别墅和商住两用)的数量。然后对所有网格分级显示,表达出整个城市的住宅布局。
办公楼布局
以公里网为分析单元,分别统计出各个公里网的格子内办公楼(包括:商务写字楼、工业大厦、商住两用)的数量。然后对所有网格分级显示,表达出整个城市的办公楼布局。
商场布局
以公里网为分析单元,分别统计出各个公里网的格子内商场(包括:购物中心、普通商场、免税品店)的数量。然后对所有网格分级显示,表达出整个城市的商场布局。
优势功能区
1)以公里网为分析单元,分别统计出各个公里网的格子内住宅、办公楼、商场这三种地物的相对集中度。住宅相对集中度:网格内住宅数量/城市总的住宅数量。
2)找出网格内相对集中度最高的地物作为该格网的优势功能。
3)然后对所有网格分类显示,表达出整个城市的优势功能区布局。
房价分级
我们按照房价将上海的小区分为5个档次,分别是:低、中低、中、中高、高。我们假定上海的购房者购房价格呈正态分布,即低房价和高房价的购房人群都是少数,多数人购买的房子房价和平均房价接近,因此有了下图。
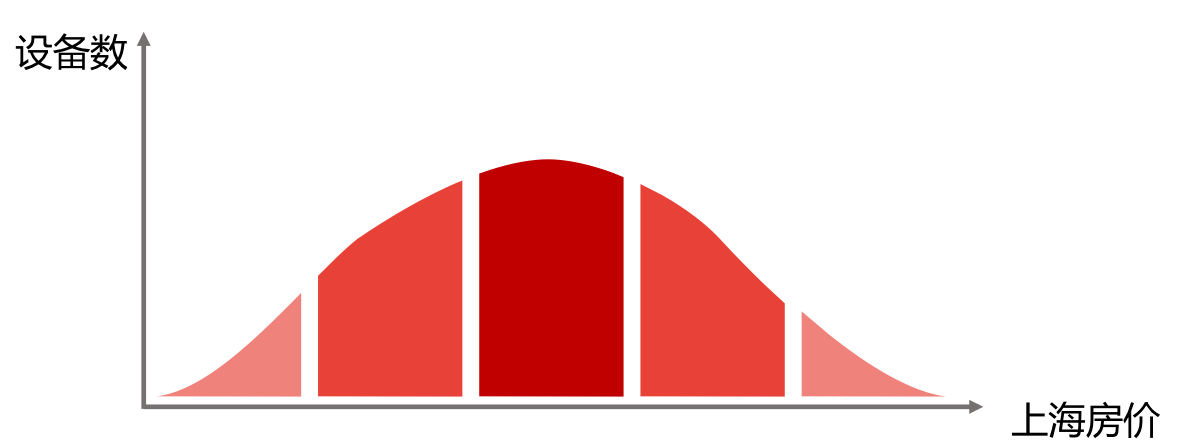
上海小区房价统计情况:最低房价:4257;最高房价:255236;平均值:33112.124931118633;标准差:17237.41802710。

标准差公式
标准差公式意义:所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数),再把所得值开根号,所得之数就是这组数据的标准差。标准差用于表现这组数据的离散程度。
根据标准差分级标准:
- 低档:下限=最低房价;上限:平均房价-1.5 * 标准差;
- 中低档:下限=平均房价-1.5 * 标准差;上限=平均房价-0.5 * 标准差;
- 中档:下限=平均房价-0.5 * 标准差;上限=平均房价+0.5 * 标准差;
- 中高档:下限=平均房价+0.5 * 标准差;上限=平均房价+1.5 * 标准差;
- 高档:下限=平均房价+1.5 * 标准差;上限=最高房价;