
深度学习(deep learning)发展史
学习任一门知识都应该先从其历史开始,把握了历史,也就抓住了现在与未来
———by BryantLJ
近几年深度学习发展迅猛,更是由于前段时间的谷歌的AlphaGo而轰动一时,国内也开始迎来这一技术的研究热潮,那这么火的深度学习到底是经历了一段怎样的发展过程呢?下面我们就来了解一下深度学习发展史。
1943年
由神经科学家麦卡洛克(W.S.McCilloch) 和数学家**皮兹(W.Pitts)在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity)。建立了神经网络和数学模型,称为MCP模型。所谓MCP模型,其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,也就诞生了所谓的“模拟大脑”,人工神经网络的大门由此开启。

麦卡洛克(W.S.McCilloch)

皮兹(W.Pitts)
MCP当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。如下图所示
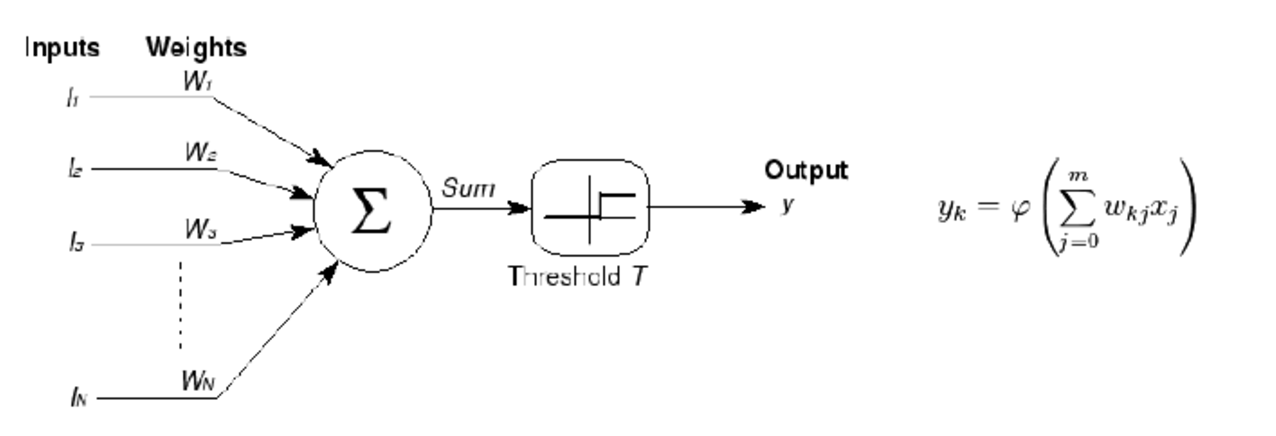
1958年
计算机科学家罗森布拉特( Rosenblatt)提出了两层神经元组成的神经网络,称之为“感知器”(Perceptrons)。第一次将MCP用于机器学习(machine learning)分类(classification)**。“感知器”算法算法使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
1969年
纵观科学发展史,无疑都是充满曲折的,深度学习也毫不例外。
1969年,美国数学家及人工智能先驱 Marvin Minsky 在其著作中证明了感知器本质上是一种线性模型(linear model),只能处理线性分类问题,就连最简单的XOR(亦或)问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了将近20年的停滞。
1986年
由神经网络之父 Geoffrey Hinton 在1986年发明了适用于多层感知器(MLP)的BP(Backpropagation)算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮
注:Sigmoid 函数是一个在生物学中常见的S型的函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间。
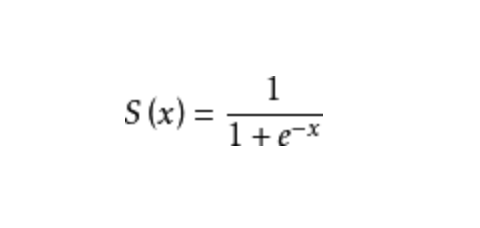
90年代时期
1991年BP算法被指出存在梯度消失问题,也就是说在误差梯度后项传递的过程中,后层梯度以乘性方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习,该问题直接阻碍了深度学习的进一步发展。
此外90年代中期,支持向量机算法诞生(SVM算法)等各种浅层机器学习模型被提出,SVM也是一种有监督的学习模型,应用于模式识别,分类以及回归分析等。支持向量机以统计学为基础,和神经网络有明显的差异,支持向量机等算法的提出再次阻碍了深度学习的发展。
发展期 2006年 - 2012年
2006年,加拿大多伦多大学教授、机器学习领域泰斗、神经网络之父—— Geoffrey Hinton 和他的学生 Ruslan Salakhutdinov 在顶尖学术刊物《科学》上发表了一篇文章,该文章提出了深层网络训练中梯度消失问题的解决方案:**无监督预训练对权值进行初始化+有监督训练微调。**斯坦福大学、纽约大学、加拿大蒙特利尔大学等成为研究深度学习的重镇,至此开启了深度学习在学术界和工业界的浪潮。

2011年,ReLU激活函数被提出,该激活函数能够有效的抑制梯度消失问题。2011年以来,微软首次将DL应用在语音识别上,取得了重大突破。微软研究院和Google的语音识别研究人员先后采用DNN技术降低语音识别错误率20%~30%,是语音识别领域十多年来最大的突破性进展。2012年,DNN技术在图像识别领域取得惊人的效果,在ImageNet评测上将错误率从26%降低到15%。在这一年,DNN还被应用于制药公司的DrugeActivity预测问题,并获得世界最好成绩。
爆发期 2012 - 2017
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引到了众多研究者的注意。
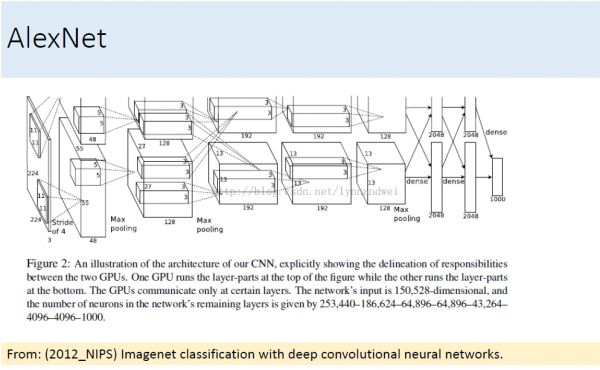
AlexNet的创新点在于:
(1)首次采用ReLU激活函数,极大增大收敛速度且从根本上解决了梯度消失问题。
(2)由于ReLU方法可以很好抑制梯度消失问题,AlexNet抛弃了“预训练+微调”的方法,完全采用有监督训练。也正因为如此,DL的主流学习方法也因此变为了纯粹的有监督学习。
(3)扩展了LeNet5结构,添加Dropout层减小过拟合,LRN层增强泛化能力/减小过拟合。
(4)第一次使用GPU加速模型计算。
2013、2014、2015、2016年,通过ImageNet图像识别比赛,DL的网络结构,训练方法,GPU硬件的不断进步,促使其在其他领域也在不断的征服战场。
2016年3月,由谷歌(Google)旗下DeepMind公司开发的AlphaGo(基于深度学习)与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;2017年5月,在中国乌镇围棋峰会上,它与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平。
总结
深度学习目前还处于发展阶段,不管是理论方面还是实践方面都还有许多问题待解决,不过由于我们处在了一个“大数据”时代,以及计算资源的大大提升,新模型、新理论的验证周期会大大缩短。人工智能时代的开启必然会很大程度的改变这个世界,无论是从交通,医疗,购物,军事等方面,或许我们处于最好的年代,也或许我们处于最坏的年代,未来无法预知,那就抱着乐观的态度迎接这个第三次工业革命吧。