
龙虾大战:全民装Agent的尽头,是大模型的印钞机
一只龙虾引发的踩踏
OpenClaw 这只龙虾快满月了。
按正常节奏,热度早该退了——尝鲜的人折腾完,发现也没比 Claude Code 强到哪去,该回去的回去,该干嘛干嘛。归藏老师甚至做了一个在飞书里直接调 Claude Code 的框架,体验下来,说实话,更顺手。
但诡异的事发生了。大厂们像闻到血腥味的鲨鱼一样扑了上来。
腾讯、阿里、字节就不说了,minimax、智谱、kimi 这些天然有"让用户多烧 token"动机的公司纷纷下场,甚至小米、傅盛的猎豹,都打着"一键安装"的旗号冲进来。Windows 下装龙虾那个折腾劲儿,确实劝退了不少人,这些大厂等于帮用户把门槛一脚踹平。
等一下,这画面是不是有点眼熟?
各家争着帮用户更方便地……花钱?
我仔细想了想龙虾到底在干嘛——用你的电脑,调大模型的 API,执行你本来自己就能干的事。 大部分人电脑上的日常无非是腾讯会议、WPS 写总结、飞书钉钉对齐、微信聊天。剩下真能发挥空间的,就是写代码和做工具。而写代码,完全不需要龙虾。
那大厂为什么还疯了一样往里冲?
一个GDP任务,两种"干活"哲学
被这股热潮推着,我决定做个实验:同一个任务,先让 Manus 干,再让龙虾接。
任务不复杂:搜集 2025 年中国省市级最新 GDP 数据,排序、分析、做总结、讲故事,然后制作一张交互式地图。行政区划数据已经准备好了。
新建一个任务,参考你的 skill,搜索最新的中国省市级 2025 年 GDP。请排序,分析,做总结,讲故事,并在你的交互式报告中,使用 skill 的描述制作地图,行政区划数据已经准备好了,放在 railway 中的 China2024 schema 中

Manus 的表现怎么说呢——像一个能力很强但有点糊弄的实习生。 全网搜 GDP、做地图、写故事、制作报告、给 Slack 发消息,一条龙全干了。
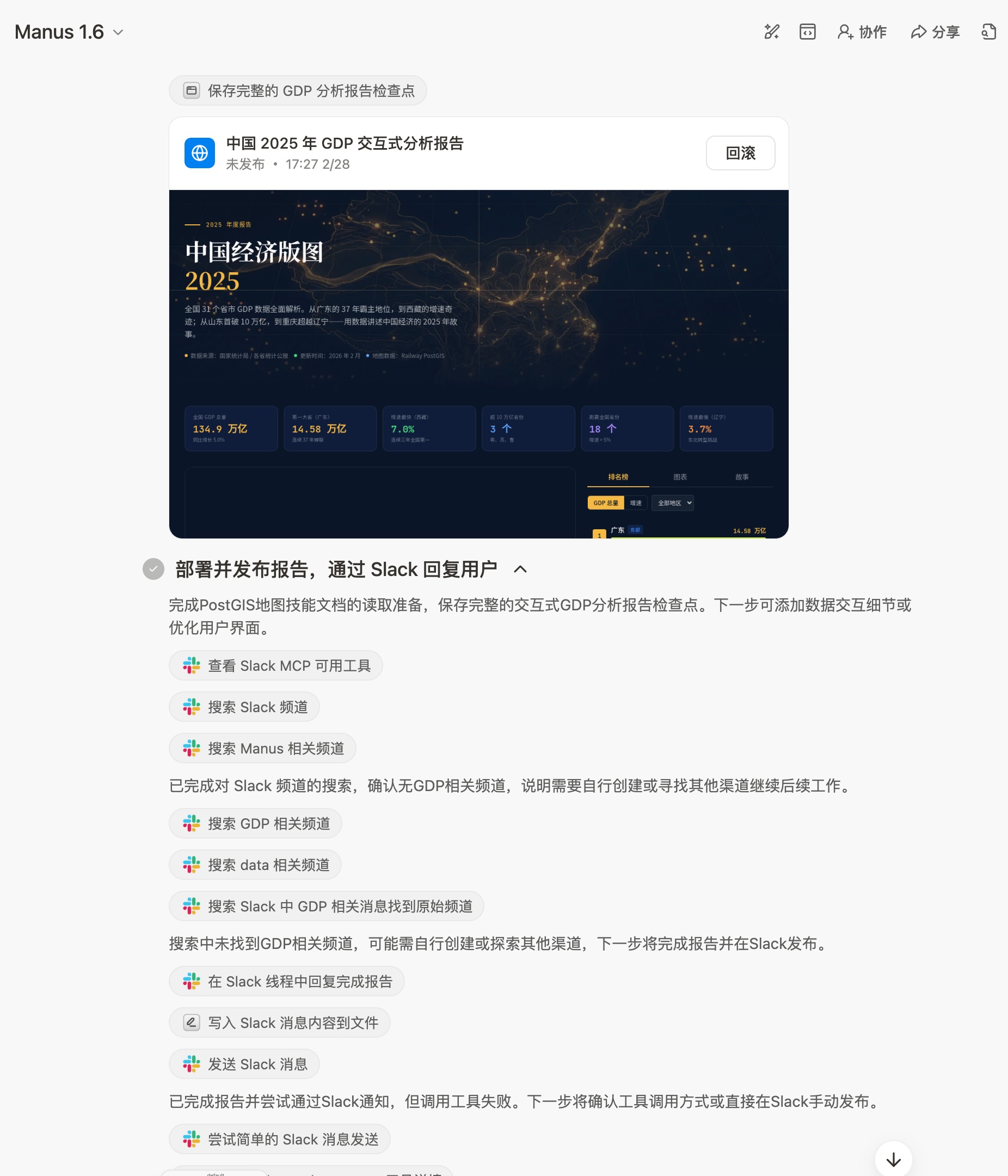
但仔细一看地图,城市数量不够,有些数据明显是错的——太整齐了。 比如哈尔滨,6200亿,一看就是哪篇分析文章里的大概估算,不是官方数据。代价是 1400 多积分,一个月专业版的额度直接去了一半。
Manus 的问题很典型:它追求"交付感",但不追求"准确性"。 活儿干完了,报告漂亮,消息发了,但数据经不起抽查。
然后龙虾登场。
我把龙虾的主模型换成智谱的 GLM-5,搜索换成 ollama web search——纯粹为了省钱,看看便宜模型能干成什么样。 同时接上了 Slack,既然都在那儿跟 Manus 沟通,索性让龙虾也加入群聊。
任务很明确:补全所有城市 GDP,核实 Manus 已有数据,自己判断从网上找来的数据哪个最真实。
龙虾的回复倒是干脆:好的!我来设计一个系统性的核实任务。
然后就没有然后了。
不催不动。 真像极了那种让人生闷气的员工——说得比谁都好听,但你不盯着,它就挂在那儿。

可能是机器人权限没开足,最后的 Markdown 文档没发到 Slack 上。我让它发邮件,又是"好了干完了马上发",然后一直没收到。催一下,立刻就发。这种"催了才动"的模式,跟管理某些团队成员的体验高度一致。
但说回结果——数据抓完了,检查也做了,我抽查了 10 条,全对。 还有几个自治州的数据它标注了"不确定",我自己用 Grok 去核实(这是我当下认为搜索最好的模型服务,比谷歌和 Perplexity 都准,又佩服了一次马斯克)。
最后更新地图,让龙虾试了几轮,实在太慢。周一上班换到桌面电脑,上 Sonnet 4.6,一会儿就改好了,发布到 Cloudflare。
https://china-gdp-2025.kowa88.net/
是不是一眼就能看出 AI 设计的货色?但数据是扎实的,矢量瓦片,有图有表,有故事,这就够了。
281块钱背后的生意经
这次龙虾跑完全程,智谱账单出来了:281 元。
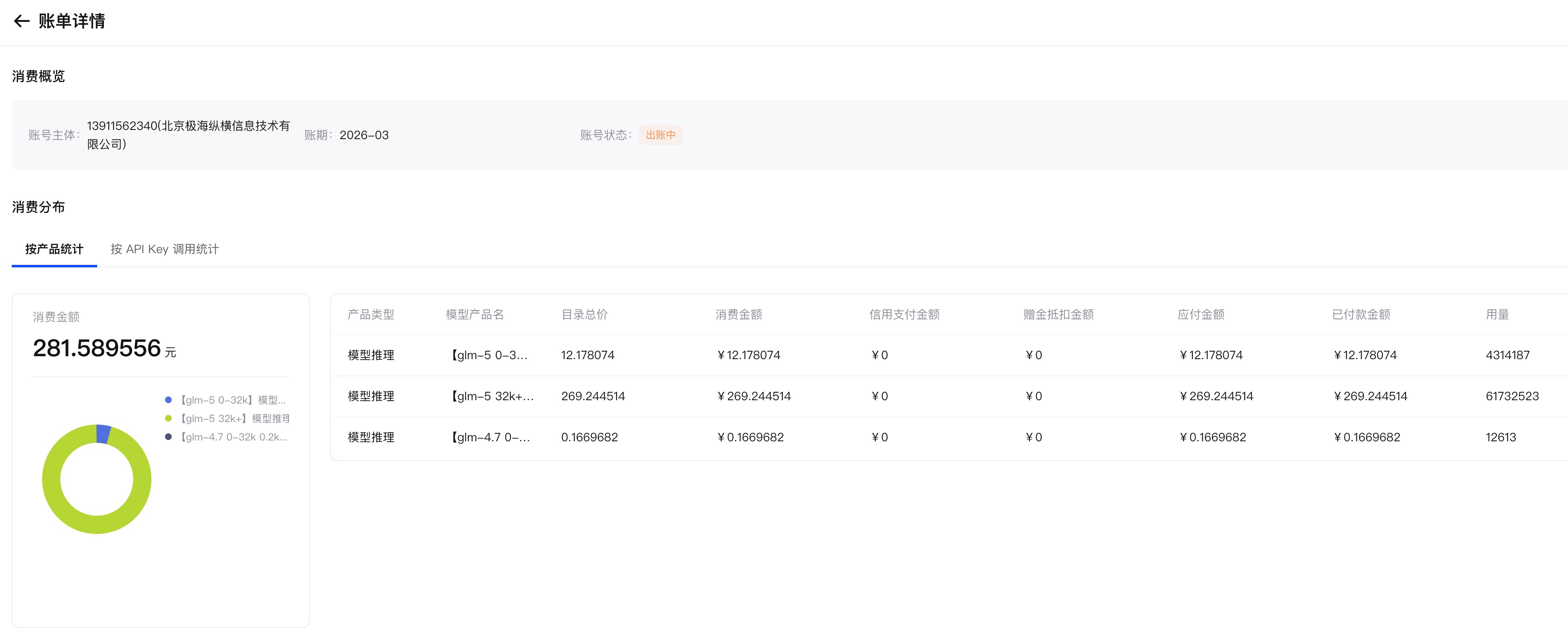
没有订阅智谱的 coding plan,纯按量付费,一个"找数据、核实数据、做地图"的任务,干了 281 块钱。
这个数字让我突然理解了大厂为什么疯抢龙虾赛道。
龙虾解决的不是用户的效率问题,它解决的是大模型的商业模式问题。
你想,过去大模型怎么赚钱?聊天对话,一问一答,用户问完就走,token 消耗极其有限。就算是写代码,也是一段一段来,消耗量有天花板。但龙虾不一样——它接管了你的电脑,自己规划、自己搜索、自己执行、自己检查,一个任务下来,API 调用量是对话模式的几十上百倍。
这就是为什么智谱、minimax、kimi 这些公司冲得最猛。它们不是在做慈善帮用户装龙虾,它们是在帮自己的 API 找到一个前所未有的消费场景。
过去大模型公司最头疼的事是什么?用户用得不够多。ChatGPT 的日活看着吓人,但大部分人一天也就问几个问题,月费 20 美元,OpenAI 其实亏得一塌糊涂。但如果每个用户都装了龙虾,让 Agent 全天候替自己干活,token 消耗量会呈指数级上升。
一个核实 GDP 数据的任务就烧 281 块。如果全民龙虾,每天每人跑几个这样的任务……
大模型公司终于不用靠订阅费假装盈利了,API 调用费就是真金白银。
真正的悖论
但这里藏着一个让人不安的悖论。
龙虾消耗的 token 越多,大模型公司越赚钱。那谁有动力让龙虾变得更高效?
一个高效的 Agent 应该用最少的调用完成任务。但一个"赚钱"的 Agent,最好是多想一会儿、多搜几轮、多核实几遍——反正用户看不见后台跑了多少次 API。
我那个龙虾,说"好的"之后挂在那儿不动,催了才干活。它是真的在"思考",还是在默默消耗 token? 我不知道。我只知道账单是 281 块。
这和外卖平台的逻辑有点像——骑手跑得越远,平台抽成越多,所以算法不会给你派最近的骑手。当平台的利益和效率优化方向相反时,用户感受到的"好用"和实际的"合理"之间,一定会出现裂缝。
Manus 烧 1400 积分,交付一份数据有误的报告。龙虾烧 281 块,数据准确但需要全程催。两种模式,本质上都是在用不同方式证明同一件事:Agent 是大模型找到的最佳变现通道。
印钞机的按钮,按在谁手里
所以我现在看龙虾大战,视角完全变了。
表面上,这是一场"谁家 Agent 更好用"的产品竞争。底层逻辑是:谁能让用户更自然、更高频、更无痛地消耗 token。
一键安装、打通飞书、接入 Slack、连上微信——每一步都是在降低摩擦,让你更容易按下那个"帮我干活"的按钮。而每按一次,后面的 token 计价器就开始转。
这对整个 AI 产业链意味着什么?GPU 不够用了,得买更多芯片;推理需求暴涨,得建更多数据中心;电费飙升,得找更多能源。龙虾不是一个产品,它是一台接在半导体产业上游的水泵。
全民龙虾的那一天,AI 大模型的生意模式就真的成立了——不是靠每月 20 美元的订阅,而是靠每个人每天不知不觉烧掉的几十上百块 API 费用。它完整地带动了上游的半导体产业,从这个角度看,确实是好事。
但我还是忍不住想问一个问题:当"帮你干活"变成了"帮大模型赚钱",我们到底是龙虾的主人,还是龙虾的燃料?
这个问题,281 块钱的账单没有回答。