
浅谈地理编码
地理编码的过程:将一段表示地址的文字与大量表示地址并包含位置属性(有经纬度信息)的文字进行相似性匹配,在这些表示地址的文字中匹配到相似度最高的文字,最后,返回匹配结果和相应的经纬度信息做为这个过程的成果。
根据地理编码的过程可知,这个过程与数据库里执行查询得到满足一定条件的数据这一过程(图一)是类似的,因此,可以利用数据库技术实现地理编码。

图一:在数据库中查询名称叫’北京极海纵横信息技术有限公司’的数据
利用数据库技术实现地理编码时,需要对两段文字的相似性进行度量,一种简单的度量方式就是:对两段文字进行分词,转换为词组列表,然后统计两个词组列表中相同的词组有多少个,相同的词组越多,两段文字的相似度越高(如图二)。图二所示:通过统计地址A和地址B共有词组列表中词组数量即可得到两个地址之间的相似性度量值。

图二:两段文字的相似性度量方法
在数据库中,根据上述两段文字的相似性度量方法,编写查询语句执行查询即可对一段表示地址的文字进行地理编码,图三即为’银谷大厦215’这段文字的地理编码结果。

图三:对’银谷大厦215’这段文字进行地理编码
搭建网络服务将上述编码过程做为后端支撑,通过网络调用上述编码过程,将上述地理编码实现过程产品化,图四即为地理编码最终实现成果
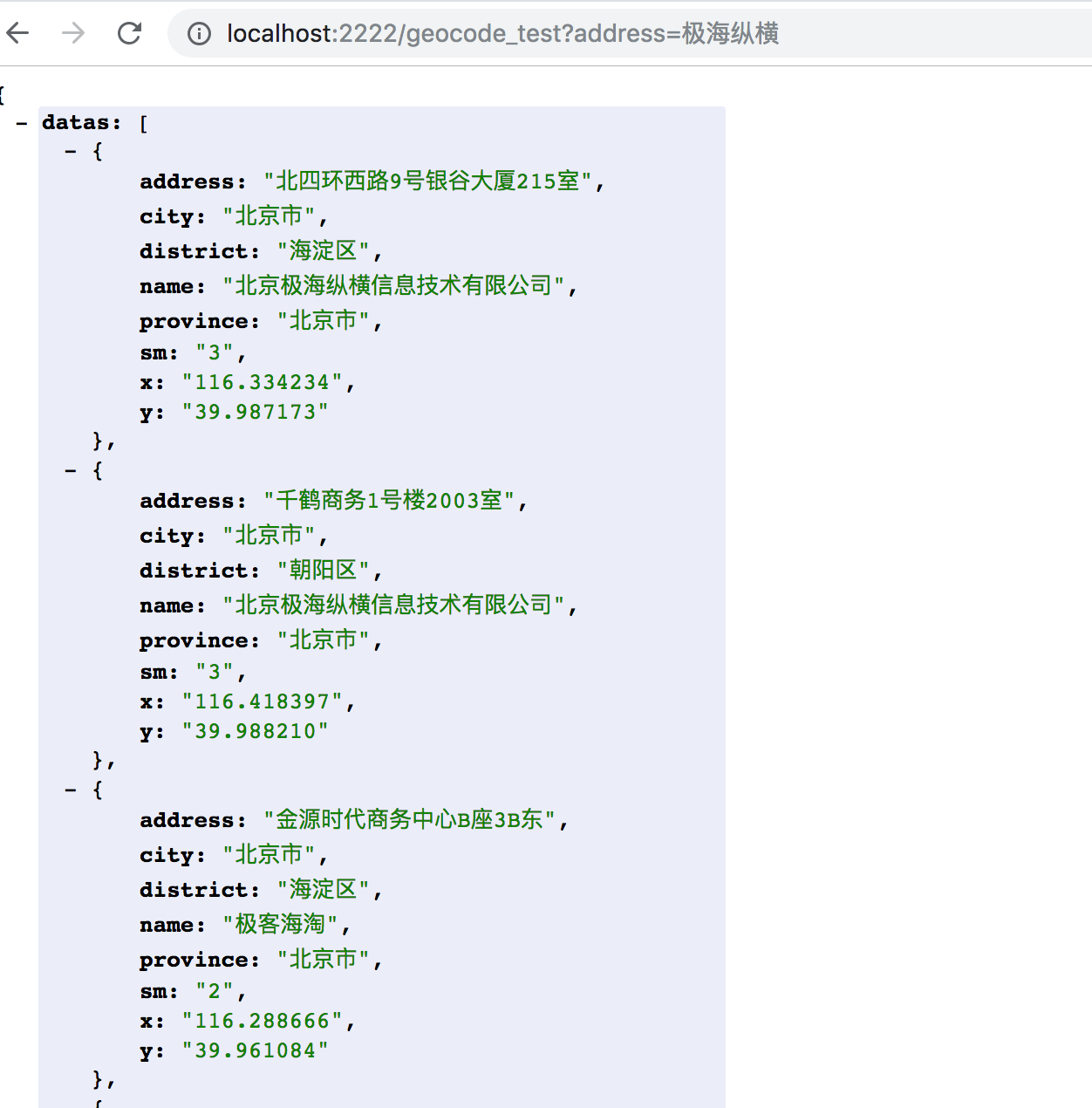
图四:对’极海纵横’进行地理编码的最终展示成果
总结
以上所述,从自身对地理编码过程的理解出发,简要地描述了利用数据库技术实现地理编码的部分过程,简要地描述了综合利用数据库和分词以及搭建网络服务,实现一个达到基本功能的地理编码原型产品。本文并未对上述地理编码实现原理的可靠性、有效性等进行验证,只是进行可行性尝试,有自娱自乐的成分,因为,开发一个完善的地理编码产品涉及的细节很多,以自身对地理编码的理解:利用数据库做后端支撑,在高并发请求的现实环境中是否能保证可靠性,这是需要考虑的细节;利用数据库做后端支撑,在大数据量的现实环境中是否能保证查询的效率,这是需要考虑的细节;分词的有效性如何提升,分词错误时如何识别,这是需要考虑的细节;查询得到的结果如何排序,这是需要考虑的细节;以及许多实际使用时会遇到的种种未知情况需要考虑;要做好地理编码,得不断优化改良。