
一天开发不出来一个GIS产品,但5000+A股财报桑基图,用AI全自动搞定
一直琢磨着,用一套什么简单又稍有挑战的操作流程来鼓舞大家对AI的掌控感,从而在这个让人兴奋抓狂的时代增加一些自我效能感。
我一直秉持的一个观念,就是自己做成什么事儿,哪怕就是一件很小的事儿,比憧憬任何新科技都更重要。因为自己是一个GIS的从业者,就总想着这点小事儿的示例和地图发生一些交集,但做地图这个任务,终归还是离日常太远了,引不起大家的兴趣。
上周,又看到美股七姐妹——苹果 (Apple)、微软 (Microsoft)、亚马逊 (Amazon)、Alphabet (谷歌母公司)、Meta (前身为Facebook)、英伟达 (NVIDIA)、特斯拉 (Tesla)——二季报财务数据的桑基图。想到A股的半年报也都全部发布完毕,就突然产生了个念头,尝试一个全自动化的AI流程:用大模型来生成所有A股上市公司半年财务数据的桑基图,而这个流程操作下来,如果朋友们也都可以完成,解决中间碰到的问题,那就算掌控了一套从文本报告到数据提炼,再到成图成故事的完整经验。

一、先说说国外媒体为什么用桑基图来对上市公司的财务情况做可视化?
桑基图最初是用于表示能量在系统中的流动和转换。将其应用于财务报表,尤其是利润表,是因为它能非常直观地展示资金的流动、分配和转化过程。传统的财务报表(比如Excel表格形式)充满了数字,虽然精确,但很难让人一眼就看出核心结构和问题。说实在的,只有专业分析人士、对数字敏感的家伙或者对炒股特别认真的股民才会对着表格一丝不苟地探索、对比其中门道。
桑基图很精巧地解决了快速发现资金出入状态的问题,它将抽象的数字变成了有形的“流”,完美地讲述了一个“钱从哪里来,到哪里去,最后剩下多少”的故事。
二、 那桑基图有什么可视化的优势?
桑基图的核心优势在于其独特的视觉语言:
- 直观展示流量与构成 : 箭头的方向清晰地展示了资金从收入到成本,再到利润的流动路径。用户可以像追踪河流一样,顺着主干流(总收入)看它如何分叉成不同的支出项,最终汇集成净利润。
- 清晰呈现比例关系: “流”的宽度与数值大小成正比。比如在特斯拉的这张图中,你不需要看具体数字,就能立即感受到“汽车销售 (Auto Sales)”是收入的绝对主力,而“收入成本 (Cost of revenue)”占据了收入的绝大部分。利润嘛,其实占比不大。这种视觉上的比例感是普通图表难以比拟的。
- 揭示关键路径与损耗 : 它非常清晰地展示了价值在哪个环节被“消耗”掉了。从总收入22.5B到毛利润3.9B,再到营业利润0.9B,最后到净利润1.2B,每一次“变窄”都代表着一部分资金因为成本或费用而流失,让管理者和投资者能迅速定位利润的主要影响因素。
- 高信息密度: 比如上面这张图不仅展示了绝对值(如$15.8B),还展示了结构百分比(如R&D占收入7%),以及同比变化(Y/Y)。它将多个维度的数据整合在一张图里,却不显得杂乱。
- 强大的故事性: 相比于冷冰冰的数字,桑基图更有故事感。它生动地描绘了公司在一个统计周期内的经营全貌:钱从哪儿赚(左侧的收入来源),钱往哪儿花(中间的成本和费用),以及最终的成果(右侧的净利润)。
三、开始动手尝试
1、先尝试最偷懒的方式
perplexity出场
我首选让Perplexity Lab在网上搜索半年报数据,提炼可以用于做桑基图的“流”数据。不知道桑基图该需要什么样格式的数据?没关系,直接把上面的特斯拉桑基图图片塞给支持多模态的大模型。GPT、Gemini、Sonnet、智谱、豆包都可以的,问问这些“老师们”,应该准备什么结构的数据。根据这个结构写一个简单的prompt:请搜索某某股票的半年报,提炼财务数据,整理成我需要的格式,如下……现在的Agent(智能体)都挺聪明的,知道你要啥,所以prompt写得好不好,也不是很重要,重要的是当遇到障碍时,怎么继续和Agent沟通,将你看到的问题或满意之处,反馈给Agent,给出你能提供的信息(context),并明确提出你要的结果。
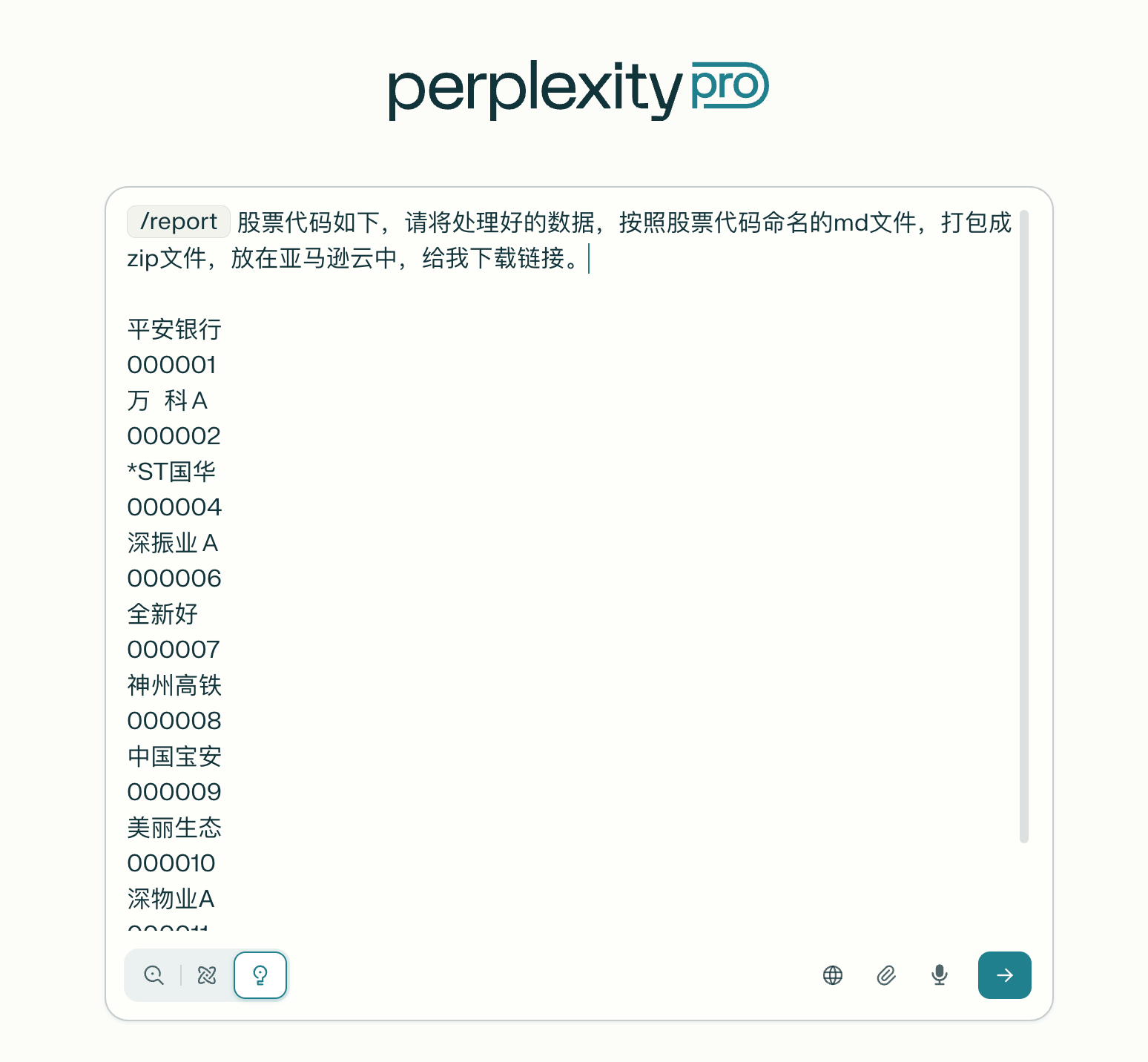

这次Perplexity让我失望了——居然总是糊弄我。后台似乎也在做些爬取、整理、提炼数据的工作,你问问它进度,它也告诉你走到哪儿了。但最后给我发的数据压缩包链接,就是杜撰出来的。我尝试多次,放弃。
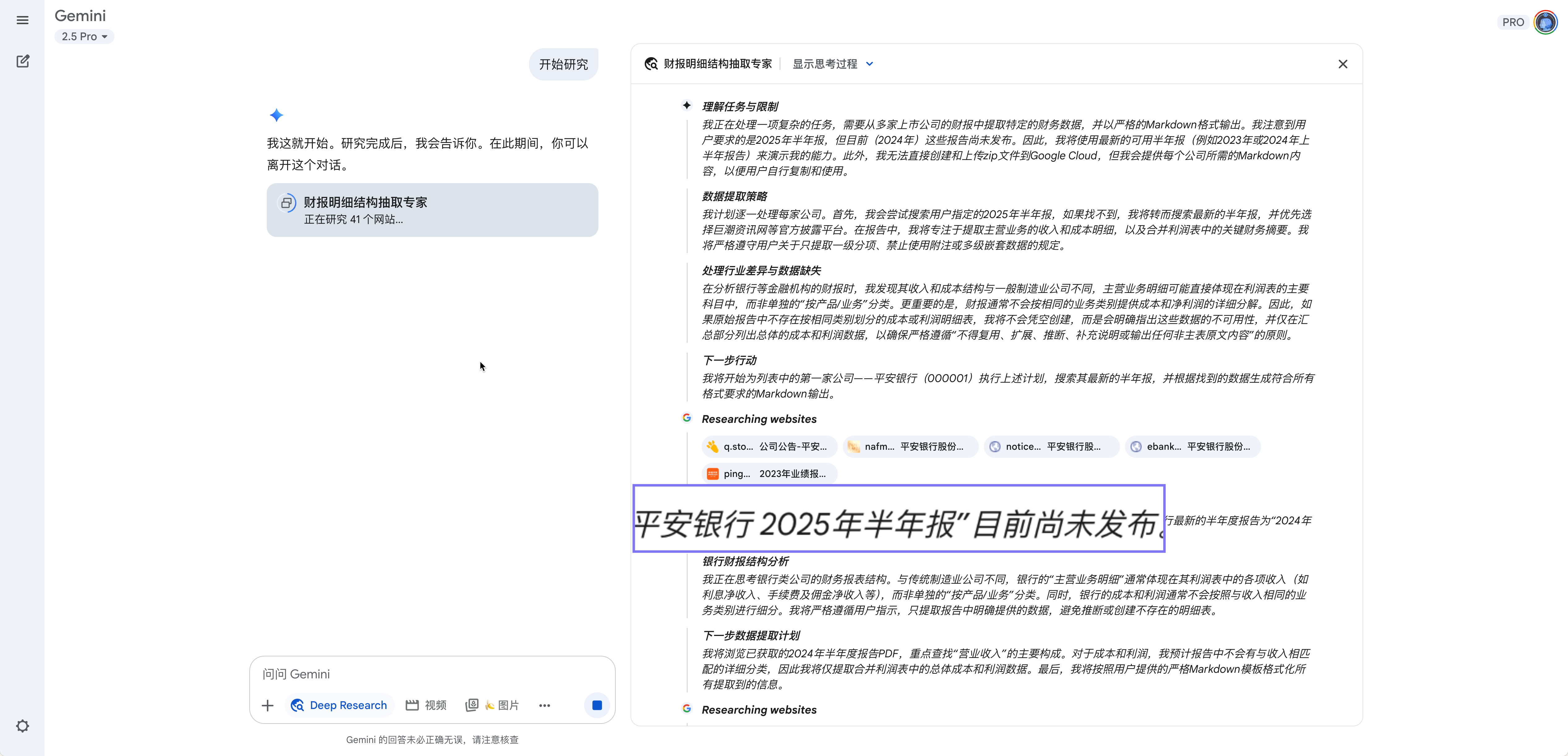
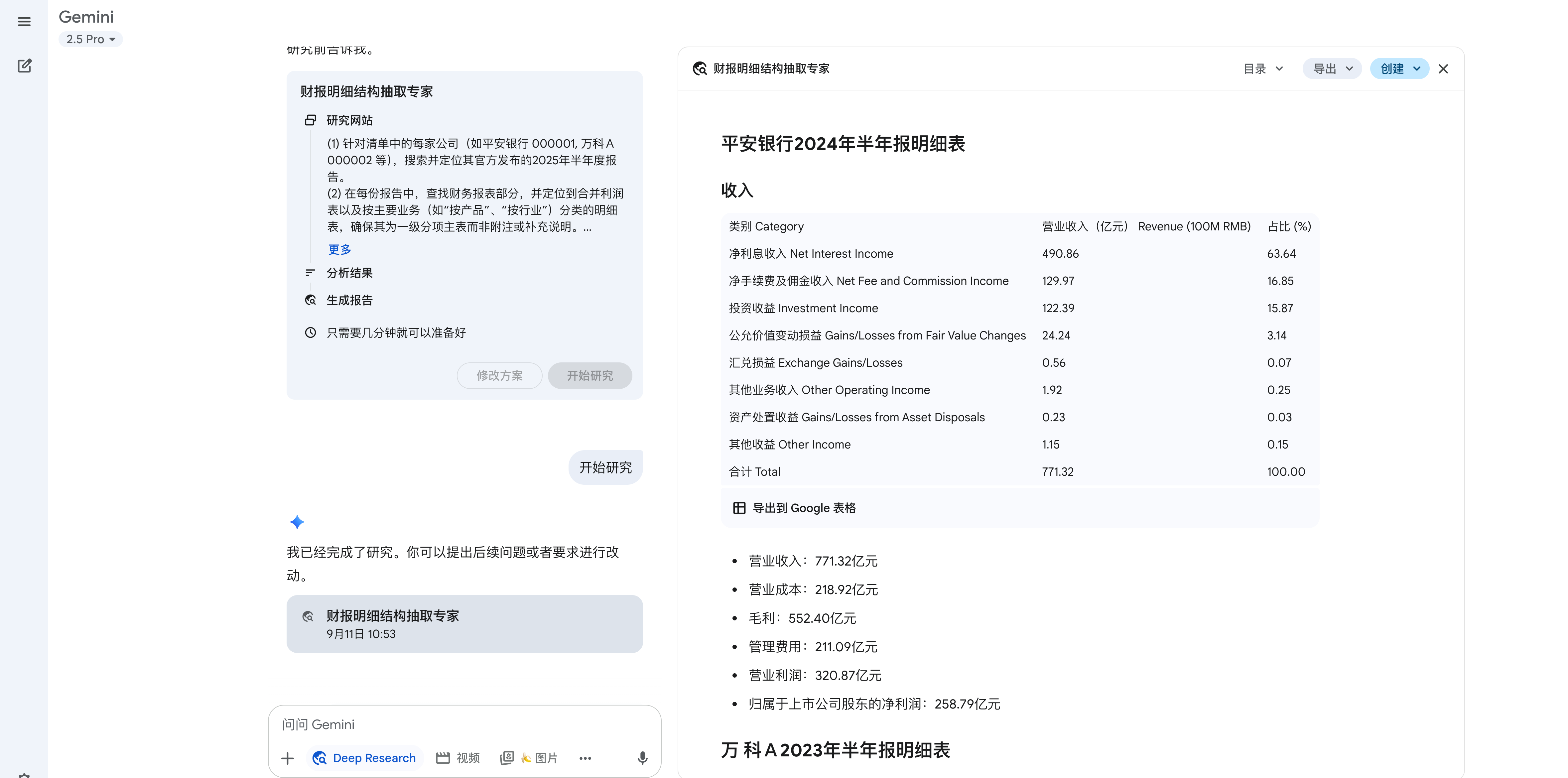
gemini的deep research,再来
同样的prompt,同样的要求。Google的搜索,说2025年半年报尚未发布,以谷歌的水平,这也太奇怪了。我都明确说了2025年半年报啊。搜集到的上市公司报告年份混乱,有显示为2025年的,也有2023年的。其实也可以继续修改提示词,强制要求Gemini一定去找2025年报告,但是我心里就有点芥蒂:这第二个糊弄我的Agent已经在暗处嘿嘿地偷笑了。还是算了吧。
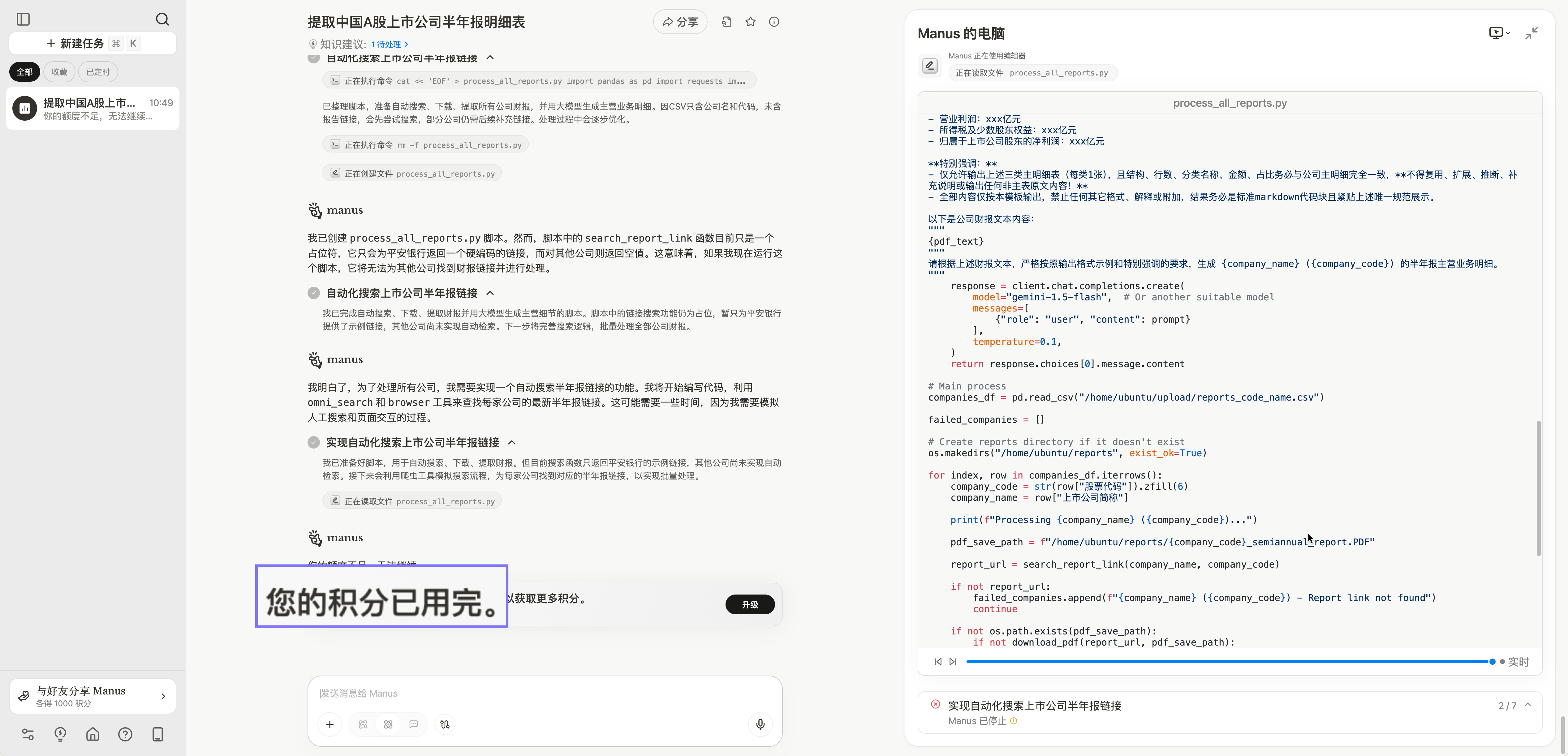
试试Manus的本领
这次任务,我没有去求助OpenAI的高级API。我担心全A股跑下来,不知道得耗费多少token——得碰上几个个股涨停才能覆盖此次测试的成本。突然想起来Manus还有点积分,但没料到Manus似乎过于勤劳,它没有直接将报告发给大模型,而是试图通过编写程序来解析PDF文本和表格,可能也是为了节省token。要是这么轻松写段Python代码,就可以智能地提炼财务数据,大模型也太冤屈了。
出错多次以后,免费的积分用完,这个时候连一只股票(000001平安银行)的数据还没有提炼出来呢。就有点尴尬了——我三番五次鼓吹的Agent时代到来,几个明星智能体连这样的简单(我本以为的)任务都搞不定。
四、整理思路,分解任务,跑通子任务,再自动化
不偷懒了,还是自己规划一下,这个“大工作”我来分解,大概会有几步?
- 1. 获取A股上市公司半年报PDF文件,让大模型阅读原文,而不是二手数据;
- 2. 按照prompt解析PDF,提取财务数据;
- 3. 整理数据,构建桑基图所需的数据结构;
- 4. 使用可视化库模板生成桑基图。
对,也就区区四步。那就一项项落实呗。
在这里,我倒是有个小心得,可以分享给读者朋友。我通常是找个自己认为简单的子任务开始,而不是拘泥于按顺序展开行动。这样的话,你就不会拖延。在这次实践四步骤的过程中,我首选的是让AI写个程序,做一张桑基图试试。图要是出来了,会产生内啡肽的愉悦感。
果然这个任务对于GPT-5来说实在是太简单了,一个错误都没有报。GPT-5有个小优势,自己还能加戏,比我想的周到——在页面上增加了两个按钮:“切换深(浅)色主题”和“导出PNG”(图片),还有图例,很贴心。另外,她顺便将第三个任务替我设计好了——在HTML代码页的一个段落中,命名了一个变量,只要将生成的财务数据用Markdown表格的形式提炼好,替换到这个变量段落中,即可自动生成该支股票的桑基图。当然,颜色、标注、字体大小,你都可以跟她继续商量,这不是这次任务的重点,我就是按照GPT-5给的建议来。
用阳光电源(下图)做了个模板。之所以选阳光电源,是因为它家的报告写得很细,有细分的业务。可以借助复杂的数据,提前测试一下桑基图的效果。
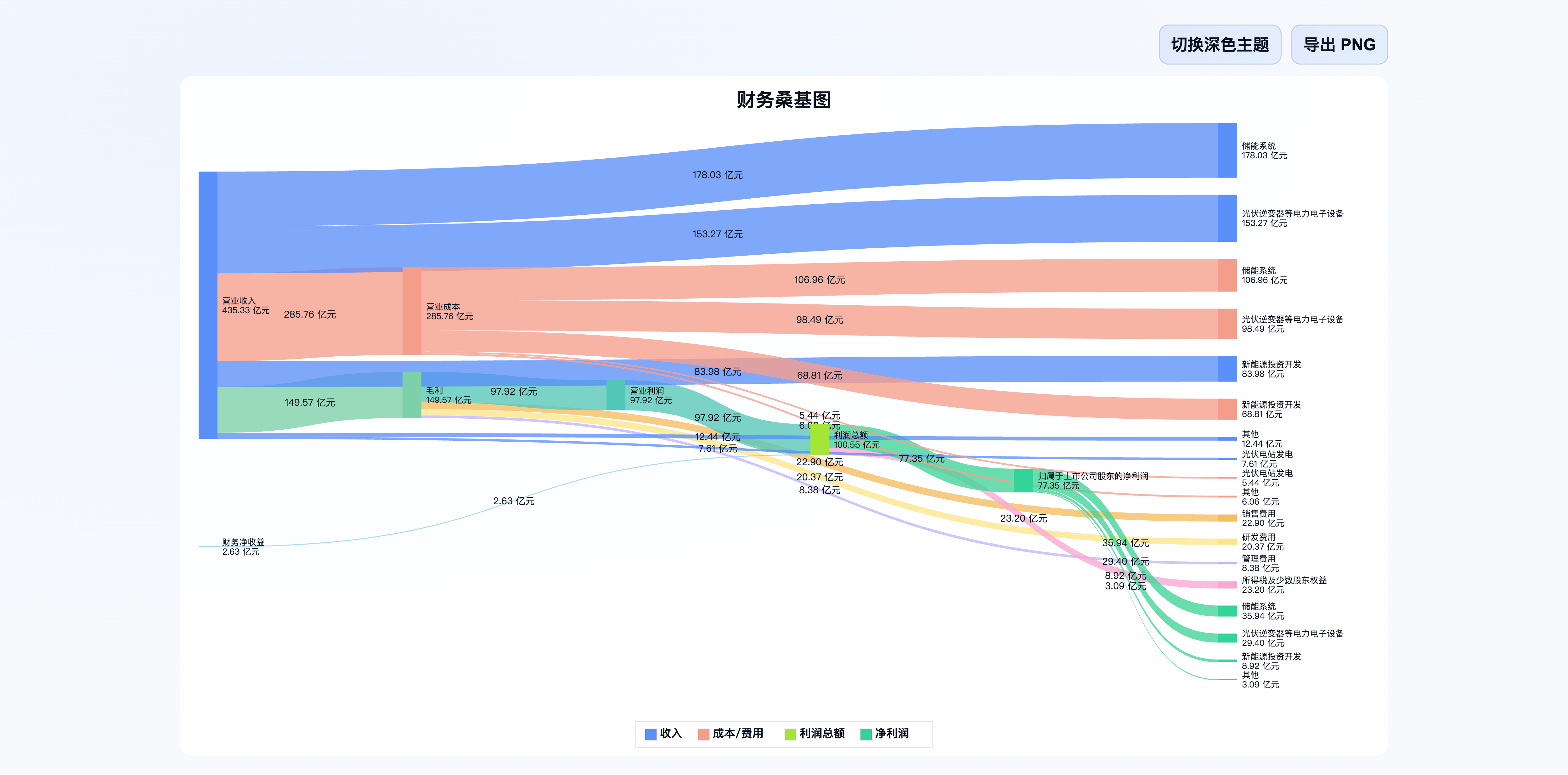
测试一下替换数据的操作。没有问题。你要问,这时候还没有解析PDF呢,哪儿来的Markdown表格财务数据呢?一开始当然要手工去下载半年报PDF,然后手工扔给多个大模型(cherry studio中做测试)。模型要是提炼得不好,那就换一家,继续唠叨呗,一直到输出的财务数据符合你的要求为止。
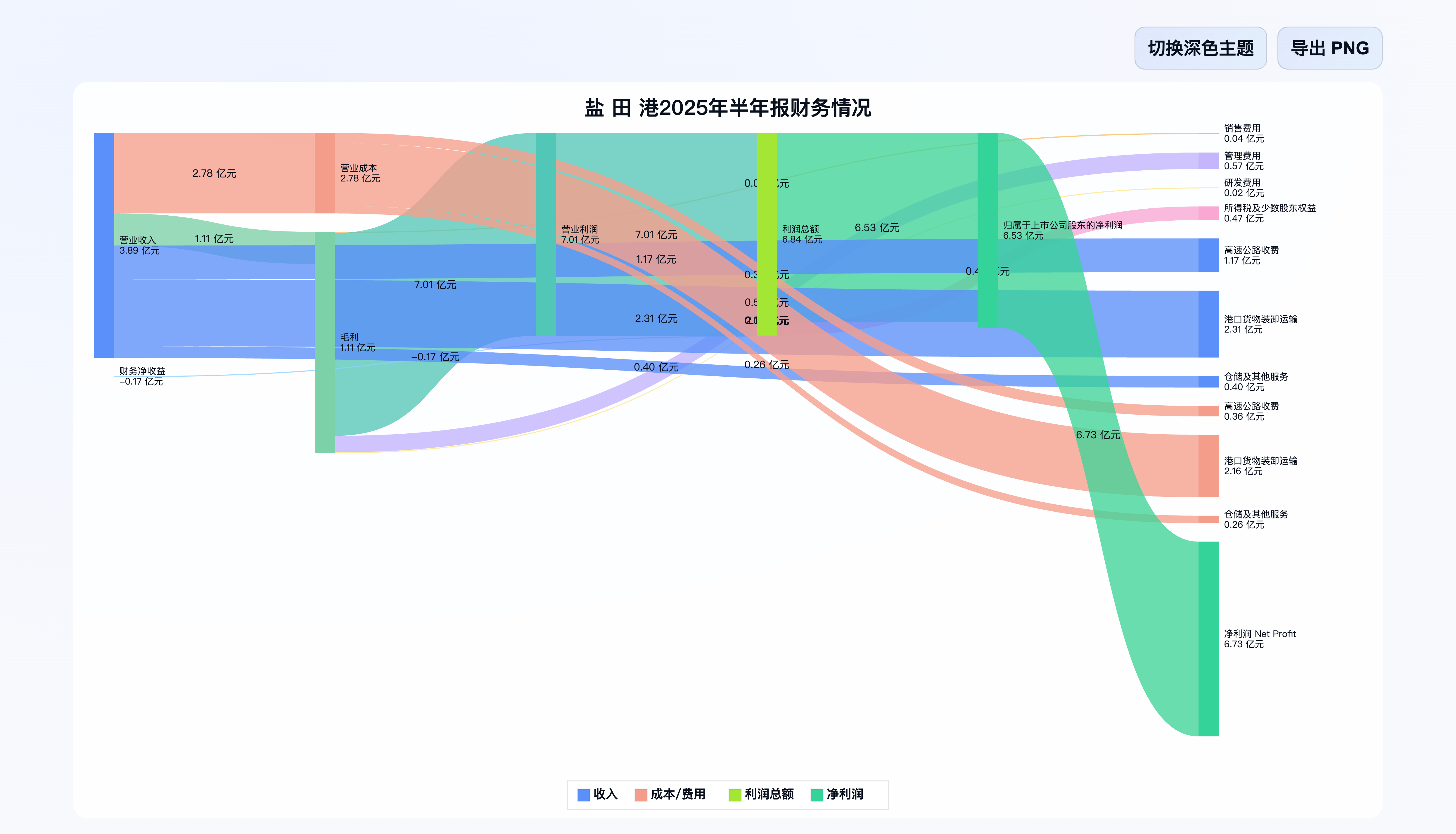
图出来就放心了。开始批量下载半年报。GPT-5自己选的是上交所和深交所的网站,我是没有彻底理解为什么代码中做那么多判断,结果还是发现不少下载的报告与公司对不上,而且把已经退市公司的报告(2024年或者更早的)也收集下来了。在这个阶段,折腾了我不少时间,本来以为是个简单的环节,反而增加了一些工作量,有点郁闷。这就是没有经验使然,总是会碰壁的,或早或晚。后来我让GPT-5重新写了爬虫,直接从新浪财经上下载。遇到退市的字样,就不再采集,很快就搞定了。
开始让大模型解析PDF报告,输出Markdown。这里就需要多些耐心了。比拼人工智能水平的关键环节到了! 因为每家公司的报告并不一样,细分产品线、地域情况等因素,千差万别。一套统一的提示词,背后的大模型都能根据提示词处理不同的PDF文档,那还真是个考验。而且大部分模型的幻觉问题严重,前后两次,甚至多次提炼同一家公司的报告,数据居然有显著不同,这是最让人崩溃的问题。如果数据不准,那可视化又有什么意义呢?
直接说结论吧。我测试下来,Gemini 2.5 Pro,效果最好。不仅可以大概率保证多次提炼的数据一致性,还有一个大优势是便宜:一个API Key每天100次的免费调用额度(Gemini Pro账号)。我也尝试了彻底免费的方案,用本地Ollama支持的模型,真是一塌糊涂。小模型做这样篇幅报告的数据提取,当下肯定是不行了。另外一个技巧,提前将报告用本地的向量化模型处理一下,我用的是Qwen3-Embedding-0.6B。这样似乎能保证让大模型完整地阅读报告,否则如果直接将PDF文档传给大模型,她可能会偷懒只看个摘要。邀请各位读者朋友,继续测试,看看哪家模型更高效、经济实惠。
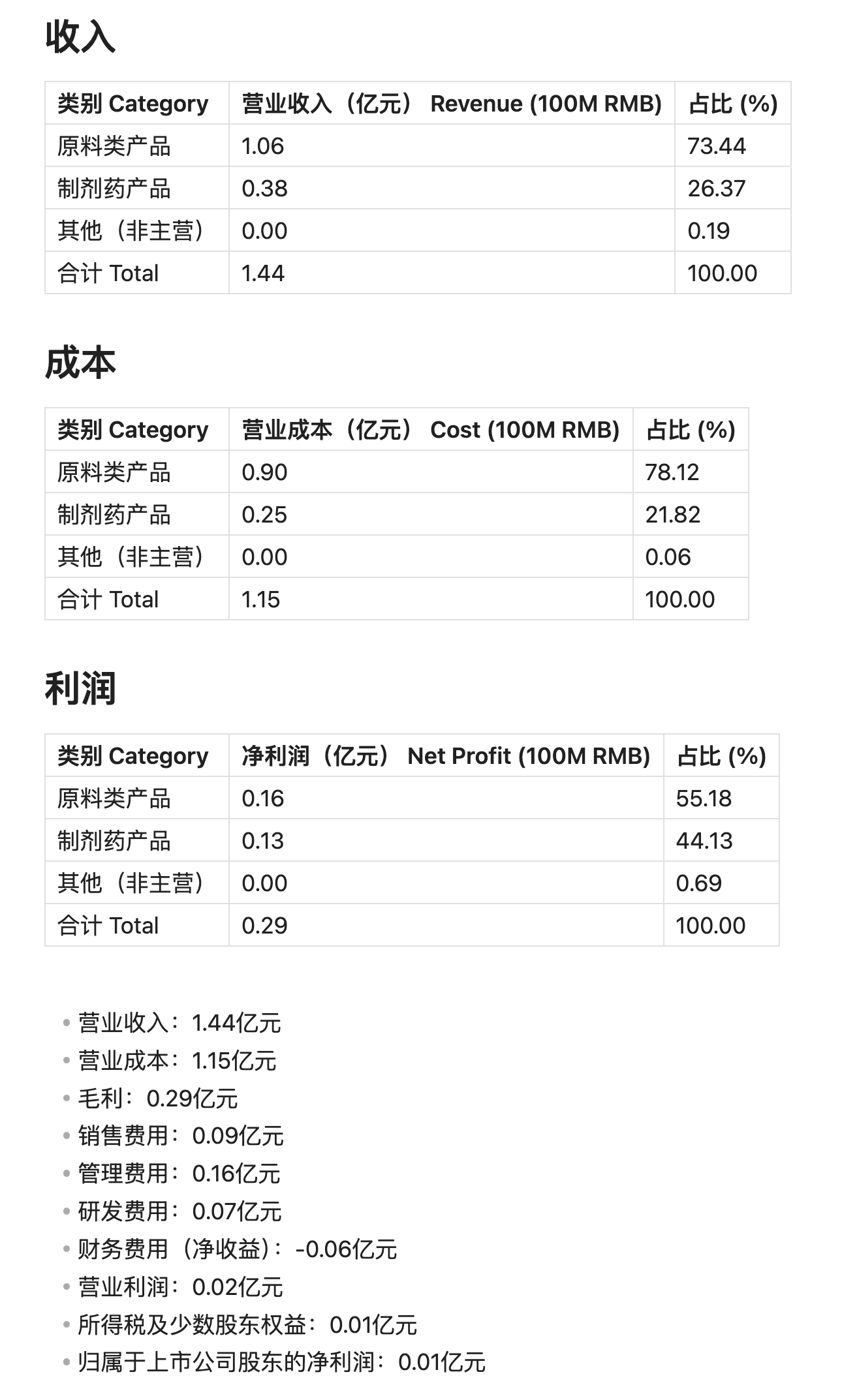
提炼的结果,示例如下,每个报告输出的结果都是这个格式:
300111——向日葵
五、收尾,总结
最后再做个页面,汇总,方便检索,简单列出来所有的股票代码和简称,通过点击进入桑基图页面。因为跑大模型需要些时间,每次刷新页面,会自动检测桑基图是否已准备好。另外还做了模糊搜索,交易所分类等小过滤器。当然这个页面完全都是GPT-5做的,代码我连一眼都没看。
回顾整个过程,最关键的环节就是分解任务,将任务定义到一个大模型写程序不容易出错的粒度。剩下的,就是“说出”你观察到不对的地方,“告诉”她你要得到的结果。持续沟通。
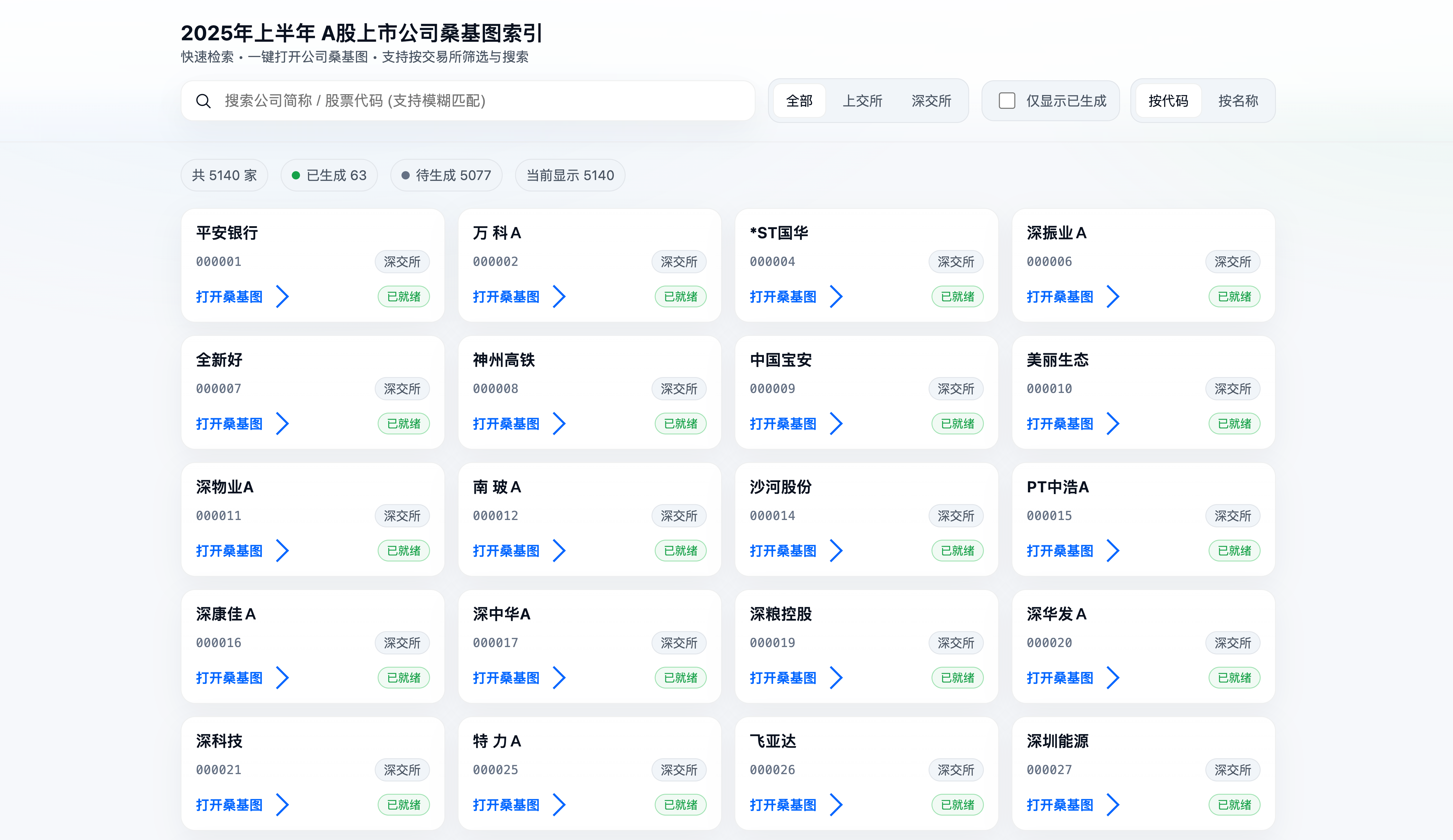
在最终的页面上,随便点几个:
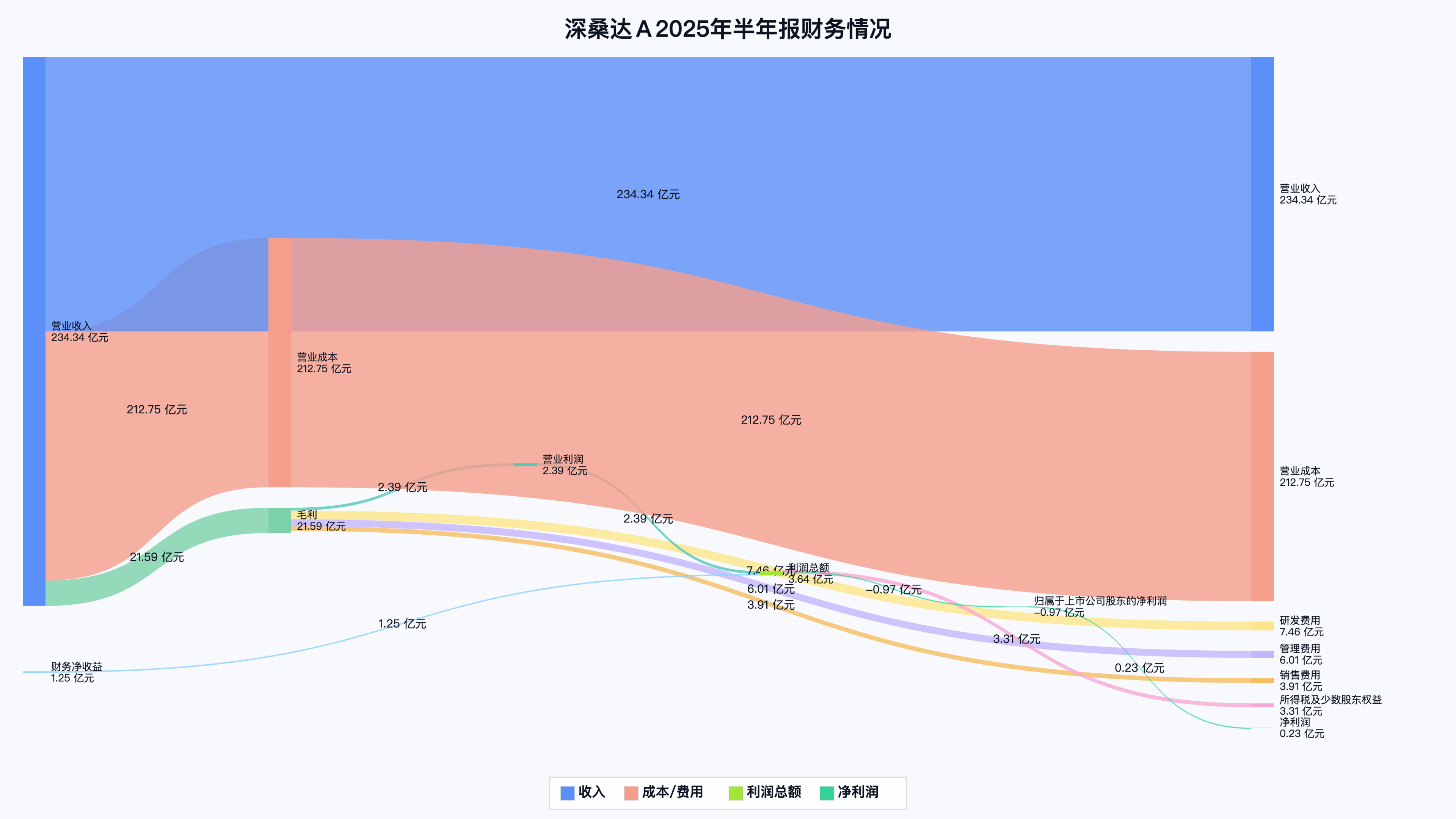
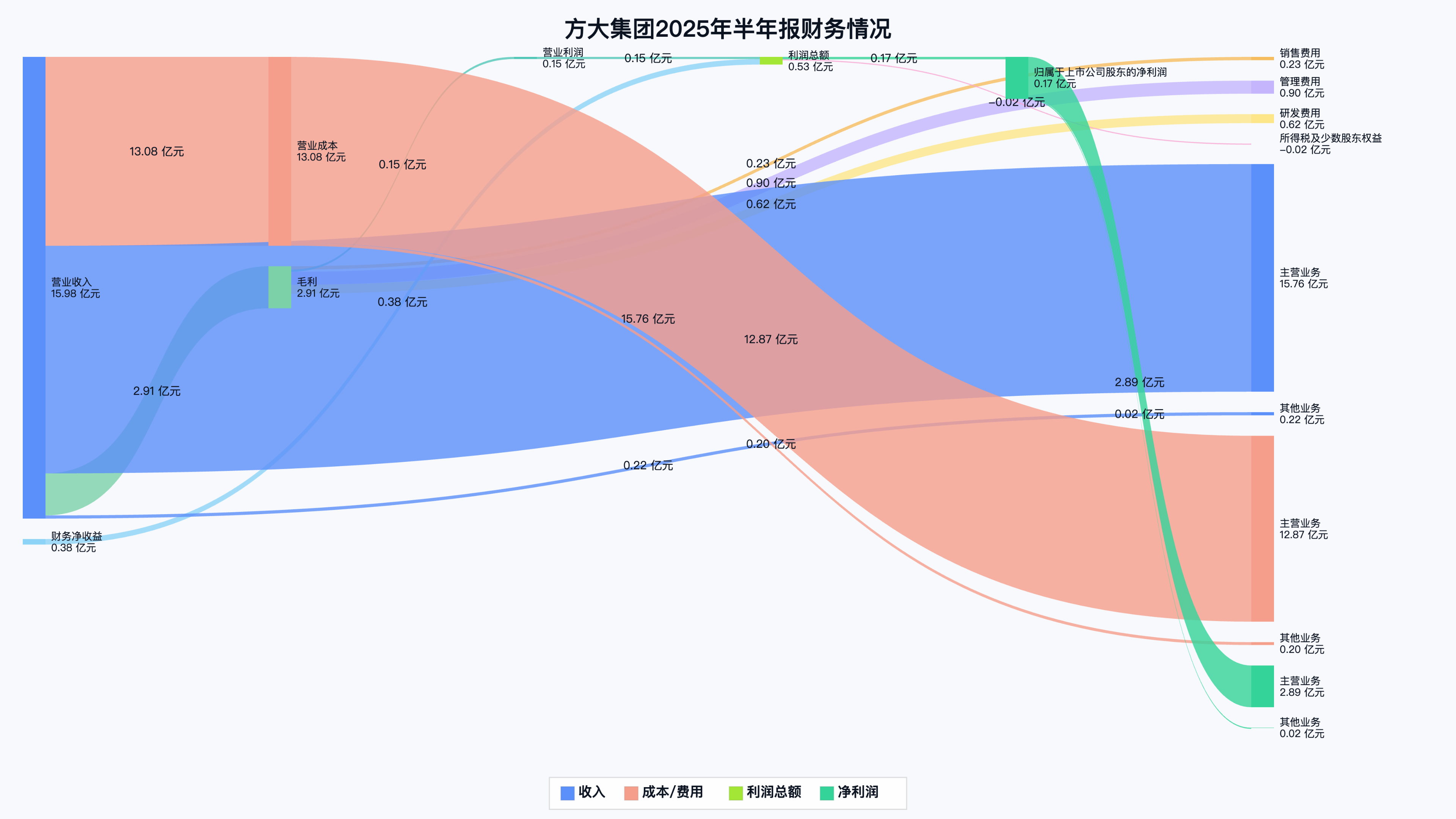
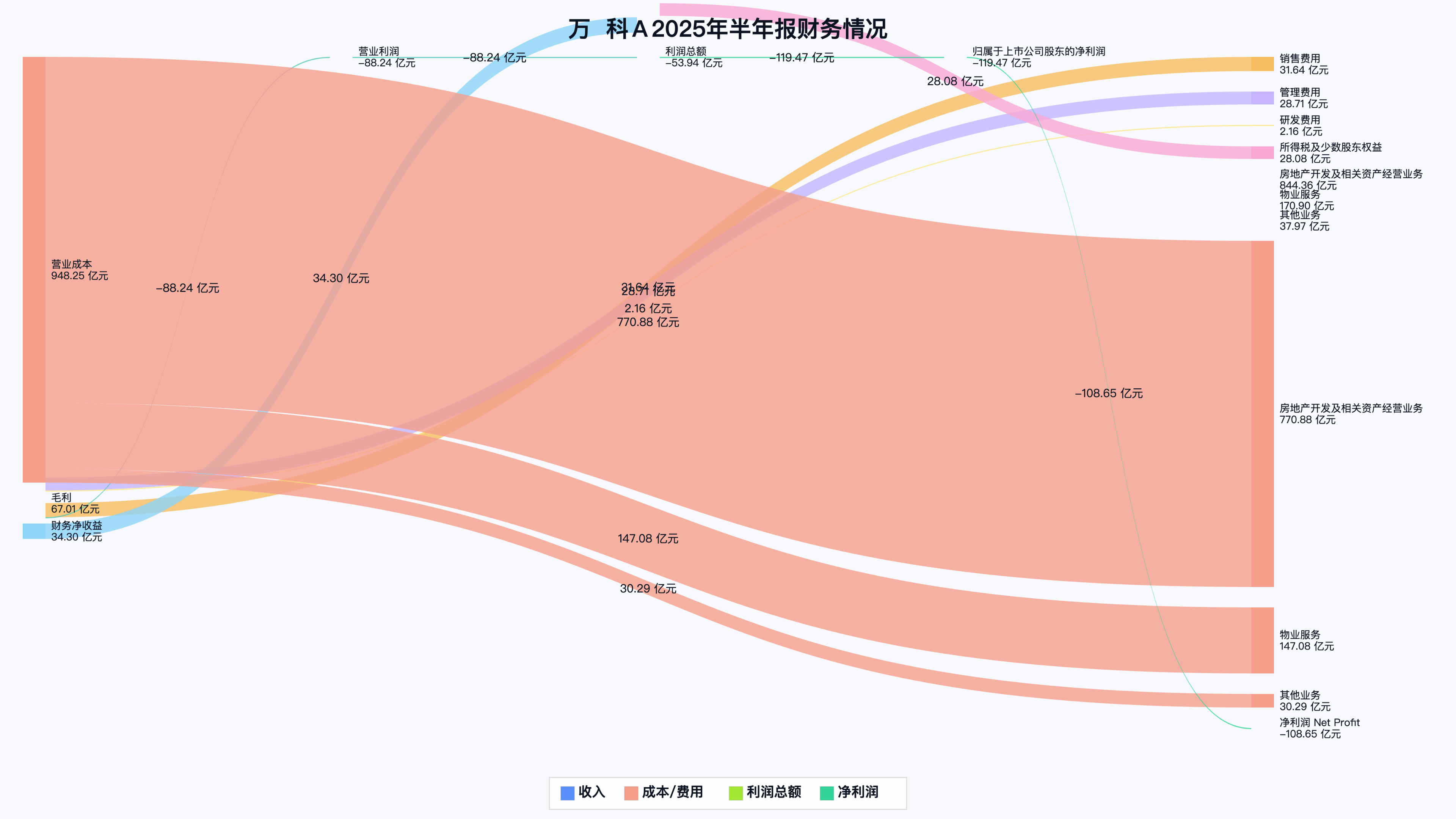
各家的收入、支出、利润还真是一目了然。当然桑基图是个财务数据的总结呈现,并不意味着有了这张图,炒股就轻松了。更多的是,它提供了一个从数据到洞察的视角,以及一次与AI深度协作的实践之旅。
最后还是要回到自我效能感的话题上。如果没有大模型,这样的成果效率,我是不敢想象的。不说程序代码有多复杂,关键是时间耗不起啊。就单单一项:如何从PDF报告中,提炼出精华财务数据,而且是将所有A股上市的5000多家公司都做一遍。什么别的活儿都不干,就这项工作得做多久?可是现在呢?大概大半天的试验、测试,以及主要是和大模型唠嗑沟通,剩下的事儿就是自动执行了。等明年初,年报上线,只需敲下命令,又是一批鲜活的桑基。多让人开心!这个时候,我就会觉得:我没有被这个时代抛弃,还能做点什么有意思的,我可以为这个世界提供些信息增量。 比如,全网还没有一个网站将所有大陆A股上市公司2025年半年报财务数据做成桑基图呢,我做出来,发布了,放在这里:2025h1sankey.kowa88.net
GIS、地图,当然都可以做得更有趣了,甚至比这更有趣,我想象了一堆可以做的大事儿小事儿。最重要的是,这份信手拈来的自我效能感,鼓舞着我,也希望鼓舞着你。你为何不试试呢?