
极海数据分析(下):我们在做什么
如果您看过极海数据分析(上):机器在做什么,您就会知道,本文题目中的“我们”,指的是人类大脑——作为数据分析师的我们。
深度学习技术的惊人发展,似乎让数据分析师变得不重要了——它就像一个自动面包机,面粉、水、糖放进去,程序参数设好,我们坐等收获面包就好了。全麦也行、椰香也行,我们都可以编一个程序来对应。

(图:Emily @flickr)
甚至于,当我们要做更复杂的烘焙,比如说黑森林蛋糕;在技术继续发展的将来,也许机器都能帮我们把奶油打发、巧克力戚风烤好、樱桃汁涂上…… 那么,还需要人类烘焙师做什么呢?
——也许,人类需要 设计 黑森林蛋糕。当蛋糕的配方逐渐多起来,机器都能够排列组合来发明新蛋糕了…… 则人类在吃腻了蛋糕之后,可以设计 蛋挞。设计 芝麻火烧。
我想表达的是,在可预见的未来,即使机器聪明到能用我们无法理解的方式完成任务,我们依然需要帮它 设计梳理明确的任务流程 ——这就是人类的工作。
(图:murray-company)
在上篇《机器在做什么》中,其实有一个trick,就是我们一直在以 预测 作为任务。这个任务是不是很像围棋?规则极简单,用一系列x来预测y;而可能性的空间极大,找到唯一最优答案几乎是不可能的任务。这正是深度学习最擅长的任务。
那接下来我要提出的两个问题——也是我们在项目中会实际面对的问题,就远没有这么简单直接了。
(1)如果我不是单纯预测会员数,而是要分析北京这个城市里,我要开多少家店,每家店在哪里,我能实现最大盈利,该怎么分析?
(2)再抽象一点,就说我现在有500万的资金,要在北京投资1-2套房子,该怎么投资?哪些房子5年后的回报率最高?

于是,带着人类暂时还得以留存的优越感,我来讲讲作为数据分析师,面对这样问题的思路。
a. 开店问题
我们要分析的品牌(属于对距离较为敏感的销售行业),在城市中已开了几家店;其竞争对手暂时还没有进入该市场,但将来有潜在的可能。
于是,我们立刻想到,开店数量从少到多的轴上,可能有这几个阈值(假设k家店理想均匀分布):
- 当店数达到k1,店和店之间的Trade Area交集将无法被忽略,盈利随店数的增长趋势会有一个明显拐点;
- 当店数达到k2(这个值有可能存在,也有可能因其理论值小于k1,而没有太大意义),如果竞争对手想进入市场,他在任意位置开店占领的Trade Area都无法让他盈利;
- 当店数达到k3(有可能大于k2,也有可能小于k2),所有店的总盈利达到最高值,再增加店时,能占领更大的市场,但单纯考量盈利会下降;
- 当店数达到k4,所有店的总盈亏平衡,再增加店时,能占领更大的市场,但会亏本。
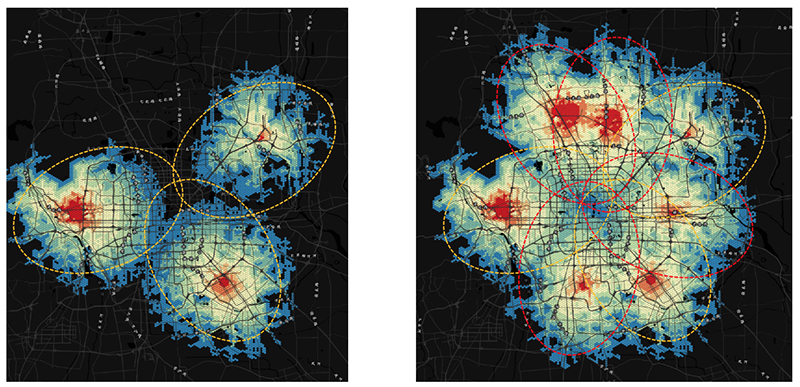
当然,实际市场非常复杂,k家店的理想均匀分布也是个不现实的假设;不过,从复杂的市场中抽象出模型,在简化的过程中不丢失决定性的细节,正是数据分析师的工作。
接下来,在分析了“市场”后,我们就要把它用我们的地理数据进行翻译和解释:
- 营收由会员产生,会员由人口产生,因此营收的基础数据为人口数据(可以简单认为是人口经由一个转化率成为了营收);
- 由于我们所分析的行业对距离较为敏感(可以想象,买车的人不会在乎跑到城市另一头,但买菜的人只会在家门口),人口是否转化为会员,第一级的因素是距离;
- 第二级的因素包括很多,我们既可以用人群属性(年龄、收入、教育程度等),也可以用位置属性(是居住区还是商业区、交通是否方便、是否高档社区等)来进行描绘。
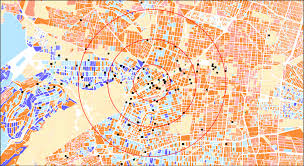
从上到下,理清了层次关系后,我们就可以反过来从下到上,在已有的两家店会员数据基础上一步步进行建模分析了:
- 控制一级的距离变量(例如:将会员到店距离分为若干区间,原则是在保证每个区间会员数能满足样本量要求的情况下尽量细分,然后在个区间内计算,从而实现控制变量),用所有二级的变量预测会员数;
- 完成上述模型后,可得到在每个距离变量区间,当所有二级变量都取平均值时,人口到会员的转化率;其意义是,在一个无区别的(剥除了位置等特性的)环境里,会员和人口的关系是什么;
- 从距离零开始,转化率求积,得到一定人口密度时,随着Trade Area扩大的会员增长曲线;
- 为了简化模型,如果假设每家店的Trade Area内部人口密度基本一致(店和店可能会差异很大),那么在地图上给定任何选址点,和该点附近的人口密度,就有了一个明确的Trade Area半径(可体现为路网距离,也可体现为车行时间等)和会员数之间的函数;
- 此时,大量的二级变量虽然参与到函数的生成过程,但并没有参与到预测的本身,我们依然在预测“无区别的”环境;于是就轮到深度学习出场,用所有二级变量共同预测一个系数,作为对人口到会员转化率的影响因子,加入最终的方程中。
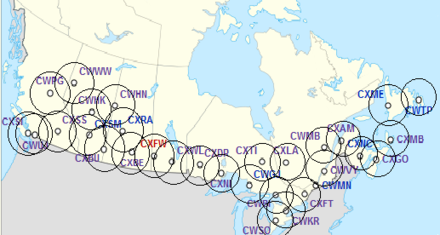
最后,我们就可以回到市场覆盖问题了。我们把城市看做是一个空间格网,掌握了每一点上的基础信息、每一点上的会员数函数;而客户提供给我们他们的成本、盈利计算方法后,我们就可以根据客户需求,计算开头提到的k1、k2、k3、k4,或是某个介于k3和k4之间的选址规划了。这个问题依然复杂,然而不再是人脑层面的(规则上的)复杂,而是到了机器所擅长的(算法实现上的)复杂——就可以交由机器告诉我们最优解是什么。如有需要,再由人的经验认知输入反馈、调整模型,直到得到最终满意的方案。
b. 买房问题
解决了开店问题,我们再尝试把这种思路推广应用。
到了买房投资领域,又引入了一个重要的数据维度——时间维度。我们手中的二手房成交数据,会分散在时间和空间的各个位置;一套房子是在五年前成交的,另一套房子是在三年前成交的。我们很难知道同一个房子的成交价怎样变化,而只有零散分布在时空平面中的,无法连成线的信息。那么该怎样控制变量,找出价格的变化规律?还按照之前的梳理方式:
- 基础变量——价格随时间的变化,这是我们分析对象的本质;
- 一级因素——位置,它是价格变化趋势的决定性影响要素;
- 二级因素——所有其他变量,可以看作是对位置影响的一个附加加成(部分因素会与位置有关联,例如POI类,需要留意)。
(图:Rich Borst)
就像开店问题中,把样本按距离切片;此处我们把所有的房屋交易按时间切片,原则依然是在能满足样本量要求的情况下尽量细分——例如说分到每个季度。则对于每个季度内的房屋交易数据,都进行位置因素的分析:
- 基于所有二级变量,通过位置建模(位置建模的概念可以参考Geographically Weighted Regression这个基于线性回归的建模方法),得到每个交易点上不同的价格预测模型,即:在不同的地理位置,二级变量对价格的影响模型——位置上接近的点,其模型会更相似;
- 当所有二级变量取平均值(去除它们的因素)时,每个交易点得到一个只受位置影响的基值价格;
- 每个基值价格相对于所有基值价格的平均数,就得到了这一点的位置因子。
(图:Rich Borst)
基值价格的直观解释是,如果一个标准普通房子(所有二级指标全都取平均值的房子)在城市的不同位置,它的价格如何;转换成位置因子,我们可以看出这个价格是偏高还是偏低。
在地图上,可以对这个位置因子进行集群,将结果转换为城市里每个区域的价格是偏高还是偏低。对每个季度,都进行一次同样的分析。

(图:Rich Borst)
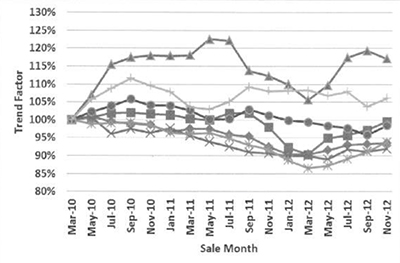
于是,对于城市的各个区域,我们将得到其位置因子随时间的变化折线图。
如果说,这个折线代表了五年期间的价格变化趋势,那么我们可以将它解读为一系列数字:(1)当前的位置因子值;(2)从五年前到当前的价格变化率;(3)当前的价格变化率;(4)价格变化的平稳性;(5)…… 通过这些数字,可以让机器分析告诉我们,房子投资在各个区域,预期的价格走势会如何。
(图:Rich Borst)
而当我们把目光转移到二级变量,我们依然是可以做两件事:
一是在各个区域内通过深度学习进行二级变量的建模,预测价格的走势;当我们有一些潜在可投资的房子,把它们的相关变量输入模型,就可以得到它们的价格走势预期。
二是让传统模型告诉我们,二级变量对价格走势的影响究竟如何——是大户型还是小户型容易升值,板楼还是塔楼容易升值。它的优点是直观,缺点是比较难捕捉各个变量的相互作用(例如可能虽然大户型不易升值,但较新楼盘的顶层的大户型反而升值非常快)。
(图:Rich Borst)
是的,这就是上篇——《机器在做什么》中提到的两个并行的思路:完全交由深度学习去预测,和对各个因子的影响分析。
当然,如果要将这个流程实际操作起来,还会有很多问题:怎样处理二级因素和位置因素的关联性;如果交易数据中包含新房销售,怎样处理它的特殊性;进行时间和空间的分割时,具体采用什么样的方法,等等。但核心依然怎样分层次进行 控制变量—释放变量 这个问题。
这是一个设计问题。事实上,我们平时做的很多看似简单的工作,从将地址数据geocoding,到存储,到检索,再到可视化,都涉及到设计问题。而在数据分析领域,它的意义尤为重大——因为拿到每一个题目都是人类的语言,都需要一个通过人脑处理转换成机器语言,再将结果转换回人类语言的过程。这就是咨询服务的价值。
在将来,通过项目的积累,会逐渐有更多类型化的分析,可以将一个设计方案普适开去;作为数据分析师,我们也很乐见人工智能能做出各种面包,各种蛋糕,越来越少需要我们的输入,走向我们做SAAS的理想。
(图:Kiran Analytics)
而在这个过程中,我们的角色将由 工程师 向 设计师 转换——我们不再需要自己打蛋、融化黄油,而将由各种高科技的电器所武装,得以更加专心地设计我们的配方。而我们团队在几年间积累的大量原材料(涵括各行业的几百类地理数据),则让我们得以进入上层建筑的时期。
对于机器接管计算之势,整个统计学界还在众说纷纭;而于我们这个乐于迎接变化、探索新技术的团队,这则将是一个最美好的时代。